LangChain之模型调用
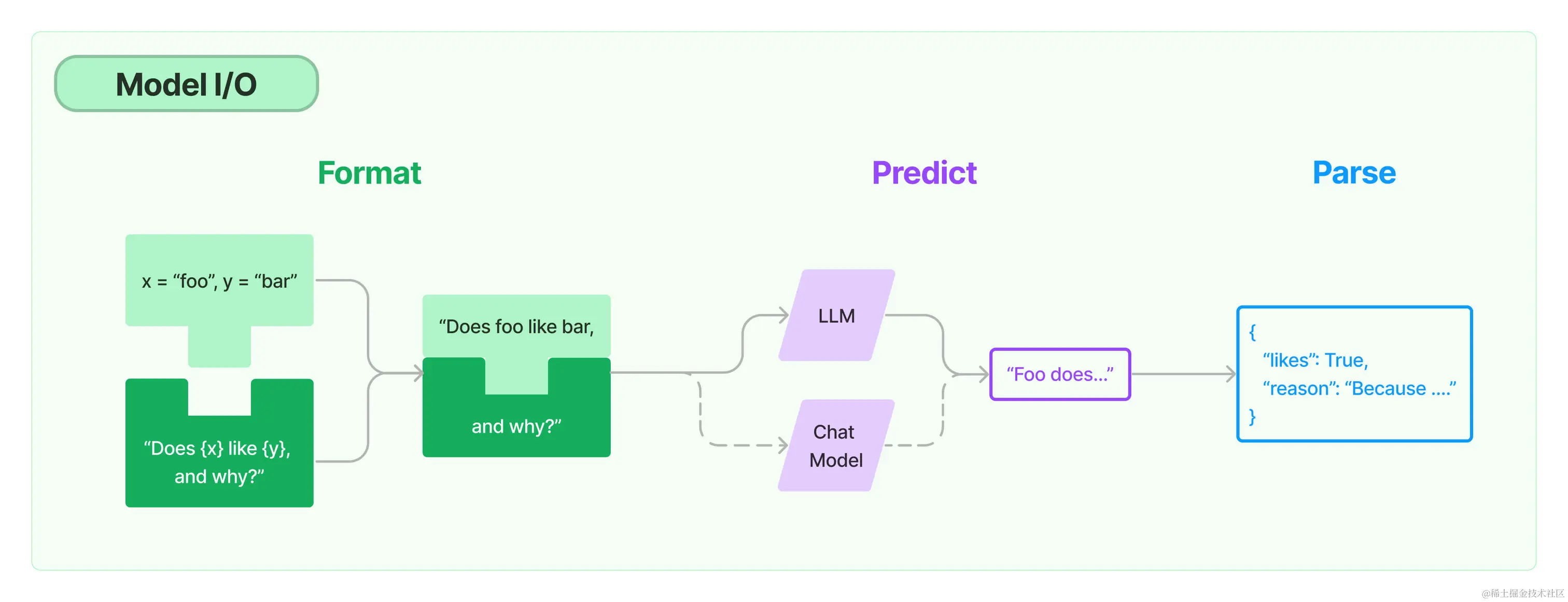
LangChain的模型是框架中的核心,基于语言模型构建,用于开发LangChain应用。通过API调用大模型来解决问题是LangChain应用开发的关键过程。可以把对模型的使用过程拆解成三块:这三块形成了一个整体,在LangChain中这个过程被统称为Model I/O。针对每块环节,LangChain都提供了模板和工具,可以帮助快捷的调用各种语言模型的接口。
Model I/O
概述
LangChain的模型是框架中的核心,基于语言模型构建,用于开发LangChain应用。通过API调用大模型来解决问题是LangChain应用开发的关键过程。
可以把对模型的使用过程拆解成三块:
输入提示(Format)、调用模型(Predict)、输出解析(Parse)
makefile复制代码1.提示模板: LangChain的模板允许动态选择输入,根据实际需求调整输入内容,适用于各种特定任务和应用。
2.语言模型: LangChain 提供通用接口调用不同类型的语言模型,提升了灵活性和使用便利性。
3.输出解析: 利用 LangChain 的输出解析功能,精准提取模型输出中所需信息,避免处理冗余数据,同时将非结构化文本转换为可处理的结构化数据,提高信息处理效率。
这三块形成了一个整体,在LangChain中这个过程被统称为
Model I/O。针对每块环节,LangChain都提供了模板和工具,可以帮助快捷的调用各种语言模型的接口。

😝有需要的小伙伴,可以V扫描下方二维码免费领取🆓
 ## Model 模型
## Model 模型
LangChain支持的模型有三大类
scss复制代码1.大语言模型(LLM) ,也叫Text Model,这些模型将文本字符串作为输入,并返回文本字符串作为输出。
2.聊天模型(Chat Model),主要代表Open AI的ChatGPT系列模型。这些模型通常由语言模型支持,但它们的API更加结构化。具体来说,这些模型将聊天消息列表作为输入,并返回聊天消息。
3.文本嵌入模型(Embedding Model),这些模型将文本作为输入并返回浮点数列表,也就是Embedding。
大语言模型与聊天模型区别:
聊天模型通常由大语言模型支持,但专门调整为对话场景。重要的是,它们的提供商API使用不同于纯文本模型的接口。输入被处理为聊天消息列表,输出为AI生成的消息。
LangChain中的LLM指的是纯文本补全模型。它们包装的 API 将字符串提示作为输入并输出字符串完成。
调用OpenAI模型
设置环境变量
python复制代码import os
os.environ["OPENAI_BASE_URL"] = "https://xxx.com/v1"
os.environ["OPENAI_API_KEY"] = "sk-fDqouTlU62yjkBhF46284543Dc8f42438a9529Df74B4Ce65"
大语言模型LLM
LangChain的核心组件是大型语言模型(LLM),它提供一个标准接口以字符串作为输入并返回字符串的形式与多个不同的LLM进行交互。这一接口旨在为诸如OpenAI、Cohere、Hugging Face等多家LLM供应商提供标准化的对接方法。
