LlamaIndex 四 数据连接器
我们通过各项配置,理解了LlamaIndex在构建知识库和基于知识库的推荐两个阶段,怎么和业务相结合。本文,我们将开始深入理解LlamaIndex的各个模块。首先,LlamaIndex强大的数据连接器上场。LlamaIndex擅长和各种类型或格式的数据打交道,并通过Document和Nodes的概念,embedding索引后,交给大模型处理,高精度完成AI知识库或AI助理应用开发。利用私有知识库,
前言
我们通过各项配置,理解了LlamaIndex在构建知识库和基于知识库的推荐两个阶段,怎么和业务相结合。本文,我们将开始深入理解LlamaIndex的各个模块。首先,LlamaIndex强大的Data Connector 数据连接器上场。
LlamaIndex擅长和各种类型或格式的数据打交道,并通过Document和Nodes的概念,embedding索引后,交给大模型处理,高精度完成AI知识库或AI助理应用开发。利用私有知识库,增强LLM的检索能力, 即RAG。
现在, 让我们来仔细研究Data Connectors数据连接器模块的细节。
Data Connectors

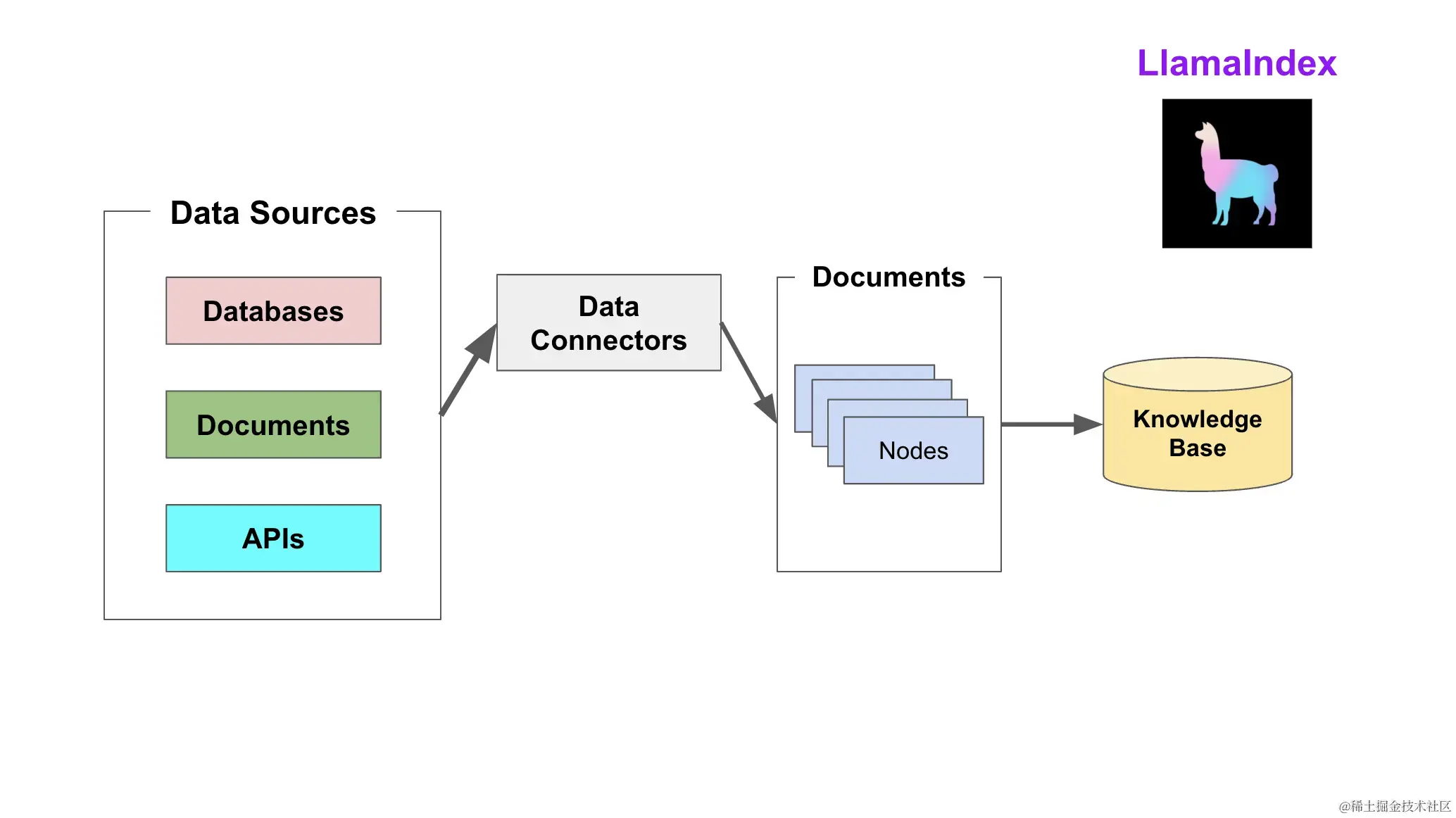
开始深入之前,我们先来回顾下LlamaIndex构建知识库(Knowledge Base)阶段的架构图。 最左侧的Data Sources部分展示了RAG应用中,各种数据来源。RAG应用多是聊天机器人或搜索的产品形式,入口简单,这就需要LlamaIndex具备整合或自然语言处理各种格式,或各种渠道数据的能力。图中列出了Databases 数据库,Documents 文档,APIs 应用接口。假如是大型企业或组织,这是要整多少数据库,横跨多长时间的文档,散落在多少业务中的API?
LangChain作为LLm开发框架,将RAG这块交给LlamaIndex, 正因为它的专业。当我们开始着手RAG应用时,数据加载是非常重要的一个环节,且LlamaIndex给我们安排了那些科技和狠活…
数据连接器接口
为支持不同数据源和格式的数据加载,LlamaIndex准备了一堆数据接口类,让人好生欢迎
- Simple Directory Reader
- Psychic Reader
- DeepLake Reader
- Qdrant Reade
- Discord Reader
- MongoDB Reader
- Chroma Reader
- MyScale Reader
- Faiss Reader
- Obsidian Reader
- Slack Reader
- Web Page Reader
- Pinecone Reader
- Mbox Reader
- MilvusReader
- Notion Reader
- Github Repo Reader
- Google Docs Reader
- Database Reader
- Twitter Reader
- Weaviate Reader
连接demos
- 连接网页数据
ini复制代码from llama_index import download_loader #老版本可以直接import SimpleWebPageReader 现在得这么搞
SimpleWebPageReader = download_loader("SimpleWebPageReader")
loader = SimpleWebPageReader()
documents = loader.load_data(urls=['http://paulgraham.com/worked.html'])
各位,请留意。最新版本的LlamaIndex 基于llamahub来托管,大家可以到Llama Hub来看最新文档。代码中download_loader的意思就是先从llamahub中加载SimpleWebPageReade连接器。

