
细嗦Transformer(一): 整体架构及代码实现
所以更适合处理摘要生成,翻译等任务。解码器最后的输出需要经过全连接层,将最后一个DecoderLayer的输出映射成词表大小的向量,再经过Softmax得到词表中每个词的预测概率,概率最大的即为预测的词。Generator就是最后的模型输出部分,是最后的输出部分,经过一个标准线性变化,输入维度为,输入维度为 ,再经过Softmax,得到词表中每个词的概率。这里将子层也单独抽象成一个类表示,因为不管
文章目录
欢迎查看我的公众号原文
细嗦Transformer(一): 整体架构及代码实现
也欢迎关注我的公众号:
Transformer架构
Q1: 简单描述一下Transformer架构
Transformer模型由Encoder和Decoder两部分组成,Encoder和Decoder部分又分别是由多个encoder和decoder层堆叠而成。每个encoder层包含有两个子层,分别为多头注意力机制层和全连接前馈神经网络,在两个子层后分别添加残差连接和层归一化。每个decoder层结构与encoder类似,由3个子层组成,分别为掩码注意力、交叉注意力和全连接前馈神经网络。在输入部分都使用了正余弦位置编码,Decoder最后输出时还要经过一次线性变化和Softmax。
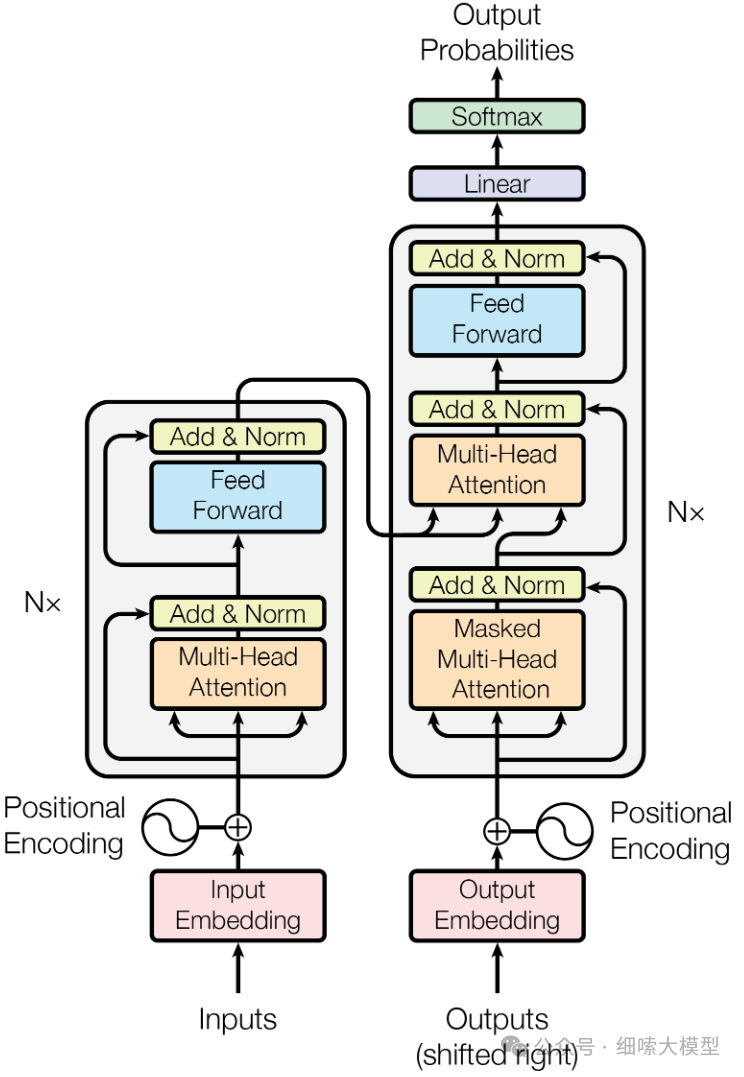
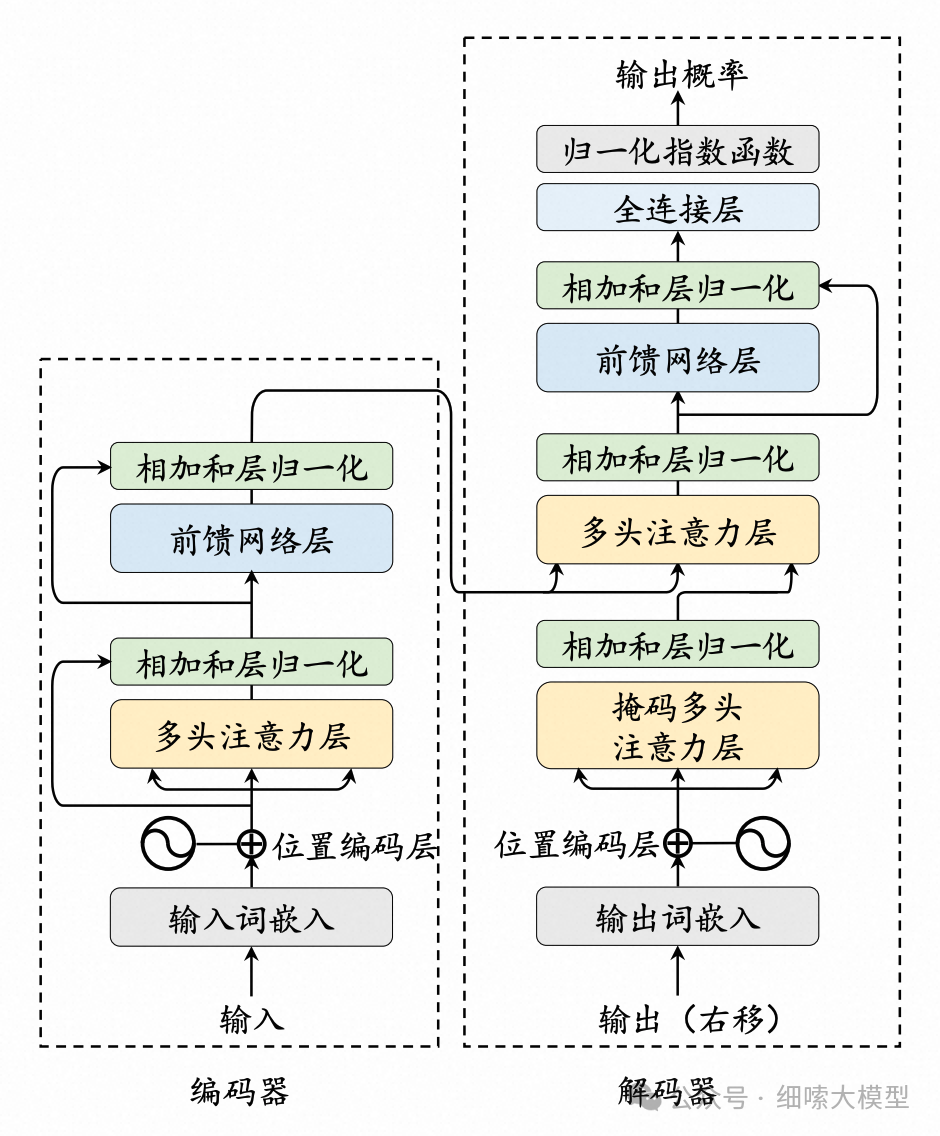
如果理解了这个架构图,那一定能够清晰地说出:
-
编码器和解码器分别由多个EncoderLayer和DecoderLayer堆叠而成。
-
一个EncoderLayer有2个子层,一个DecoderLayer有3个子层。
-
每个子层后面都有Add & Norm(残差连接和层归一化)
-
