
太强了!Ollama + MaxKB零代码本地搭建个人知识库AI应用,数据安全,还可以有权限控制!!
这种情况下,我们直接使用docker下载并启动MaxKB是无法成功的,此时我们需要让docker走我们的代理,去docker的官方仓储下载镜像。既然要系统的学习大模型,那么学习路线是必不可少的,下面的这份路线能帮助你快速梳理知识,形成自己的体系。下载模型默认走的是官网下载,有时候你的网络环境连不上官网,如果你通过代理可以链接官网,则先停止ollama的服务。作为普通人,入局大模型时代需要持续学习和
零代码本地搭建AI应用
📚 借助开源的,大模型应用不再遥不可及 🚀
当提到“大模型”和“本地部署”,很多人可能第一反应是:“这是不是只有那些顶尖的技术大牛才能搞定?”
其实,随着开源工具的发展,构建自己的大模型和知识库已经变得轻而易举,就像请一个聪明的私人助理帮你处理日常任务一样简单。
Ollama 和 MaxKB 就是这样一对黄金搭档,借助它们,你不需要深厚的技术背景,也能在本地搭建一个强大的 AI 系统。接下来,我们将带你一步步实现这个目标,让复杂的技术变得像拼积木一样简单。
💻 Ollama 和 MaxKB AI应用初体验
从日常的简单问答到复杂的知识调取,我们先来看看实际的效果。
-
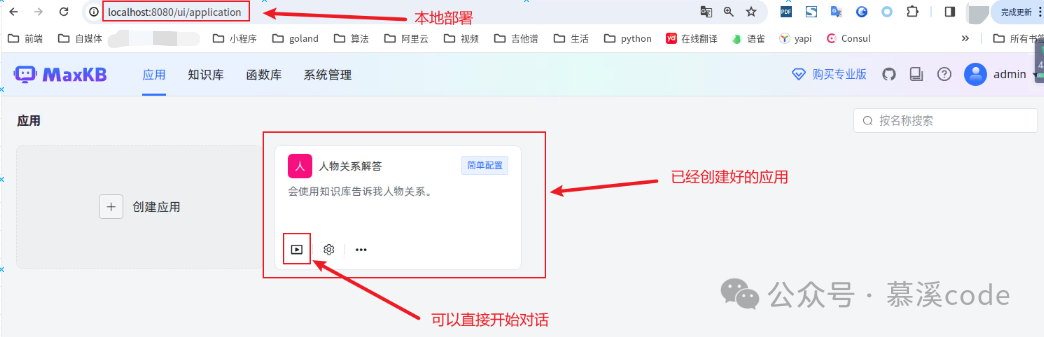
主页面:包括应用、知识库、函数库、管理
-
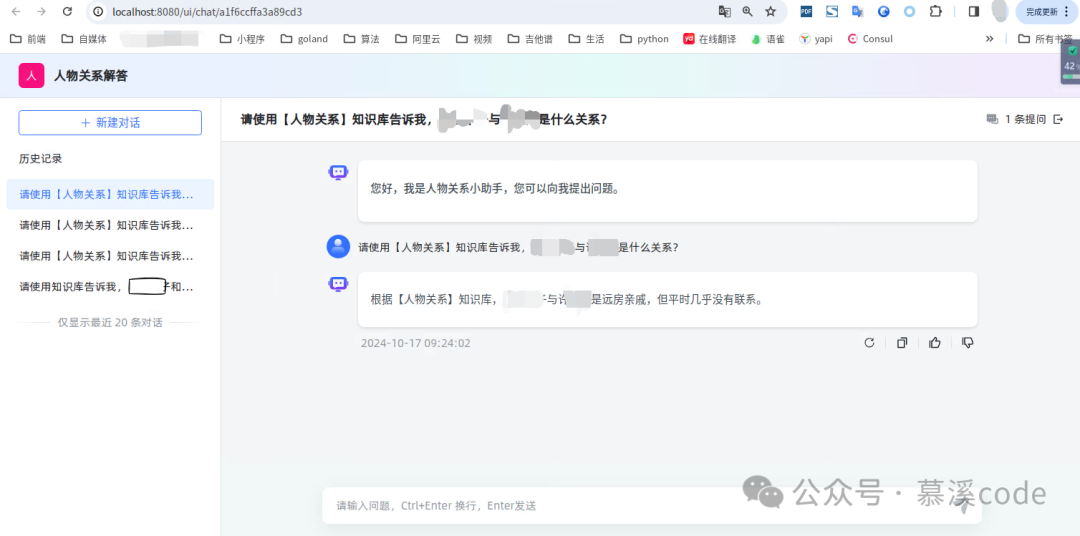
应用对话界面
-
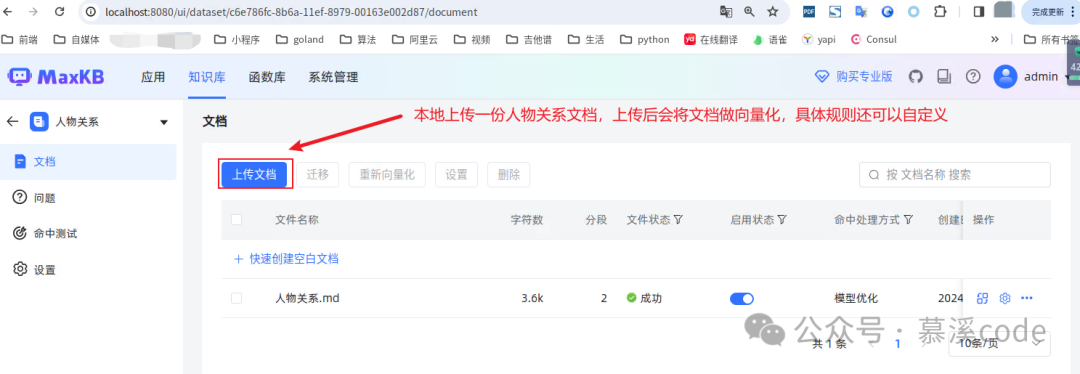
知识库
🤖后端智能“助理” :Ollama部署
Ollama 是一款开源的本地大模型应用工具,想象它就是一个超聪明的私人助理,随时待命为你解答问题。更重要的是,部署它并不像想象中那么复杂,只需几个步骤,你就可以让它在自己的设备上运行,数据完全掌控在自己手里。
下载安装 Ollama:为助理准备工作空间
要让助理为你工作,首先需要为 TA 准备一个“办公室”。这里的办公室就是 Ollama 的安装环境。我们会向你详细展示如何下载、安装和配置 Ollama,整个过程比你想象的要简单得多。
在线安装
如果你的网络条件允许,直接使用脚本安装:
curl -fsSL https://ollama.com/install.sh | sh
离线安装
安装命令
