基于 DAMODEL 的 ChatGLM-6B 部署与 API 调用教程
ChatGLM-6B 是由清华大学和智谱 AI 开发的一款对话模型,基于 GLM 架构,拥有 62 亿参数,支持中英文对话。DAMODEL 提供了在云平台上部署该模型的详细指南。用户首先通过 DAMODEL 云平台创建 GPU 实例,配置硬件和环境,然后克隆 ChatGLM-6B 项目并安装依赖。模型可以通过命令行或网页接口与用户进行交互。此外,DAMODEL 支持通过 API 本地调用模型,帮助
文章目录
📑前言
ChatGLM-6B 是由清华大学和智谱 AI 开发的一款对话模型,基于 GLM 架构,拥有 62 亿参数,支持中英文对话。DAMODEL 提供了在云平台上部署该模型的详细指南。用户首先通过 DAMODEL 云平台创建 GPU 实例,配置硬件和环境,然后克隆 ChatGLM-6B 项目并安装依赖。模型可以通过命令行或网页接口与用户进行交互。此外,DAMODEL 支持通过 API 本地调用模型,帮助用户实现对话系统的部署和使用。
一、ChatGLM-6B 模型概述
ChatGLM-6B 是一款轻量级的对话模型,旨在支持高效的多轮对话生成。与传统的大规模语言模型相比,ChatGLM-6B 采用了更加轻量的参数设计,仅用 62 亿参数即可实现对话生成,适合资源有限的环境。此外,ChatGLM-6B 支持中英文对话,是中文自然语言处理领域的一个重要工具。
该模型基于 General Language Model(GLM)架构,采用了 Transformer 结构进行构建。与 GPT 类模型不同的是,GLM 支持填空任务,因此可以处理包含遮蔽的输入文本,更好地适应实际对话场景。
ChatGLM-6B 在学术界和工业界获得了广泛应用,主要用于对话生成、问答系统、文本摘要等任务。
二、DAMODEL 云平台部署 ChatGLM-6B
DAMODEL 提供了简便的 ChatGLM-6B 部署方法,使用户能够快速利用云计算资源进行大规模对话模型的训练和测试。以下是如何在 DAMODEL 云平台上部署 ChatGLM-6B 的详细步骤:
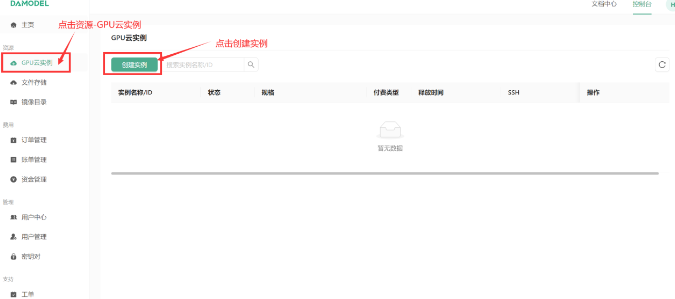
2.1 创建 GPU 实例
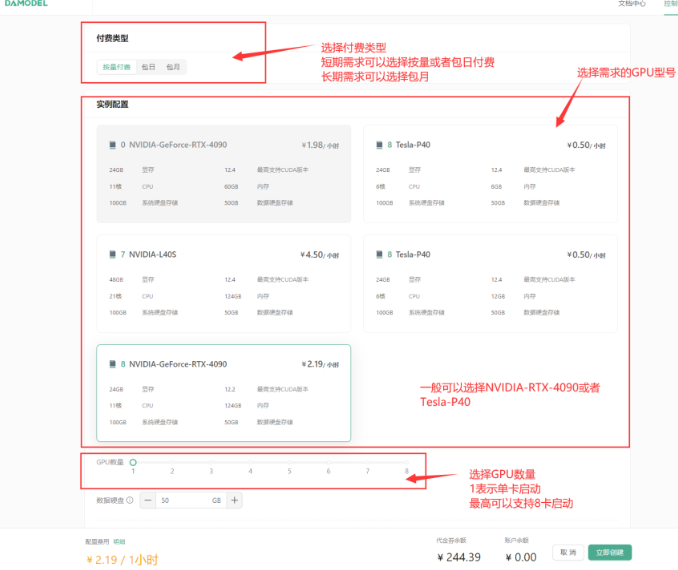
首先,用户需要登录 DAMODEL 控制台,选择 GPU 云实例并创建实例。在实例创建页面,选择按量付费的配置模式,通常选用 NVIDIA GeForce RTX 4090,这一配置拥有 24GB 显存和 60GB 内存,能够满足 ChatGLM-6B 的运行需求。
