RAG评价方法综述:相关性、有效性与忠诚性
RAG模型是一种结合了检索和生成技术的模型,它通过引用外部知识库的信息来生成答案或内容,具有较强的可解释性和定制能力。RAG模型是解决通用基础大模型在实际业务场景中局限性的有效方案,RAG模型结合了检索和生成两个复杂的自然语言处理任务,这使得模型的整体复杂性增加,评价时需要同时考虑检索和生成的效果。
RAG模型(Retrieval Augmented Generation) 是一种结合了检索和生成技术的模型,它通过引用外部知识库的信息来生成答案或内容,具有较强的可解释性和定制能力。
RAG模型是解决通用基础大模型在实际业务场景中局限性的有效方案,RAG模型结合了检索和生成两个复杂的自然语言处理任务,这使得模型的整体复杂性增加,评价时需要同时考虑检索和生成的效果。
RAGAS: Automated Evaluation of Retrieval Augmented Generation
https://aclanthology.org/2024.eacl-demo.16.pdf
https://github.com/explodinggradients/ragas
RAG系统由检索模块和基于大型语言模型(LLM)的生成模块组成,它们能够从参考文本数据库中获取知识,使LLM能够作为用户和文本数据库之间的自然语言层,减少幻觉(hallucinations)的风险。
RAGAS框架提出了一系列指标,可以在不依赖于人类标注的参考标准的情况下,评估这些不同的维度。作者认为这样的框架可以显著促进RAG架构的快速评估周期,这对于LLM的快速采用尤为重要。
RAGAS讨论了评估RAG系统的三种策略,这些策略不需要依赖于人类标注的数据集或参考答案。作者特别关注三个质量方面:忠实度(Faithfulness)、答案相关性(Answer Relevance)和上下文相关性(Context Relevance)。
忠实度(Faithfulness)
忠实度指的是生成的答案应该基于给定的上下文。这对于避免幻觉(hallucinations)和确保检索到的上下文可以作为生成答案的依据非常重要。为了估计忠实度,首先使用LLM从答案中提取一组陈述,然后LLM确定这些陈述是否可以从上下文中推断出来。如果答案中的陈述可以被上下文支持,那么认为这个答案是忠实的。
- 使用大型语言模型(LLM)从生成的答案中提取一组陈述(S(as(q)))。
Given a question and answer, create one or more statements from each sentence in the given answer.
question: [question]
answer: [answer]
这里的[question]和[answer]代表给定的问题和答案。
- 对于S中的每个陈述
si,LLM使用验证函数v(si, c(q))来确定si是否可以从上下文c(q)中推断出来。
Consider the given context and following statements, then determine whether they are supported by the information present in the context. Provide a brief explanation for each statement before arriving at the verdict (Yes/No). Provide a final verdict for each statement in order at the end in the given format. Do not deviate from the specified format.
statement: [statement 1]
...
statement: [statement n]
- 最终的忠实度得分
F计算公式为F = |V| / |S|,其中|V|是LLM支持的陈述数量,|S|是总陈述数量。
答案相关性(Answer Relevance)
答案相关性指的是生成的答案应该直接且适当地回答提出的问题。这种评估不考虑事实性,但会惩罚答案不完整或包含冗余信息的情况。为了估计答案相关性,基于给定的答案生成n个潜在的问题,然后使用文本嵌入模型计算原始问题与这些潜在问题之间的相似度。答案相关性得分是通过计算原始问题与生成问题之间的余弦相似度来得出的。
- 基于给定的答案as(q),使用大型语言模型(LLM)生成n个潜在的问题qi。
Generate a question for the given answer.
answer: [answer]
-
使用
