LLM 大模型学习必知必会系列(六):VLLM性能飞跃部署实践:从推理加速到高效部署的全方位优化
do_sample:布尔类型。是否使用随机采样方式运行推理,如果设置为False,则使用beam_search方式temperature:大于等于零的浮点数。qifracexpziTsumjexpzjTqifracexpziTsumjexpzjT从公式可以看出,如果T取值为0,则效果类似argmax,此时推理几乎没有随机性;取值为正无穷时接近于取平均。一般temperature取值介于[0, 1]
引言
训练后的模型会用于推理或者部署。推理即使用模型用输入获得输出的过程,部署是将模型发布到恒定运行的环境中推理的过程。一般来说,LLM的推理可以直接使用PyTorch代码、使用VLLM/XInference/FastChat等框架,也可以使用llama.cpp/chatglm.cpp/qwen.cpp等c++推理框架。
- 常见推理方法
- Greedy Search 贪婪搜索方式。按照前面的讲解,模型会按照词表尺寸生成概率。贪婪方式会不断选择生成概率最大的token。该方法由于无脑选择了最大概率,因此模型会倾向于生成重复的文字,一般实际应用中很少使用
- Beam Search 和贪婪方式的区别在于,beam search会选择概率最大的k个。在生成下一个token时,每个前序token都会生成k个,这样整体序列就有k^2个,从这些序列中选择组合概率最大的k个,并递归地执行下去。k在beam search算法中被称为beam_size
- Sample 随机采样方式。按照词表每个token的概率采样一个token出来。这个方式多样性更强,是目前主流的生成方式。
1. 前言
1.1 重要推理超参数
-
do_sample:布尔类型。是否使用随机采样方式运行推理,如果设置为False,则使用beam_search方式
-
temperature:大于等于零的浮点数。公式为:
q _ i = f r a c e x p ( z _ i / T ) s u m _ j e x p ( z _ j / T ) q\_i=\\frac{\\exp(z\_i/T)}{\\sum\_{j}\\exp(z\_j/T)}\\ q_i=fracexp(z_i/T)sum_jexp(z_j/T)
从公式可以看出,如果T取值为0,则效果类似argmax,此时推理几乎没有随机性;取值为正无穷时接近于取平均。一般temperature取值介于[0, 1]之间。取值越高输出效果越随机。
如果该问答只存在确定性答案,则T值设置为0。反之设置为大于0。
-
top_k:大于0的正整数。从k个概率最大的结果中进行采样。k越大多样性越强,越小确定性越强。一般设置为20~100之间。
- 实际实验中可以先从100开始尝试,逐步降低top_k直到效果达到最佳。
-
top_p:大于0的浮点数。使所有被考虑的结果的概率和大于p值,p值越大多样性越强,越小确定性越强。一般设置0.7~0.95之间。
- 实际实验中可以先从0.95开始降低,直到效果达到最佳。