交叉注意力机制是接受编码器中最后一个EncoderLayer输出的 K , V K,V K,V, Q Q Q来自于掩码多头注意力层。
-
掩码注意力机制,掩盖大于等于i部分的序列。
-
编码器解码器输入部分都有位置编码,采用的是正余弦位置编码。
-
解码器最后的输出需要经过全连接层,将最后一个DecoderLayer的输出映射成词表大小的向量,再经过Softmax得到词表中每个词的预测概率,概率最大的即为预测的词。
Transformer架构代码实现
Transformer architecture
下面,我们按照自顶向下的顺序,搭建Transformer的整体框架,注意力机制等细节的实现,我们放到后续文章中实现。
Encoder-Decoder架构
下面是一个标准的Encoder-Decoder架构实现。是最后的输出部分,经过一个标准线性变化
class EncoderDecoder(nn.Module):
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(EncoderDecoder, self).__init__()
self.encoder = encoder # 编码器部分
self.decoder = decoder # 解码器部分
self.src_embed = src_embed # 编码器输入的嵌入层Embedding
self.tgt_embed = tgt_embed # 解码器输入的嵌入层Embedding
self.generator = generator # 最后的线性层和softmax层
def forward(self, src, tgt, src_mask, tgt_mask):
"Take in and process masked src and target sequences."