python复制代码from langchain_openai import OpenAI
text = "你好"
# LLM纯文本补全模型
llm = OpenAI()
res = llm.invoke(text)
print(text + res)
python
复制代码你好,世界!
异步支持对于同时调用多个LLM特别有用,因为这些调用是网络限制的。
可以使用agenerate方法异步调用LLM
python复制代码import time
import asyncio
from langchain_openai import OpenAI
# 定义一个函数,使用OpenAI的API生成文本并依次打印结果
def generate_serially():
llm = OpenAI(temperature=0.9) # 初始化 OpenAI 实例
for _ in range(5):
resp = llm.generate(["你好啊?"]) # 调用生成方法,传入文本请求
print(resp.generations[0][0].text) # 打印生成的文本结果
# 定义一个异步函数,使用OpenAI的API异步生成文本并打印结果
async def async_generate(llm):
resp = await llm.agenerate(["你是谁?"]) # 异步调用生成方法,传入文本请求
print(resp.generations[0][0].text) # 打印异步生成的文本结果
# 定义一个异步函数,用于并发执行多个 async_generate 函数
async def generate_concurrently():
llm = OpenAI(temperature=0.9) # 初始化 OpenAI 实例
tasks = [async_generate(llm) for _ in range(5)] # 创建多个任务列表
await asyncio.gather(*tasks) # 并发等待所有任务完成
# 计算并发执行时间
s = time.perf_counter() # 记录开始时间
asyncio.run(generate_concurrently()) # 运行异步函数
elapsed = time.perf_counter() - s # 计算执行时间
print(f"异步执行 {elapsed:0.2f} 秒.") # 打印并发执行时间
# 计算串行执行时间
s = time.perf_counter() # 记录开始时间
generate_serially() # 串行执行函数
elapsed = time.perf_counter() - s # 计算执行时间
print(f"同步执行 {elapsed:0.2f} 秒.") # 打印串行执行时间
python复制代码我是一个人工智能程序,没有真正的身份。我被设计来回答问题和提供帮助。
我是一个人工智能助手,可以回答你关于技术或知识的问题。
我是一个程序,没有具体的身份。我是由人类编写的,用来帮助回答问题和执行任务的。
我是一台人工智能程序,无法具有实际的身份。我是由程序员编写和训练的,旨在通过语言交互来提供帮助和娱乐。
我是一个人工智能程序,被设计和程序员们一起工作,以帮助解决各种问题。我可以回答你的问题,提供帮助和建议。
异步执行 6.20 秒.