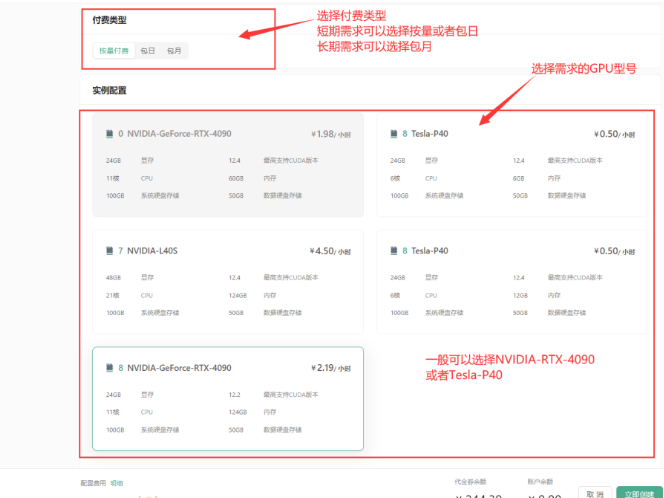
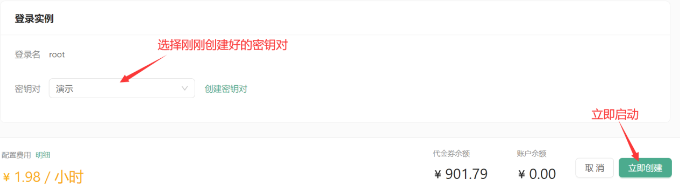
选择好实例后,用户还需配置数据硬盘的大小,默认情况下为 50GB,足够支持大部分模型的存储和运行。随后,选择 PyTorch 环境来支持模型的训练与推理,用户可以选择 PyTorch1.13.1 或者 PyTorch2.1.2 版本进行模型的训练和推理。
2.2 模型下载与依赖安装
cd /home/aistudio/work/
git clone https://github.com/THUDM/ChatGLM-6B.git
# 如果遇见github因为网络问题导致失败,可选择gitcode站点进行下载
# git clone https://gitcode.com/applib/ChatGLM-6B.git
GPU 实例启动后,用户通过终端克隆 ChatGLM-6B 的 GitHub 项目,并通过 pip 安装所需的依赖。DAMODEL 平台提供了高效的网络连接,依赖安装速度极快。依赖安装成功后,用户需要从 Hugging Face 或其他提供模型文件的社区下载 ChatGLM-6B 的预训练模型,并将其上传到云实例的文件存储中。
pip install -r requirements.txt
DAMODEL 提供 20GB 免费存储空间,用户可以将模型文件上传并跨实例共享,便于模型的部署与使用。
2.3 启动 ChatGLM-6B 模型
ChatGLM-6B 提供了 cli_demo.py 和 web_demo.py 两个脚本,用户可以通过命令行或者 Web 界面与模型进行交互。启动模型前,用户需要将加载路径从 Hugging Face Hub 改为本地文件路径,以确保模型从本地加载而不是通过网络下载。
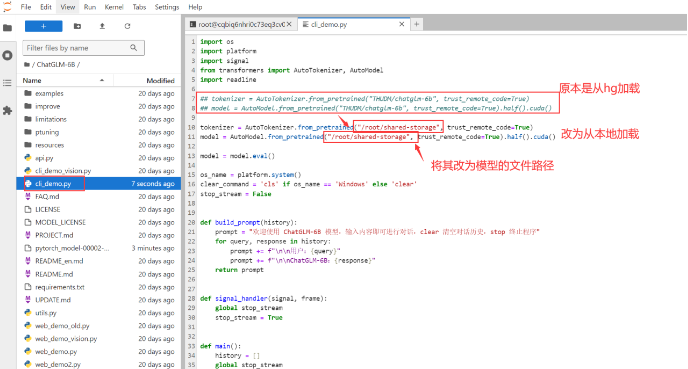
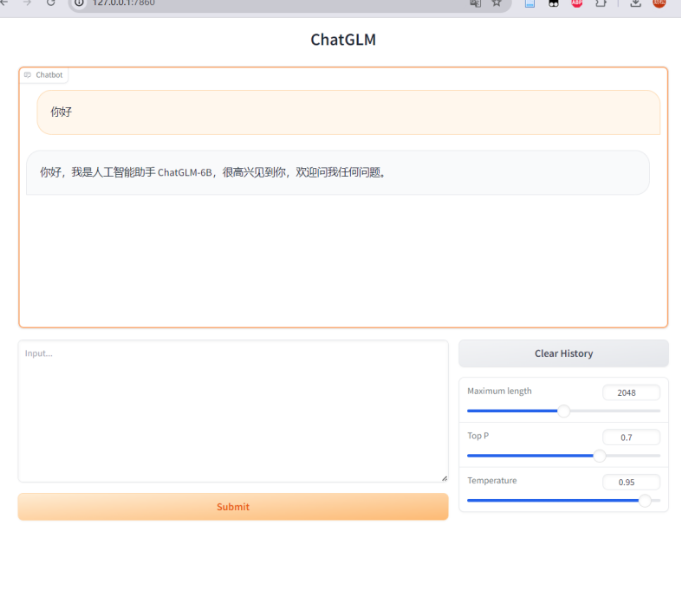
在命令行中执行 python cli_demo.py 或 python web_demo.py 之后,模型会进入等待状态,用户可以输入文本与其对话,体验模型的生成能力。
三、通过 Web API 实现本地调用
除了在云平台上直接与 ChatGLM-6B 模型交互,用户还可以通过 Web API 将模型部署为服务端应用,在本地通过 HTTP 请求与模型进行交互。以下是使用 API 的详细步骤:
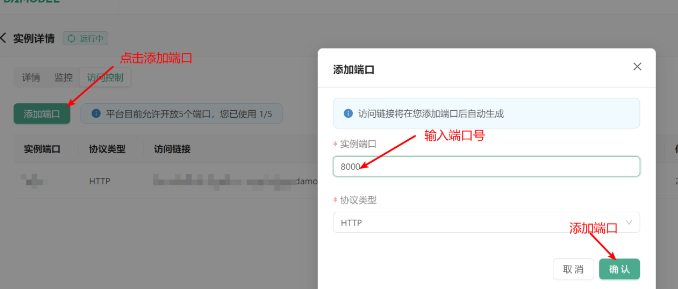
3.1 启动 API 服务