return self.decode(self.encode(src, src_mask), src_mask, tgt, tgt_mask)
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask) # Embedding完之后才传入编码器
def decode(self, memory, src_mask, tgt, tgt_mask):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask) # Embedding前面步骤生成的输出,将Encoder最后输出的key和value传入解码器
Generator就是最后的模型输出部分,是最后的输出部分,经过一个标准线性变化,输入维度为,输入维度为 ,再经过Softmax,得到词表中每个词的概率。
class Generator(nn.Module):
"Define standard linear + softmax generation step."
def __init__(self, d_model, vocab):
super(Generator, self).__init__()
self.proj = nn.Linear(d_model, vocab)
def forward(self, x):
return log_softmax(self.proj(x), dim=-1) # x维度为[batch_size, seq_len, vocab_size],在最后一个维度上进行softmax,然后取对数
Encoder编码器
核心部件Encoder是由N个EncoderLayer堆叠而成
# 层归一化
class Encoder(nn.Module):
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = nn.ModuleList([copy.deepcopy(layer) for _ in range(N)]) # 将同一个EncoderLayer拷贝N次
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
"Pass the input (and mask) through each layer in turn."
for layer in self.layers: # 逐层传入
x = layer(x, mask)
return x
EncoderLayer单个Encoder层
一个EncoderLayer是由两个子层组成,分别是自注意力层和前馈神经网络层。
class EncoderLayer(nn.Module):
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.sublayer = nn.ModuleList([copy.deepcopy(SublayerConnection(size, dropout)) for _ in range(2)]) # 2个子层
self.size = size
def forward(self, x, mask):
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask)) # 第一个sublayer是self-attention
return self.sublayer[1](x, self.feed_forward) # 第二个sublayer是feed forward
这里将子层也单独抽象成一个类表示,因为不管是EncoderLayer、还是DecoderLayer的子层,都需要经过残差连接和层归一化,是可以复用的。
class SublayerConnection(nn.Module):
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
return self.norm(x+ self.dropout(sublayer(x)))
Decoder解码器
与Encoder的实现同理,Decoder由多个DecoderLayer堆叠而成
class Decoder(nn.Module):
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = nn.ModuleList([copy.deepcopy(layer) for _ in range(N)]) # 将同一个DecoderLayer拷贝N次
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, src_mask, tgt_mask):
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
return x
DecoderLayer单个Decoder层
一个DecoderLayer由3个子层组成,分别是掩码注意力层、交叉注意力层和前馈神经网络层。
class DecoderLayer(nn.Module):
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn # 掩码注意力
self.src_attn = src_attn # 交叉注意力
self.feed_forward = feed_forward