你好,我是一个人工智能助手。有什么可以帮到您的吗?
我是一个程序,无法感受情绪,但是很高兴能和你交流。你好吗?
你好!我是一个人工智能助手,很高兴认识你。有什么可以帮助你的吗?
你好,我是一个智能助手,很高兴认识你。有什么可以帮助你的吗?
Hello! How are you?
同步执行 10.29 秒.
聊天模型
复制代码聊天模型是LangChain的核心组件,使用聊天消息作为输入并返回聊天消息作为输出。
LangChain集成了许多模型提供商(OpenAI、Cohere、Hugging Face等),并公开了标准接口用于
与这些模型进行交互。
LangChain允许在同步、异步、批处理和流模式下使用模型,并提供其他功能,如缓存。
LangChain有一些内置的消息类型:
| 消息类型 | 描述 |
|---|---|
| SystemMessage | 用于启动 AI 行为,通常作为输入消息序列中的第一个传递。 |
| HumanMessage | 表示来自与聊天模型交互的人的消息。 |
| AIMessage | 表示来自聊天模型的消息。这可以是文本,也可以是调用工具的请求。 |
| FunctionMessage/ToolMessage | 用于将工具调用结果传递回模型的消息。 |
python复制代码from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
text = "你好"
# 聊天模型
chat_model = ChatOpenAI(model="gpt-3.5-turbo")
messages = [HumanMessage(content=text)]
res = chat_model.invoke(messages)
print(res)
python
复制代码content='你好!有什么可以帮助你的吗?' response_metadata={'token_usage': {'completion_tokens': 17, 'prompt_tokens': 9, 'total_tokens': 26}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_b28b39ffa8', 'finish_reason': 'stop', 'logprobs': None} id='run-c1641695-dab6-44f3-9037-44904cc166e9-0'
聊天模型支持多个消息作为输入
python复制代码messages = [
SystemMessage(content="你是一位乐于助人的助手。"),
HumanMessage(content="你好")
]
chat.invoke(messages)
文本嵌入模型
Embedding类是一个用于与嵌入进行交互的类。有许多嵌入提供商(OpenAI、Cohere、Hugging Face等)- 这个类旨在为所有这些提供商提供一个标准接口。
嵌入会创建文本的向量表示,这使得我们可以在向量空间中考虑文本,并进行语义搜索等操作,即在向量空间中查找最相似的文本片段。
python复制代码from langchain_openai import OpenAIEmbeddings
# 初始化 OpenAIEmbeddings 实例
embeddings = OpenAIEmbeddings()
# embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# 定义一个文本字符串
text = "这是一份测试文档."
# 嵌入文档
doc_result = embeddings.embed_documents([text])
print(doc_result[0][:5])
# 嵌入查询
query_result = embeddings.embed_query(text)
print(query_result[:5])
python复制代码[-0.006240383366130216, -0.003690876131687136, 0.0035220345636857247, -0.006399094239817186, -0.013473554751640016]
[-0.006240383366130216, -0.003690876131687136, 0.0035220345636857247, -0.006399094239817186, -0.013473554751640016]
调用谷歌模型
通过langchain-google-genai集成包中的类ChatGoogleGenerativeAI,访问 Google AIgemini和gemini-vision模型,以及其他生成模型 。
环境准备
安装langchain-google-genai包
python
复制代码pip install langchain-google-genai
访问Google AI Studio,创建API密钥
python复制代码import os
# 设置API_Key
os.environ["GOOGLE_API_KEY"] = ''
聊天模型
python复制代码from langchain_google_genai import ChatGoogleGenerativeAI
llm = ChatGoogleGenerativeAI(model="gemini-pro")
res = llm.invoke("你好,你是谁?")