- top_p比top_k更有效,应优先调节这个参数。
-
repetition_penalty: 大于等于1.0的浮点数。如何惩罚重复token,默认1.0代表没有惩罚。
1.2 KVCache
上面我们讲过,自回归模型的推理是将新的token不断填入序列生成下一个token的过程。那么,前面token已经生成的中间计算结果是可以直接利用的。具体以Attention结构来说:
t e x t A t t e n t i o n ( Q , K , V ) = o p e r a t o r n a m e s o f t m a x l e f t ( f r a c Q K T s q r t d _ k r i g h t ) V \\text { Attention }(Q, K, V)=\\operatorname{softmax}\\left(\\frac{Q K^T}{\\sqrt{d\_k}}\\right) V textAttention(Q,K,V)=operatornamesoftmaxleft(fracQKTsqrtd_kright)V
推理时的Q是单token tensor,但K和V都是包含了所有历史token tensor的长序列,因此KV是可以使用前序计算的中间结果的,这部分的缓存就是KVCache,其显存占用非常巨大。
2. VLLM框架
网址: https://github.com/vllm-project/vllm
vLLM是一个开源的大模型推理加速框架,通过PagedAttention高效地管理attention中缓存的张量,实现了比HuggingFace Transformers高14-24倍的吞吐量。
PagedAttention 是 vLLM 的核心技术,它解决了LLM服务中内存的瓶颈问题。传统的注意力算法在自回归解码过程中,需要将所有输入Token的注意力键和值张量存储在GPU内存中,以生成下一个Token。这些缓存的键和值张量通常被称为KV缓存。
- 主要特性
- 通过PagedAttention对 KV Cache 的有效管理
- 传入请求的continus batching,而不是static batching
- 支持张量并行推理
- 支持流式输出
- 兼容 OpenAI 的接口服务
- 与 HuggingFace 模型无缝集成
VLLM支持绝大多数LLM模型的推理加速。它使用如下的方案大幅提升推理速度:
-
Continuous batching
-
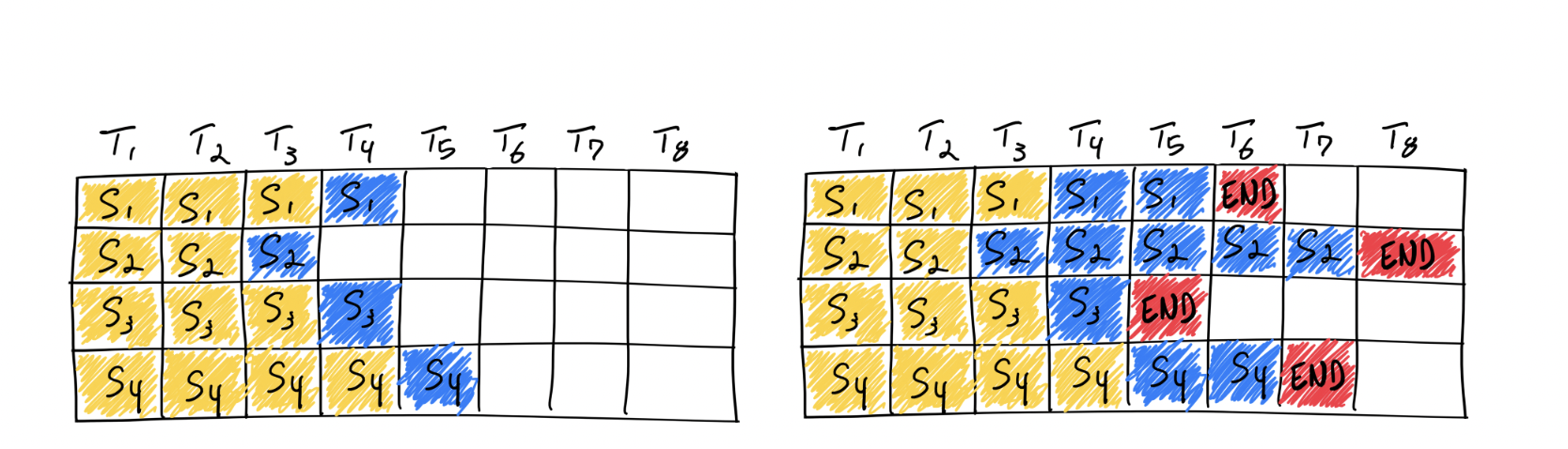
在实际推理过程中,一个批次多个句子的输入的token长度可能相差很大,最后生成的模型输出token长度相差也很大。在python朴素推理中,最短的序列会等待最长序列生成完成后一并返回,这意味着本来可以处理更多token的GPU算力在对齐过程中产生了浪费。continous batching的方式就是在每个句子序列输出结束后马上填充下一个句子的token,做到高效利用算力。


