丹摩|丹摩智算平台评测与使用体验
丹摩智算平台(DanoCompute)是一款功能强大的云计算平台,旨在为数据科学家和机器学习工程师提供便捷的计算资源与工具。本文将从平台的使用体验、功能评测,以及实际操作示例三方面进行详细评测,帮助用户更好地理解该平台的潜力与应用。
一、平台概述
丹摩智算平台结合了数据处理、机器学习、深度学习与可视化分析等多种功能,目标是简化数据科学工作的流程。用户可以在没有复杂环境搭建的前提下,利用云端的强大计算资源进行开发与实验。
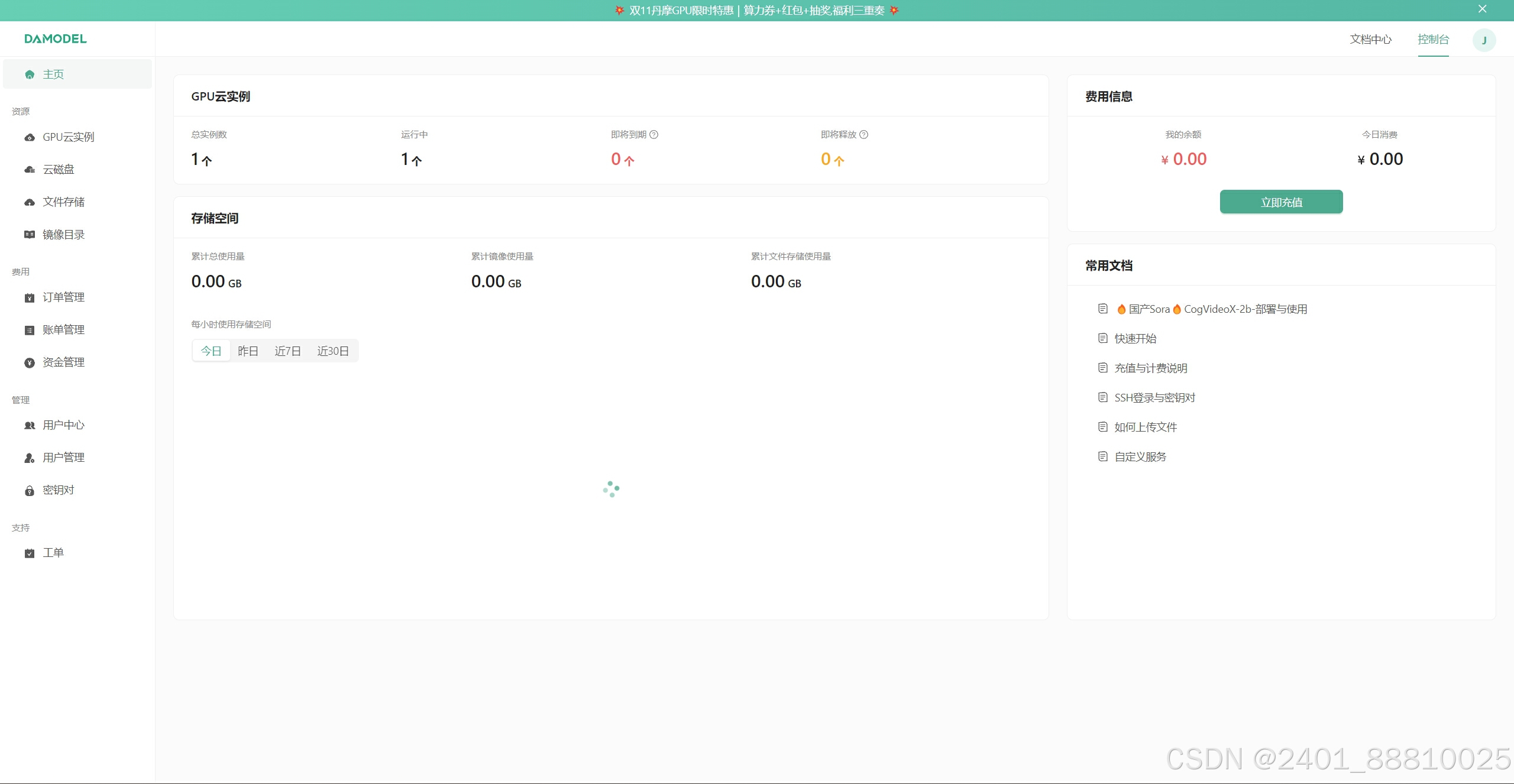
1. 用户界面
平台的用户界面友好且直观,主界面展示了用户的项目、实验和资源使用情况,简化了用户操作流程。以下是平台首页的截图:
二、注册与环境搭建
1. 注册流程
注册非常简单,用户只需填写必要的基本信息并验证邮箱,即可顺利进入平台。登录后,用户可以进入自己的工作空间。
2. 启动项目
用户可以在首页创建新项目,选择不同的模板。丹摩智算平台还提供了多种环境设置,用户可以通过Jupyter Notebook轻松启动数据科学项目。
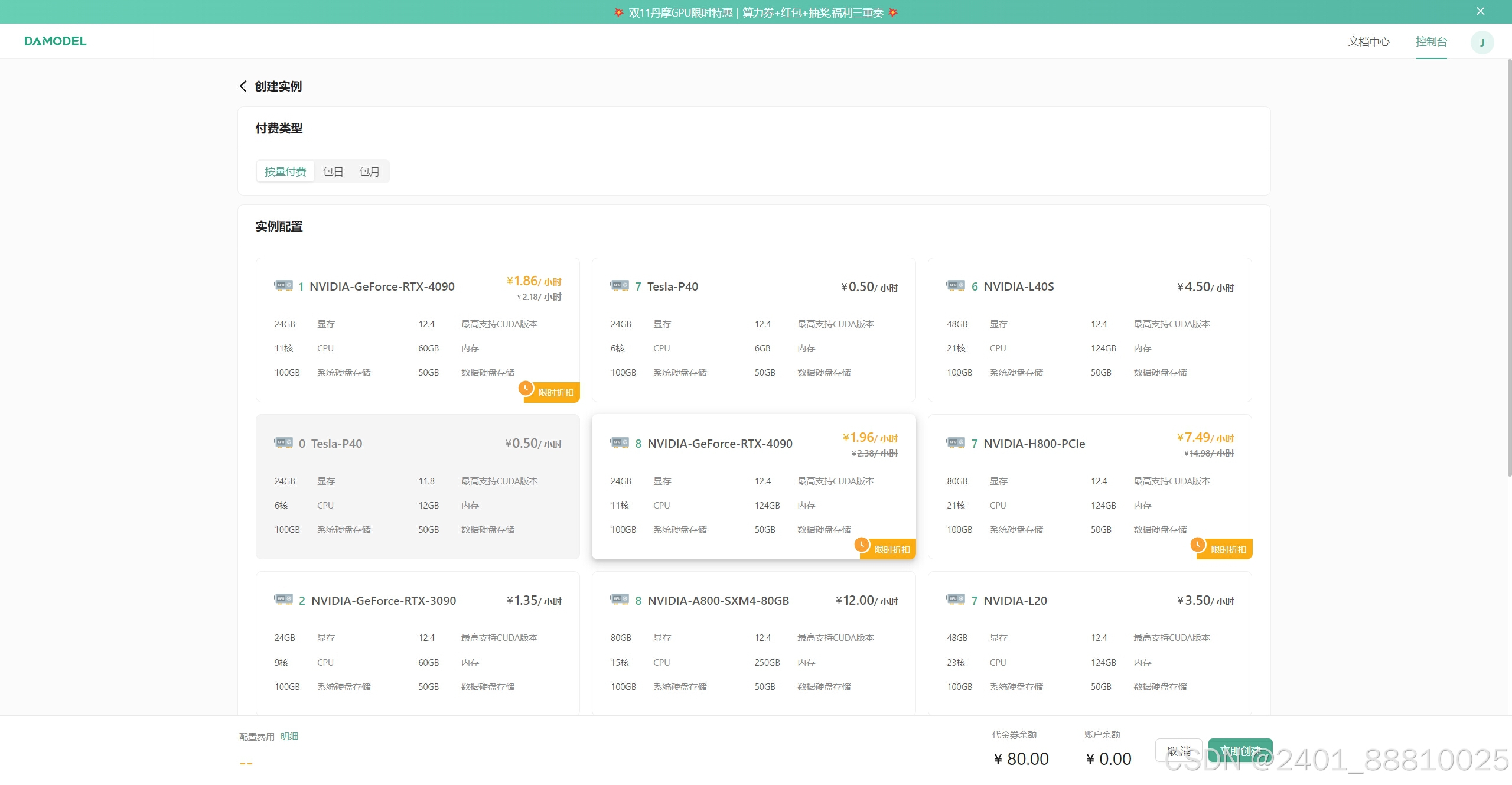
创建项目示例
# 在首页点击“新建项目”并填写项目名称和描述
# 选择“机器学习”模板三、功能评测
1. 数据处理与可视化
导入数据
用户可以轻松导入本地数据,支持CSV、Excel等多种格式。以下是加载鸢尾花数据集的示例:
import pandas as pd
# 加载鸢尾花数据集
df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data', header=None)
df.columns = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species']
# 查看数据
print(df.head())数据加载后的示例输出:
sepal_length sepal_width petal_length petal_width species