self.sublayer = nn.ModuleList([copy.deepcopy(SublayerConnection(size, dropout)) for _ in range(3)]) # 3个子层
def forward(self, x, memory, src_mask, tgt_mask):
"Follow Figure 1 (right) for connections."
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask)) # 第一个sublayer是self-attention
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask)) # 第二个sublayer是交叉attention
return self.sublayer[2](x, self.feed_forward) # 第三个sublayer是feed forward
模型搭建 Model make
知道了编码器和解码器每一层都是如何定义的之后,我们来看看如何用这些组件搭建起一个完整的Encoder-Decoder模型。
构建模型时,我们只需要传入词表,EncoderLayer和DecoderLayer层数,d_model表示所有子层的输出维度,包括Embedding层、Attention层和Feed Forward层。d_ff为Feed Forward层中的隐藏层大小。h为Multi-Head Attention中的head数量。
def make_model(
src_vocab, tgt_vocab, N=6, d_model=512, d_ff=2048, h=8, dropout=0.1
):
c = copy.deepcopy
attn = MultiHeadedAttention(h, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
position = PositionalEncoding(d_model, dropout)
model = EncoderDecoder(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N),
Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout), N),
nn.Sequential(Embeddings(d_model, src_vocab), c(position)),
nn.Sequential(Embeddings(d_model, tgt_vocab), c(position)),
Generator(d_model, tgt_vocab),
)
# 初始化模型参数
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
return model
Transformer家族
下图为近几年来知名LLM的进化树,大都是基于Transformer发展而来,主要为Encoder-Only,Decoder-Only,Encoder-Decoder三个分支。在树中,同一分支上的模型关系更紧密。
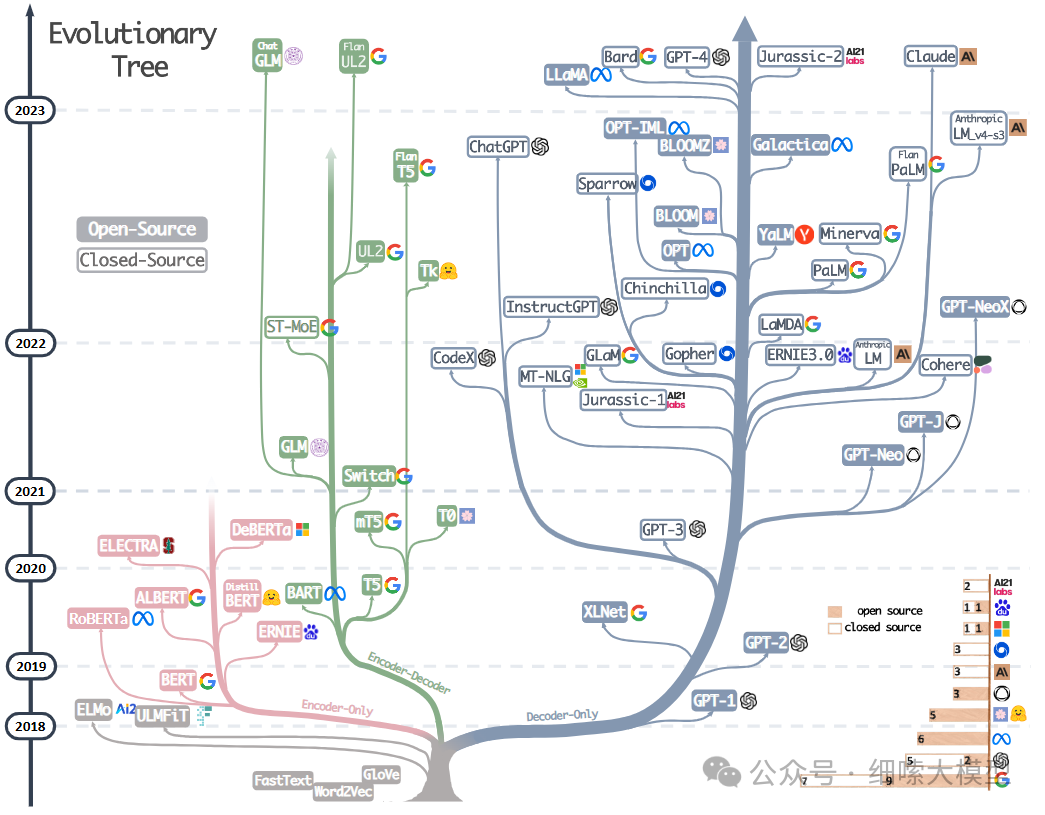
来源:A Survey on ChatGPT and Beyond
**Q2: ** 讲一下Encoder-Only、Decoder-Only、Encoder-Decoder三种模型架构之间的区别
三种模型架构,除了结构上的区别外,主要区别在于注意力机制层面。
-
Encoder-Decoder架构:既有Encoder的双向自注意力机制,对于pos位置的token,注意力机制可以同时关注pos位置前后的词,有丰富的上下文信息;在Decoder中为单向注意力,但能够使用Encoder输出的上下文信息,也就是结合Encoder部分的上下文,进行下一个词生成。所以更适合处理摘要生成,翻译等任务。
-
Decoder-Only架构:只有单向注意力机制,只能够基于前文进行生成。所以适合用来做文本生成、对话类型的任务,这也是为什么GPT系列和目前的大模型都是基于Decoder-Only架构。
-
E****ncoder-Only架构:只有双向注意力机制,能够学习到丰富的上下文信息,也就是会对上下文的充分理解后进行回答,所以适合句子分类,命名实体识别,抽取式问答等任务。
Transformer架构有点和缺点
优点
-
并行能力强。
-
捕捉长距离依赖关系,注意力机制可以更好的捕捉远距离的依赖关系,能够处理长文本。
-
通用性和灵活性好,不仅适用于NLP,还适用于计算机视觉(Vision Transformer)等领域。
缺点
-
计算和内存开销大,对计算机资源的要求较高
-
对于时间序列,一个单位时间的输出是从整个历史记录计算的,而非仅从输入和当前的隐含状态计算得到。这可能效率较低。
-
难以训练
-
可解释性问题

尧米是由西云算力与CSDN联合运营的AI算力和模型开源社区品牌,为基于DaModel智算平台的AI应用企业和泛AI开发者提供技术交流与成果转化平台。
更多推荐



 29
29 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)