-
-
PagedAttention
- 推理时的显存占用中,KVCache的碎片化和重复记录浪费了50%以上的显存。VLLM将现有输入token进行物理分块,使每块显存内部包含了固定长度的tokens。在进行Attention操作时,VLLM会从物理块中取出KVCache并计算。因此模型看到的逻辑块是连续的,但是物理块的地址可能并不连续。这和虚拟内存的思想非常相似。另外对于同一个句子生成多个回答的情况,VLLM会将不同的逻辑块映射为一个物理块,起到节省显存提高吞吐的作用。


值得注意的是,VLLM会默认将显卡的全部显存预先申请以提高缓存大小和推理速度,用户可以通过参数gpu_memory_utilization控制缓存大小。
首先安装VLLM:
pip install vllm
import os
os.environ['VLLM_USE_MODELSCOPE'] = 'True'
from vllm import LLM, SamplingParams
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="qwen/Qwen-1_8B", trust_remote_code=True)
outputs = llm.generate(prompts, sampling_params)
#Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
注意,截止到本文档编写完成,VLLM对Chat模型的推理支持(模板和结束符)存在问题,在实际进行部署时请考虑使用SWIFT或者FastChat。
LLM的generate方法支持直接输入拼接好的tokens(prompt_token_ids参数,此时不要传入prompts参数),所以外部可以按照自己的模板进行拼接后传入VLLM,SWIFT就是使用了这种方法
在量化章节中我们讲解了AWQ量化,VLLM直接支持传入量化后的模型进行推理:
from vllm import LLM, SamplingParams
import os
import torch
os.environ['VLLM_USE_MODELSCOPE'] = 'True'
#Sample prompts.
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
#Create a sampling params object.
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
#Create an LLM.
llm = LLM(model="ticoAg/Qwen-1_8B-Chat-Int4-awq", quantization="AWQ", dtype=torch.float16, trust_remote_code=True)
#Generate texts from the prompts. The output is a list of RequestOutput objects
#that contain the prompt, generated text, and other information.
outputs = llm.generate(prompts, sampling_params)
#Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
VLLM官方文档可以查看这里。
3.SWIFT
网址:https://github.com/modelscope/swift/tree/main
SWIFT(Scalable lightWeight Infrastructure for Fine-Tuning)是基于PyTorch的轻量级、开箱即用的模型微调、推理框架。它不仅集成了各类开源tuners,如LoRA、QLoRA、Adapter等,并且融合了ModelScope独立自研的特有tuner ResTuning,得益于此,各个模态的开发者均可以找到适合自己模型的开发方式。
SWIFT的tuners不仅适配于所有Transformer结构的模型,也适配于其他结构的深度学习模型,做到一行代码创建可微调模型,实现参数高效、内存高效和时间高效的训练流程。
SWIFT可以无缝集成到ModelScope生态系统中,打通数据集读取、模型下载、模型训练、模型推理、模型上传等流程。此外,SWIFT与PEFT完全兼容, 熟悉PEFT的用户可以使用SWIFT能力结合ModelScope的模型进行便捷地训练推理。
作为ModelScope独立自研的开源轻量级tuner ResTuning,该技术在cv、多模态等领域均经过了系列验证,在训练效果和其他微调方法相当的情况下,可以做到显存节省30%~60%,为cv、多模态模型的训练提供了新的范式,在未来会应用在越来越多的场景上。
- SWIFT 框架主要特征特性:
- 具备SOTA特性的Efficient Tuners:用于结合大模型实现轻量级(在商业级显卡上,如RTX3080、RTX3090、RTX4090等)训练和推理,并取得较好效果
- 使用ModelScope Hub的Trainer:基于transformers trainer提供,支持LLM模型的训练,并支持将训练后的模型上传到ModelScope Hub中
- 可运行的模型Examples:针对热门大模型提供的训练脚本和推理脚本,并针对热门开源数据集提供了预处理逻辑,可直接运行使用
- 支持界面化训练和推理