从打印结果我们可以看到,SimpleWebPageReader接口将网页数据以Document的格式保存。
- 连接Markdown格式文件
ini复制代码from pathlib import Path
from llama_index import download_loader
MarkdownReader = download_loader("MarkdownReader")
loader = MarkdownReader()
documents = loader.load_data(file=Path('./README.md'))
使用了MarkdownReader读取了当前目录下的README.md文件
- pdf 格式文件
ini复制代码from pathlib import Path
from llama_index import download_loader
PDFReader = download_loader("PDFReader")
loader = PDFReader()
documents = loader.load_data(file=Path('./article.pdf'))
- api
ini复制代码import requests
from llama_index import VectorStoreIndex, download_loader
headers = {
}
data = requests.get("https://api.github.com/users/shunwuyu/repos", headers=headers).json()
JsonDataReader = download_loader("JsonDataReader")
loader = JsonDataReader()
documents = loader.load_data(data)
index = VectorStoreIndex.from_documents(documents)
index.query("how many repos are there?")
基于github的api获取了json数据并提问。
综合案例
现在就让我们基于Data Connectors的理解,去开发一个针对langchain文档的知识库RAG应用
- 安装LlamaIndex
css
复制代码!pip install -q -U llama-index
- 设置OPANAI_API_KEY
lua复制代码import os
os.environ['OPENAI_API_KEY'] = 'your valid openai api key'
- 下载langchain文件并使用数据接口加载
bash
复制代码!git clone https://github.com/sugarforever/wtf-langchain.git
Wft-langchain这个repo,是langchain的开源教程库,里面的文档都是RAG应用的语料来源
ini复制代码from llama_index import SimpleDirectoryReader
reader = SimpleDirectoryReader( input_dir="./wtf-langchain", required_exts=[".md"], recursive=True )
docs = reader.load_data() #加载数据到文档数组
我们使用SimpleDirectoryReader, 读取了刚刚克隆下来的wtf-langchain目录下的所有markdown格式的文件。
- 对文档构建索引,生成知识库, 并初始化查询引擎
ini复制代码from llama_index import VectorStoreIndex
index = VectorStoreIndex.from_documents(docs)
query_engine = index.as_query_engine()
response = query_engine.query("什么是WTF LangChain?")
print(response)

从上图看,我们拿到了准确的答案。
总结
- 在开发
RAG应用时,数据加载是非常重要的一个环节。 Data Connectors 是LlamaIndex的第一个核心模块。 - 操练一些数据接口,开始干活。
如何系统的去学习大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
😝有需要的小伙伴,可以V扫描下方二维码免费领取🆓

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型商业化落地方案

阶段1:AI大模型时代的基础理解
- 目标:了解AI大模型的基本概念、发展历程和核心原理。
- 内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
- 目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
- 内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.2.1 什么是Prompt
- L2.2.2 Prompt框架应用现状
- L2.2.3 基于GPTAS的Prompt框架
- L2.2.4 Prompt框架与Thought
- L2.2.5 Prompt框架与提示词
- L2.3 流水线工程
- L2.3.1 流水线工程的概念
- L2.3.2 流水线工程的优点
- L2.3.3 流水线工程的应用
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
- 目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
- 内容:
- L3.1 Agent模型框架
- L3.1.1 Agent模型框架的设计理念
- L3.1.2 Agent模型框架的核心组件
- L3.1.3 Agent模型框架的实现细节
- L3.2 MetaGPT
- L3.2.1 MetaGPT的基本概念
- L3.2.2 MetaGPT的工作原理
- L3.2.3 MetaGPT的应用场景
- L3.3 ChatGLM
- L3.3.1 ChatGLM的特点
- L3.3.2 ChatGLM的开发环境
- L3.3.3 ChatGLM的使用示例
- L3.4 LLAMA
- L3.4.1 LLAMA的特点
- L3.4.2 LLAMA的开发环境
- L3.4.3 LLAMA的使用示例
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
- 目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
- 内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
学习计划:
- 阶段1:1-2个月,建立AI大模型的基础知识体系。
- 阶段2:2-3个月,专注于API应用开发能力的提升。
- 阶段3:3-4个月,深入实践AI大模型的应用架构和私有化部署。
- 阶段4:4-5个月,专注于高级模型的应用和部署。
这份完整版的大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓

尧米是由西云算力与CSDN联合运营的AI算力和模型开源社区品牌,为基于DaModel智算平台的AI应用企业和泛AI开发者提供技术交流与成果转化平台。
更多推荐



 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)