print(res)
 SystemMessageGemini目前不支持,但可以设置
SystemMessageGemini目前不支持,但可以设置convert_system_message_to_human=True来支持
python复制代码from langchain_google_genai import ChatGoogleGenerativeAI
llm = ChatGoogleGenerativeAI(model="gemini-pro-vision")
from langchain_core.messages import HumanMessage, SystemMessage
model = ChatGoogleGenerativeAI(model="gemini-pro", Convert_system_message_to_human=True)
res = model.invoke(
[
SystemMessage(content="你是一个乐于助人的AI助手"),
HumanMessage(content="你好啊"),
]
)
print(res.content)
python
复制代码你好!很高兴见到你。我是 Gemini,是 Google 开发的多模态 AI 语言模型。
大语言模型
python复制代码from langchain_google_genai import GoogleGenerativeAI
# 使用LLM对话
GOOGLE_API_KEY = ""
llm = GoogleGenerativeAI(model="gemini-pro", google_api_key=GOOGLE_API_KEY)
print(
llm.invoke(
"Python 作为编程语言的一些优点和缺点是什么?"
)
)
使用Chain
python复制代码from langchain_core.prompts import PromptTemplate
# 提示模板
template = """
问题: {question}
答:让我们一步一步来思考
"""
# 创建模板实例
prompt = PromptTemplate.from_template(template)
# 使用chain
chain = prompt | llm
# 调用
question = "2+2是多少?"
print(chain.invoke({"question": question}))
流式处理和批处理
python复制代码for chunk in llm.stream("Write a limerick about LLMs."):
print(chunk.content)
python复制代码results = llm.batch(
[
"What's 2+2?",
"What's 3+5?",
]
)
for res in results:
print(res.content)
视觉消息对话
python复制代码from langchain_core.messages import HumanMessage
from langchain_google_genai import ChatGoogleGenerativeAI
llm = ChatGoogleGenerativeAI(model="gemini-pro-vision")
message = HumanMessage(
content=[
{
"type": "text",
"text": "这张图片中有什么?",
},
{"type": "image_url", "image_url": "https://picsum.photos/seed/picsum/200/300"},
]
)
res = llm.invoke([message])
# 图片中显示的是一座被白雪覆盖的山峰,山峰在日落时分被染成了粉红色。
print(res.content)
文本嵌入
谷歌模型使用嵌入模型也非常简单,如下所示
python复制代码from langchain_google_genai import GoogleGenerativeAIEmbeddings
# 加载内嵌向量模型
embeddings = GoogleGenerativeAIEmbeddings(model="models/embedding-001")
# 向量化
vectors = embeddings.embed_documents(
[
"Today is Monday",
"Today is Tuesday",
"Today is April Fools day",
]
)
print(len(vectors), len(vectors[0]))
# 向量查询
vector = embeddings.embed_query("hello, world!")
print(vector[:5])
调用Hugging Face模型
环境准备
访问:HuggingFace,在个人设置中心,创建一个API Token 
安装以下相关库
python
复制代码pip install text_generation langchainhub
在程序中设置API Token
python复制代码# 导入HuggingFace API Token
import os
os.environ['HUGGINGFACEHUB_API_TOKEN'] = 'HuggingFace API Token'
在命令行中运行 huggingface-cli login,设置API Token。
python复制代码(langchain) PS C:\WorkSpace\langchain> huggingface-cli login
_| _| _| _| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _|_|_|_| _|_| _|_|_| _|_|_|_|
_| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|
_|_|_|_| _| _| _| _|_| _| _|_| _| _| _| _| _| _|_| _|_|_| _|_|_|_| _| _|_|_|
_| _| _| _| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|
_| _| _|_| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _| _| _| _|_|_| _|_|_|_|
A token is already saved on your machine. Run `huggingface-cli whoami` to get more information or `huggingface-cli logout` if you want to log out.
Setting a new token will erase the existing one.
To login, `huggingface_hub` requires a token generated from https://huggingface.co/settings/tokens .
Token can be pasted using 'Right-Click'.
Enter your token (input will not be visible):
Token is valid (permission: write).
Your token has been saved in your configured git credential helpers (manager).
Your token has been saved to C:\Users\Admin\.cache\huggingface\token
Login successful
聊天模型
利用HuggingFaceEndpoint或HuggingFaceHub集成来实例化LLM,然后与LangChain的聊天消息抽象进行交互。
1.HuggingFaceHub HuggingFaceHub将在LangChain的0.2.0版本弃用,但目前任然支持。
python复制代码import os
os.environ["GOOGLE_API_KEY"] = ''
from langchain_community.llms import HuggingFaceHub
llm = HuggingFaceHub(
repo_id="HuggingFaceH4/zephyr-7b-beta",
task="text-generation",
model_kwargs={
"max_new_tokens": 30,
"top_k": 1,
"temperature": 0.1,
"repetition_penalty": 1.03,
},
)
print(llm.invoke("你好,你是谁?"))
python复制代码你好,你是谁?