在SWIFT中,我们支持了VLLM的推理加速手段。
pip install ms-swift[llm] openai
只需要运行下面的命令就可以使用VLLM加速推理:
swift infer --model_id_or_path qwen/Qwen-1_8B-Chat --max_new_tokens 128 --temperature 0.3 --top_p 0.7 --repetition_penalty 1.05 --do_sample true
也支持在部署中使用VLLM:
swift deploy --model_id_or_path qwen/Qwen-1_8B-Chat --max_new_tokens 128 --temperature 0.3 --top_p 0.7 --repetition_penalty 1.05 --do_sample true
调用:
from openai import OpenAI
client = OpenAI(
api_key='EMPTY',
base_url='http://localhost:8000/v1',
)
model_type = client.models.list().data[0].id
print(f'model_type: {model_type}')
query = '浙江的省会在哪里?'
messages = [{
'role': 'user',
'content': query
}]
resp = client.chat.completions.create(
model=model_type,
messages=messages,
seed=42)
response = resp.choices[0].message.content
print(f'query: {query}')
print(f'response: {response}')
#流式
messages.append({'role': 'assistant', 'content': response})
query = '这有什么好吃的?'
messages.append({'role': 'user', 'content': query})
stream_resp = client.chat.completions.create(
model=model_type,
messages=messages,
stream=True,
seed=42)
print(f'query: {query}')
print('response: ', end='')
for chunk in stream_resp:
print(chunk.choices[0].delta.content, end='', flush=True)
print()
"""Out[0]
model_type: qwen-7b-chat
query: 浙江的省会在哪里?
response: 浙江省的省会是杭州市。
query: 这有什么好吃的?
response: 杭州有许多美食,例如西湖醋鱼、东坡肉、龙井虾仁、叫化童子鸡等。此外,杭州还有许多特色小吃,如西湖藕粉、杭州小笼包、杭州油条等。
"""
4.llama.cpp
llama.cpp是使用c++语言编写的对llama系列模型进行高效推理或量化推理的开源库。该库使用了ggml底层计算库进行推理。在使用之前需要额外将python的weights转为ggml格式或gguf格式方可使用。和llama.cpp类似,还有兼容ChatGLM模型的chatglm.cpp和兼容qwen模型的qwen.cpp和mistral的mistral.cpp。
安装依赖:
pip install modelscope
git clone --recursive https://github.com/QwenLM/qwen.cpp && cd qwen.cpp
cmake -B build
cmake --build build -j --config Release
下载模型:
from modelscope import snapshot_download
print(snapshot_download('qwen/Qwen-1_8B-Chat'))
#/mnt/workspace/.cache/modelscope/qwen/Qwen-1_8B-Chat
将原始模型转换为ggml支持的格式:
python3 qwen_cpp/convert.py -i /mnt/workspace/.cache/modelscope/qwen/Qwen-1_8B-Chat -t q4_0 -o qwen1_8b-ggml.bin
./build/bin/main -m qwen1_8b-ggml.bin --tiktoken /mnt/workspace/.cache/modelscope/qwen/Qwen-1_8B-Chat/qwen.tiktoken -p 你好
#你好!有什么我可以帮助你的吗?
量化章节中我们介绍,GGML库适合于CPU运行,因此推荐用户在CPU环境中或边缘计算中考虑cpp库进行推理。
5.FastChat
FastChat Github地址: https://github.com/lm-sys/FastChat
FastChat架构:https://github.com/lm-sys/FastChat/blob/main/docs/server_arch.md
FastChat是一个开源推理库,侧重于模型的分布式部署实现,并提供了OpenAI样式的RESTFul API。是一个开放平台,用于训练、服务和评估基于大型语言模型的聊天机器人。
- FastChat 的核心功能包括:
- 最先进模型的训练和评估代码(例如,Vicuna、MT-Bench)。
- 具有 Web UI 和 OpenAI 兼容 RESTful API 的分布式多模型服务系统

pip3 install "fschat[model_worker,webui]"
python3 -m fastchat.serve.controller
在新的terminal中启动:
FASTCHAT_USE_MODELSCOPE=true python3 -m fastchat.serve.model_worker --model-path qwen/Qwen-1_8B-Chat --revision v1.0.0
之后在新的terminal中可以运行界面进行推理:
python3 -m fastchat.serve.gradio_web_server