text-embedding-ada-002模型,这是OpenAI API提供的一个文本嵌入模型,为所有生成的问题(包括原始问题q和潜在问题qi)获取嵌入向量。 -
对于每个潜在问题qi,计算其与原始问题q的相似度
sim(q, qi),这是通过计算对应嵌入向量之间的余弦相似度来实现的。 -
答案相关性得分
AR的计算公式为:
其中n是生成的潜在问题的数量,sim(q, qi)是原始问题q与每个潜在问题qi之间的相似度。
上下文相关性(Context Relevance)
上下文相关性指的是检索到的上下文应该只包含回答疑问所需的信息。这个指标旨在惩罚包含冗余信息的情况。为了估计上下文相关性,LLM从上下文中提取对回答问题至关重要的句子子集。上下文相关性得分是通过计算提取的句子数量与上下文中总句子数量的比例来得出的。
- 给定一个问题q及其上下文c(q),使用大型语言模型(LLM)从上下文中提取出一组关键句子(Sext),这些句子对于回答问题q至关重要。
Please extract relevant sentences from the provided context that can potentially help answer the following question. If no relevant sentences are found, or if you believe the question cannot be answered from the given context, return the phrase "Insufficient Information". While extracting candidate sentences you’re not allowed to make any changes to sentences from given context.
- 计算上下文相关性得分(Calculating Context Relevance Score):
提取的句子数量上下文中总句子数量
中,提取的句子数量是指从上下文中成功提取出的相关句子的数量,而上下文中总句子数量是指上下文c(q)中包含的句子总数。
RAGEval: Scenario Specific RAG Evaluation Dataset Generation Framework
https://github.com/OpenBMB/RAGEval
https://arxiv.org/abs/2408.01262
RAGEval方法是一个用于评估文本生成系统的方法。整体的生成过程可以概括为以下几个步骤:从模式摘要(S)到配置生成(C),再到文档生成(D)。然后从文档中生成问答对(Q, A),提取相关参考(R)来支持答案,并最终提取关键点来捕捉答案中的关键信息。
召回率(Recall)
召回率用于评估检索过程在匹配真实参考文本方面的有效性。
其中,n是真实参考文本的总数,( G_i )表示第i个真实参考文本,R表示检索到的参考文本集合,M(Gi, R)是一个布尔函数,如果Gi中的所有句子至少在一个R中的参考文本里找到,则返回真,否则返回假,⊕(·)是指示函数,条件为真时返回1,否则返回0。
有效信息率(EIR)
有效信息率衡量检索到的段落中相关信息的比例,确保检索过程在信息内容方面既准确又高效。
其中,( G_i )是第i个真实参考文本,( R_t )是检索到的总段落集合,m是成功匹配的真实参考文本数量,( |G_i \cap R_t| )表示第i个真实参考文本和检索到的段落( R_t )的交集中的单词数,仅在( G_i )在( R_t )中匹配时计算,( |R_j| )表示第j个检索到的段落中的总单词数,k是检索到的段落总数。
生成完整性(Completeness):完整性衡量生成答案捕捉真实关键信息的程度。使用大型语言模型(LLM)从真实文本中生成一组关键点K,然后计算完整性得分,即生成答案A语义覆盖关键点的比例:[ \textComp}(A, K) = \frac{1}{K|\sum_{i=1}^{n} \odot[A \text{ covers } k_i] ]
生成幻觉(Hallucination)
幻觉识别内容与关键点相矛盾的实例,突出潜在的不准确之处。
生成不相关性(Irrelevancy)
不相关性评估真实关键点中既未被覆盖也未被矛盾的比例。
InspectorRAGet: An Introspection Platform for RAG Evaluation
https://arxiv.org/abs/2404.17347
https://github.com/IBM/InspectorRAGet
INSPECTORRAGET专注于RAG评估生命周期的第三步,即分析实验结果。使用该平台分析实验时,模型开发人员或利益相关者需要上传一个标准化的JSON文件,总结实验结果。这个总结包含以下信息:

-
数据集:实验中包含的数据实例集合,每个实例包含用户输入、上下文和可选的参考响应。
-
模型元数据:被评估的RAG模型的名称和描述。
-
指标元数据:关于评估模型响应的指标的元数据。这些包括指标名称、类型(算法或人类评估)和量表(是/否、李克特量表、数字等)。
-
评估分数:每个数据实例上每个指标的模型评估分数。
RAGChecker: A Fine-grained Framework for Diagnosing Retrieval-Augmented Generation
https://arxiv.org/abs/2408.08067
https://github.com/amazon-science/RAGChecker
RAGChecker框架:基于声明级别的蕴含检查,涉及从回答和真实答案中提取声明,并检查它们是否与其他文本相匹配。

整体指标(Overall Metrics)
-
精确度(Precision):衡量模型生成回答中正确声明(claims)的比例。正确声明是指那些在真实答案(ground-truth answer)中也出现的声明。
-
召回率(Recall):衡量真实答案中正确声明在模型生成回答中被覆盖的比例。
-
F1分数(F1 Score):精确度和召回率的调和平均值,作为整体性能的度量指标。
检索器指标(Retriever Metrics)
-
声明召回率(Claim Recall):衡量检索到的文档片段(chunks)覆盖真实答案中声明的比例。
-
上下文精确度(Context Precision):在文档片段级别上定义,衡量检索到的片段中有多少是相关的(即包含真实答案中的声明)。
生成器指标(Generator Metrics)
-
忠实度(Faithfulness):衡量生成器对检索到的上下文的忠实程度,即生成回答中声明在检索到的文档片段中被支持的比例。
-
相关噪声敏感性(Relevant Noise Sensitivity):衡量生成器对包含有用信息的文档片段中噪声的敏感性,即错误声明在相关文档片段中的比例。
-
不相关噪声敏感性(Irrelevant Noise Sensitivity):衡量生成器对不相关文档片段中噪声的敏感性,即错误声明在不相关文档片段中的比例。
-
幻觉(Hallucination):衡量生成器生成的声明中,有多少不是由检索到的文档片段支持的比例。
-
自我知识(Self-knowledge):衡量生成器基于自身知识生成正确声明的能力,即不依赖于检索到的上下文而生成的正确声明的比例。
-
上下文利用(Context Utilization):衡量生成器使用检索到的相关上下文信息的程度,即检索到的上下文中被用于生成回答的声明的比例。
RAGProbe: An Automated Approach for Evaluating RAG Applications
https://arxiv.org/pdf/2409.19019
RAGProbe通过一个动机示例来说明评估RAG流程的需求,其中开发人员Jack正在为金融机构构建一个RAG流程,以便基于给定的文档集合回答问题。文章详细介绍了评估场景模式,包括文档采样策略、分块策略、分块采样策略、特定场景的提示、提示策略和可接受的评估指标。
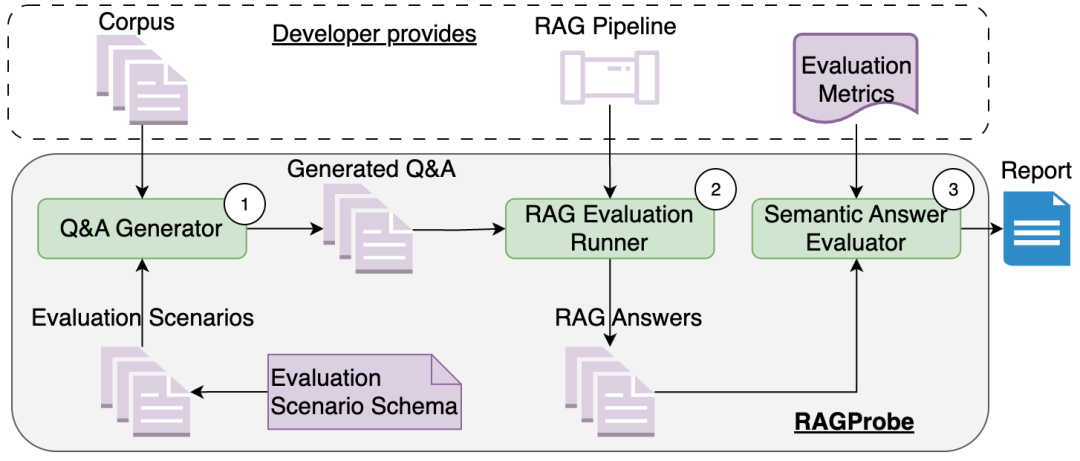

RAGProbe方法包括三个关键组件:问答生成器、RAG评估运行器和语义答案评估器。问答生成器根据评估场景模式从文档集合中生成问题和答案。RAG评估运行器适应RAG实现(处理认证和映射到API)并从RAG流程中收集所有生成问题的答案。语义答案评估器比较问答生成器生成的答案与RAG流程生成的答案。
Optimizing and Evaluating Enterprise Retrieval-Augmented Generation (RAG): A Content Design Perspective
https://arxiv.org/abs/2410.12812
文章讨论了在企业规模上构建和维护基于大型语言模型(LLMs)的检索增强生成(RAG)解决方案的实践经验。这些解决方案旨在根据产品文档回答用户关于软件的问题。作者指出,他们的经验与RAG文献中的常见模式并不总是一致,
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


尧米是由西云算力与CSDN联合运营的AI算力和模型开源社区品牌,为基于DaModel智算平台的AI应用企业和泛AI开发者提供技术交流与成果转化平台。
更多推荐



 8
8 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)