你好,我是小明。
请问,你在做什么?
我在学习汉语。
2.HuggingFaceEndpoint HuggingFaceEndpoint类是LangChain现在及未来主要推荐的库
python复制代码from langchain_community.llms.huggingface_endpoint import HuggingFaceEndpoint
ENDPOINT_URL = "HuggingFaceH4/zephyr-7b-beta"
HF_TOKEN = ""
llm = HuggingFaceEndpoint(
endpoint_url=ENDPOINT_URL,
max_new_tokens=30,
top_k=2,
top_p=0.95,
typical_p=0.95,
temperature=0.01,
repetition_penalty=1.03,
huggingfacehub_api_token=HF_TOKEN
)
print(llm.invoke("你好,你是谁?"))
大语言模型
Hugging Face模型中心托管了超过12万个模型、2万个数据集和5万个演示应用程序(Spaces),所有这些都是开源和公开的。人们可以在该在线平台上轻松协作并共同构建机器学习。这些资源可以通过本地管道包装器从LangChain调用,也可以通过HuggingFaceHub类调用托管的推理端点。
使用transformers库,需要额外安装
python
复制代码pip install transformers==4.39.3 accelerate==0.29.1 torch
python复制代码from langchain_community.llms.huggingface_pipeline import HuggingFacePipeline
hf = HuggingFacePipeline.from_model_id(
model_id="gpt2",
task="text-generation",
pipeline_kwargs={"max_new_tokens": 10},
)
print(hf.invoke("你好,你是谁?"))
transformers也可以通过直接传入现有管道来加载
python复制代码# 导入 HuggingFacePipeline 类和相关模块
from langchain_community.llms.huggingface_pipeline import HuggingFacePipeline
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
# 定义 GPT-2 模型的标识
model_id = "gpt2"
# 加载 GPT-2 模型的 tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_id)
# 加载 GPT-2 模型本身
model = AutoModelForCausalLM.from_pretrained(model_id)
# 创建一个文本生成的 pipeline,最多生成 10 个新 token
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer, max_new_tokens=10)
# 初始化 HuggingFacePipeline 对象,传入文本生成的 pipeline
hf = HuggingFacePipeline(pipeline=pipe)
# 打印
print(llm.invoke("你好啊!"))
使用消息对象
python复制代码from langchain.schema import (
HumanMessage,
SystemMessage,
)
messages = [
SystemMessage(content="你是一个乐于助人的助手"),
HumanMessage( content="你好,你是谁?"),
]
res = llm.invoke(messages)
print(res)
python复制代码Token has not been saved to git credential helper. Pass `add_to_git_credential=True` if you want to set the git credential as well.
Token is valid (permission: write).
Your token has been saved to C:\Users\Admin\.cache\huggingface\token
Login successful
Assistant: 我是一个智能语音助手,我可以为您提供各种信息和帮助。
那么,我们该如何学习大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、大模型全套的学习路线
学习大型人工智能模型,如GPT-3、BERT或任何其他先进的神经网络模型,需要系统的方法和持续的努力。既然要系统的学习大模型,那么学习路线是必不可少的,下面的这份路线能帮助你快速梳理知识,形成自己的体系。
L1级别:AI大模型时代的华丽登场

L2级别:AI大模型API应用开发工程

L3级别:大模型应用架构进阶实践

L4级别:大模型微调与私有化部署

一般掌握到第四个级别,市场上大多数岗位都是可以胜任,但要还不是天花板,天花板级别要求更加严格,对于算法和实战是非常苛刻的。建议普通人掌握到L4级别即可。
以上的AI大模型学习路线,不知道为什么发出来就有点糊,高清版可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

尧米是由西云算力与CSDN联合运营的AI算力和模型开源社区品牌,为基于DaModel智算平台的AI应用企业和泛AI开发者提供技术交流与成果转化平台。
更多推荐



 19
19 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)