6.DeepSpeed
网址:https://github.com/microsoft/DeepSpeed
网址:https://www.deepspeed.ai/training/
Deepspeed并行框架介绍:https://github.com/wzzzd/LLM_Learning_Note/blob/main/Parallel/deepspeed.md
Deepspeed是微软推出的一个开源分布式工具,其集合了分布式训练、推断、压缩等高效模块。 该工具旨在提高大规模模型训练的效率和可扩展性。它通过多种技术手段来加速训练,包括模型并行化、梯度累积、动态精度缩放、本地模式混合精度等。DeepSpeed还提供了一些辅助工具,如分布式训练管理、内存优化和模型压缩等,以帮助开发者更好地管理和优化大规模深度学习训练任务。此外,deepspeed基于pytorch构建,只需要简单修改即可迁移。 DeepSpeed已经在许多大规模深度学习项目中得到了应用,包括语言模型、图像分类、目标检测等。
-
DeepSpeed是由Microsoft提供的分布式训练工具,旨在支持更大规模的模型和提供更多的优化策略和工具。与其他框架相比,DeepSpeed支持更大规模的模型和提供更多的优化策略和工具。其中,主要优势在于支持更大规模的模型、提供了更多的优化策略和工具(例如 ZeRO 和 Offload 等)
- 用 3D 并行化实现万亿参数模型训练: DeepSpeed 实现了三种并行方法的灵活组合:ZeRO 支持的数据并行,流水线并行和张量切片模型并行。3D 并行性适应了不同工作负载的需求,以支持具有万亿参数的超大型模型,同时实现了近乎完美的显存扩展性和吞吐量扩展效率。此外,其提高的通信效率使用户可以在网络带宽有限的常规群集上以 2-7 倍的速度训练有数十亿参数的模型。
- ZeRO-Offload 使 GPU 单卡能够训练 10 倍大的模型: 为了同时利用 CPU 和 GPU 内存来训练大型模型,我们扩展了 ZeRO-2。我们的用户在使用带有单张英伟达 V100 GPU 的机器时,可以在不耗尽显存的情况下运行多达 130 亿个参数的模型,模型规模扩展至现有方法的10倍,并保持有竞争力的吞吐量。此功能使数十亿参数的模型训练更加大众化,,并为许多深度学习从业人员打开了一扇探索更大更好的模型的窗户。
- 通过 DeepSpeed Sparse Attention 用6倍速度执行10倍长的序列: DeepSpeed提供了稀疏 attention kernel ——一种工具性技术,可支持长序列的模型输入,包括文本输入,图像输入和语音输入。与经典的稠密 Transformer 相比,它支持的输入序列长一个数量级,并在保持相当的精度下获得最高 6 倍的执行速度提升。它还比最新的稀疏实现快 1.5–3 倍。此外,我们的稀疏 kernel 灵活支持稀疏格式,使用户能够通过自定义稀疏结构进行创新。
- 1 比特 Adam 减少 5 倍通信量: Adam 是一个在大规模深度学习模型训练场景下的有效的(也许是最广为应用的)优化器。然而,它与通信效率优化算法往往不兼容。因此,在跨设备进行分布式扩展时,通信开销可能成为瓶颈。我们推出了一种 1 比特 Adam 新算法,以及其高效实现。该算法最多可减少 5 倍通信量,同时实现了与Adam相似的收敛率。在通信受限的场景下,我们观察到分布式训练速度提升了 3.5 倍,这使得该算法可以扩展到不同类型的 GPU 群集和网络环境。
-
推理框架小结
- 如果CPU推理,llama.cpp 结合模型int4量化,最佳的选择
- GPU推理,微软的 DeepSpeed-FastGen 是一个好的选择
- 手机终端推理,MLC LLM可以作为候选

最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

五、面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

尧米是由西云算力与CSDN联合运营的AI算力和模型开源社区品牌,为基于DaModel智算平台的AI应用企业和泛AI开发者提供技术交流与成果转化平台。
更多推荐



 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)