ChatGLM-6B 提供了基于 FastAPI 的 api.py 文件,用户可以通过运行该文件启动 API 服务。API 接收 POST 请求,并根据用户输入的 prompt 和历史对话记录生成回复文本。API 服务启动后,用户可以通过 Postman 或其他 HTTP 客户端测试服务端是否工作正常。
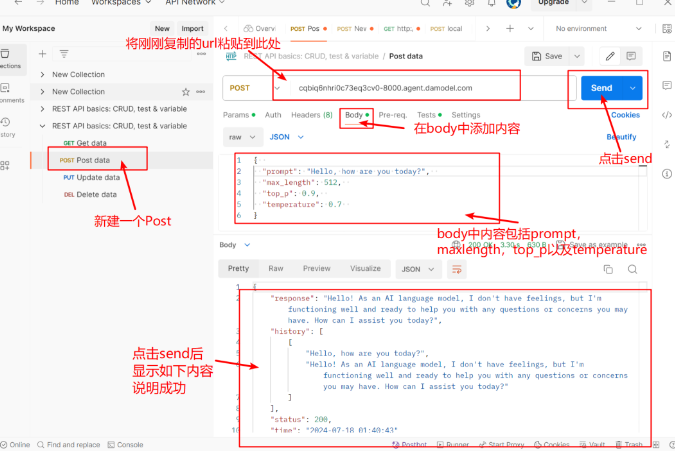
3.2 本地调用 API 服务
用户可以在本地编写简单的 Python 脚本,通过向 API 发送 POST 请求与 ChatGLM-6B 进行交互。请求体需要包含 prompt、生成文本的最大长度 max_length、top_p 和 temperature 等参数。API 接收到请求后,会返回生成的文本以及更新后的对话历史,方便用户实现多轮对话。
以下是本地调用 API 的示例代码:
import requests
api_url = "http://your-api-url"
data = {
"prompt": "你好,你是谁?",
"max_length": 512,
"top_p": 0.9,
"temperature": 0.7
}
response = requests.post(api_url, json=data)
if response.status_code == 200:
result = response.json()
print("Response:", result['response'])
else:
print("API 调用失败,状态码:", response.status_code)
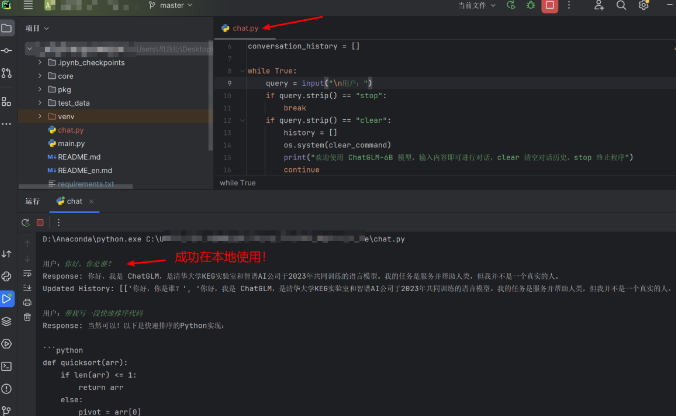
通过这种方式,用户可以在本地开发对话应用,将 ChatGLM-6B 部署为一个高效的对话系统。
四、总结
ChatGLM-6B 作为一款开源的中英文对话模型,具有轻量级和高效的特点。通过 DAMODEL 云平台,用户可以快速部署和使用该模型,享受高性能 GPU 计算资源的支持。此外,ChatGLM-6B 提供了便捷的 API 接口,便于用户将其集成到本地或其他系统中,广泛应用于对话系统、智能客服、语言生成等场景。
在未来,随着 ChatGLM 相关技术的进一步发展,更多应用场景和优化方法将不断涌现,推动自然语言处理技术的进步。

尧米是由西云算力与CSDN联合运营的AI算力和模型开源社区品牌,为基于DaModel智算平台的AI应用企业和泛AI开发者提供技术交流与成果转化平台。
更多推荐



 21
21 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)