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2 Iris-setosa2. 数据可视化
使用Matplotlib和Seaborn库进行数据可视化也是十分简单的,下面是一个绘制散点图的示例:
import seaborn as sns
import matplotlib.pyplot as plt
# 绘制散点图
plt.figure(figsize=(10, 6))
sns.scatterplot(data=df, x='sepal_length', y='sepal_width', hue='species', style='species', s=100)
plt.title('Iris Flower Dataset - Scatter Plot')
plt.xlabel('Sepal Length')
plt.ylabel('Sepal Width')
plt.legend(title='Species')
plt.grid()
plt.show()生成的图表如下所示:
3. 机器学习模型训练
丹摩智算平台支持多种机器学习模型的训练,包括常见的回归和分类算法。以下是使用随机森林分类器进行鸢尾花分类的示例:
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report
# 划分特征和目标
X = df.drop('species', axis=1)
y = df['species']
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化随机森林模型
model = RandomForestClassifier(n_estimators=100, random_state=42)
# 训练模型
model.fit(X_train, y_train)
# 进行预测
y_pred = model.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
report = classification_report(y_test, y_pred)
print(f'模型准确率: {accuracy:.2f}')
print(report)输出示例:
模型准确率: 1.00
precision recall f1-score support
setosa 1.00 1.00 1.00 10
versicolor 1.00 1.00 1.00 10
virginica 1.00 1.00 1.00 10
accuracy 1.00 30
macro avg 1.00 1.00 1.00 30
weighted avg 1.00 1.00 1.00 304. 模型保存和分享
平台提供优秀的模型保存和分享功能,用户可以将训练好的模型保存到云端,并生成分享链接,便于与团队成员合作。
# 保存模型
import joblib
joblib.dump(model, 'iris_random_forest_model.pkl')四、使用体验
1. 性能与资源
在使用过程中,丹摩智算平台提供的计算资源表现优秀。GPU加速功能在模型训练期间显著缩短了计算时间,非常适合处理大规模数据和复杂模型。
2. 社区与支持
平台内嵌的社区功能,使得用户可以与其他数据科学工作者共享经验与想法,这点尤为重要。平台的客服支持也及时有效,能迅速解决用户在操作过程中遇到的问题。
3. 总体评价
综合考虑功能、性能和用户体验,丹摩智算平台是一款强大的数据科学工具。其友好的用户界面和丰富的功能模块,能够有效支持数据分析、可视化以及机器学习项目,为用户提供了极大的便利。
五、总结
通过本次评测,我们深入体验了丹摩智算平台的强大功能,尤其是在数据处理、可视化与机器学习模型训练方面的优势。若您正寻求一款高效的云计算平台来开展数据科学项目,丹摩智算平台无疑是非常值得尝试的选择。
您的反馈与讨论是推动我们不断改进的重要动力,欢迎您在平台内外分享您的体验与想法!

尧米是由西云算力与CSDN联合运营的AI算力和模型开源社区品牌,为基于DaModel智算平台的AI应用企业和泛AI开发者提供技术交流与成果转化平台。
更多推荐



 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)