curl -L https://ollama.com/download/ollama-linux-amd64.tgz -o ollama-linux-amd64.tgz sudo tar -C /usr -xzf ollama-linux-amd64.tgz
-
-C后面的路径是安装目录,该路径根据自己的环境指定,需要注意目录权限问题,确保安装目录有权限。 -
如果没有curl命令,可以直接使用浏览器访问
https://ollama.com/download/ollama-linux-amd64.tgz,即可将模型下载到本地。如果不能访问下载地址,则需要先解决网络问题。 -
可以使用命令
ollama -v验证是否成功安装了ollama。安装成功会返回版本号,我的版本是:
ollama version is 0.3.13
启动 Ollama
ollama serve
-
安装成后后,直接使用上面的命令启动服务。
-
启动服务后,此时还未结束,需要安装大语言模型,本文章使用
llama3
安装启动大语言模型,并开启对话框
`ollama run llama3:8b`
-
执行该命令后,会去下载
llama3的模型,2G左右 -
下载模型默认走的是官网下载,有时候你的网络环境连不上官网,如果你通过代理可以链接官网,则先停止ollama的服务。配置临时的代理(不需要账号的去掉即可),然后重新启动:
export HTTP_PROXY="http://username:password@proxy.example.com:8080" export HTTPS_PROXY="http://username:password@proxy.example.com:8080" ollama serve -

🧠 本地知识库:MaxKB部署
有了聪明的助理,当然还要有一个系统化的知识存储和管理工具,这就是 MaxKB 的作用。它就像一个巨大的、智能化的文件柜,帮助你把所有知识条理清晰地归档,并且随时供助理调取。
在你的本地环境中安装 MaxKB 是创建这个超强“文件柜”的第一步。我们将逐步介绍如何通过命令行进行安装与配置。
docker安装
-
拉取镜像,并执行,官方的命令:
docker run -d --name=maxkb --restart=always -p 8080:8080 -v ~/.maxkb:/var/lib/postgresql/data -v ~/.python-packages:/opt/maxkb/app/sandbox/python-packages cr2.fit2cloud.com/1panel/maxkb
-
是可以启动的,但是连接不上我们的后端大模型llama3,需要修改命令,绑定主机网络,并且去掉端口映射。
docker run -d --net=host --name=maxkb --restart=always -v ~/.maxkb:/var/lib/postgresql/data -v ~/.python-packages:/opt/maxkb/app/sandbox/python-packages cr2.fit2cloud.com/1panel/maxkb
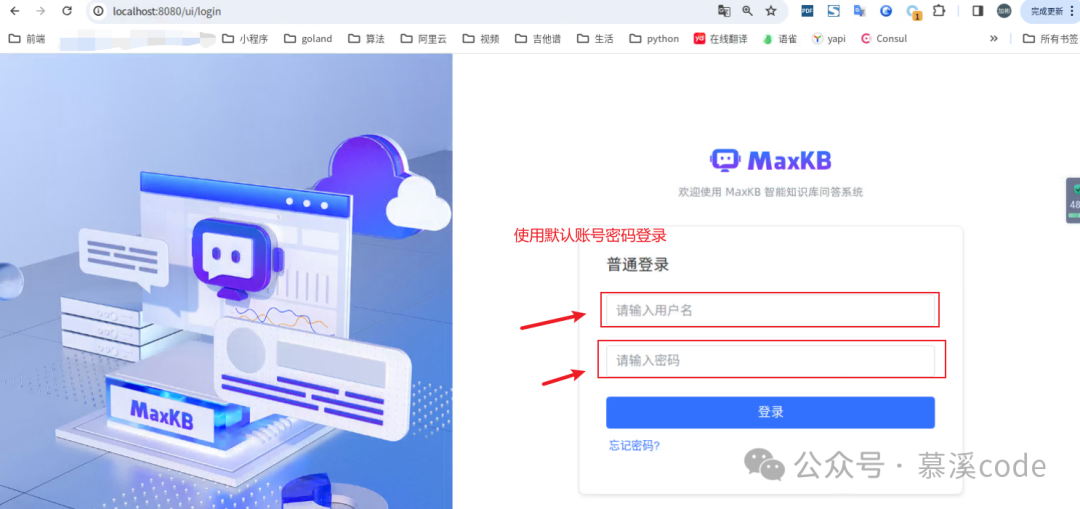
- 启动后,使用浏览器访问:
localhost:8080,即可看到登录页面,输入默认的账号密码即可进入主页面。
-
用户名: admin
-
密码: MaxKB@123…
-
-
此时你就可以看到主页面了,和下面的区别是,第一次进入是没有应用的。
docker配置代理
我们有时候会遇到网络的环境无法访问docker的官方仓储,但是我们可以使用代理访问。这种情况下,我们直接使用docker下载并启动MaxKB是无法成功的,此时我们需要让docker走我们的代理,去docker的官方仓储下载镜像。
要在内网环境下通过代理访问 Docker,并使用 docker pull 下载容器镜像,你可以通过配置 Docker 的代理设置来实现。以下是详细的步骤:
步骤 1:获取代理信息
确保你已经有了代理的地址和端口,通常是类似于以下格式:
-
HTTP 代理:
http://proxy.example.com:8080 -
HTTPS 代理:
https://proxy.example.com:8080
如果代理需要认证,你也需要用户名和密码:
http://username:password@proxy.example.com:8080
步骤 2:配置 Docker 代理
你需要为 Docker 守护进程配置代理环境变量。Docker 使用 systemd 管理服务,所以你需要修改其服务配置。
-
打开或创建 Docker 的服务目录:
bash复制代码sudo mkdir -p /etc/systemd/system/docker.service.d -
在该目录下创建一个名为
http-proxy.conf的文件:bash复制代码sudo nano /etc/systemd/system/docker.service.d/http-proxy.conf -
在文件中添加以下内容,根据你的代理类型(HTTP 或 HTTPS)填写相关的代理地址。如果你有 HTTP 和 HTTPS 代理,两个都可以配置,有些:
[Service] Environment="HTTP_PROXY=http://proxy.example.com:8080" Environment="HTTPS_PROXY=https://proxy.example.com:8080" Environment="NO_PROXY=localhost,127.0.0.1"如果代理需要认证,请将地址格式改为带有用户名和密码的形式:
bash复制代码Environment="HTTP_PROXY=http://username:password@proxy.example.com:8080" Environment="HTTPS_PROXY=https://username:password@proxy.example.com:8080" -
保存并关闭文件。
步骤 3:重新加载 Docker 守护进程
完成配置后,你需要重新加载 systemd 配置并重启 Docker 服务。
-
重新加载
systemd配置:bash复制代码sudo systemctl daemon-reload -
重启 Docker 服务:
bash复制代码sudo systemctl restart docker
知识管理信息按需归档
MaxKB 的强大之处在于它可以智能分类和整理各种信息。你只需要为它指引方向,剩下的归档工作 MaxKB 会自动完成。
-
先创建需要使用的知识库,流程皆有提示。
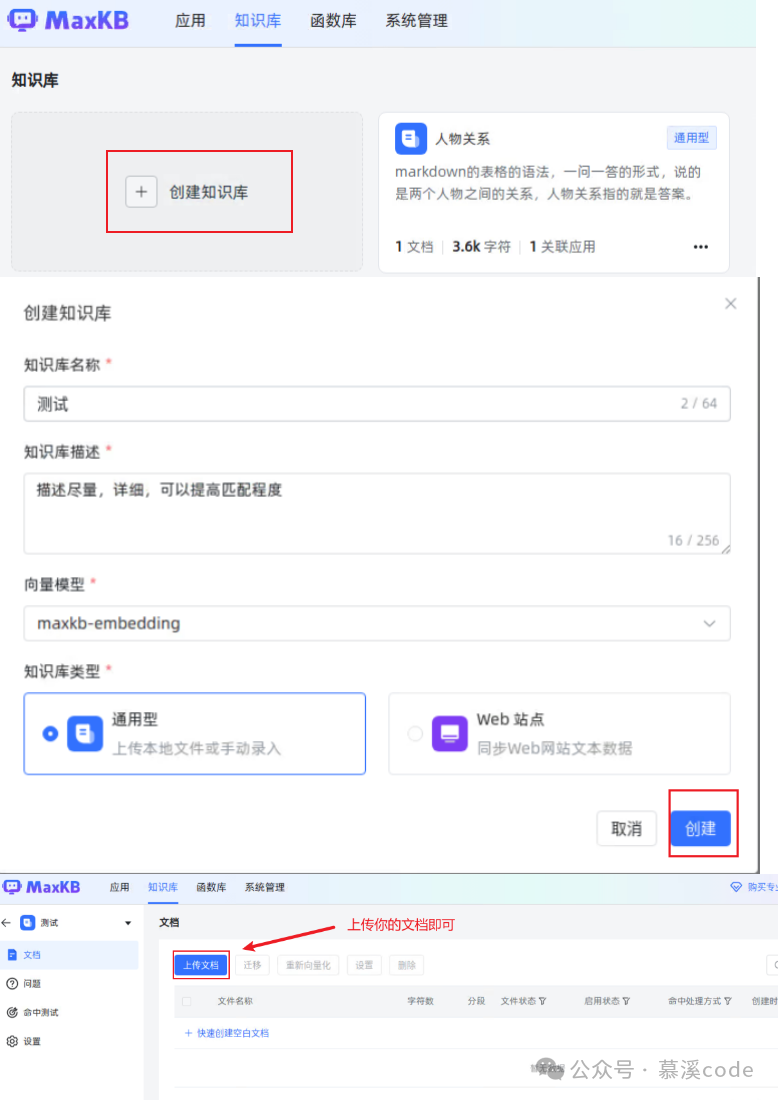
-
语料的整理:
-
建议使用markdown格式,做语料的文档
-
使用大模型优化语料,可以将你的原始资料,提供给大模型,让大模型帮你优化输出语料
创建属于你的应用
当 Ollama 和 MaxKB 配合起来,就像助理能够随时从文件柜中调取所需的资料。我们会引导你完成这两者的无缝整合,让系统智能化运作。
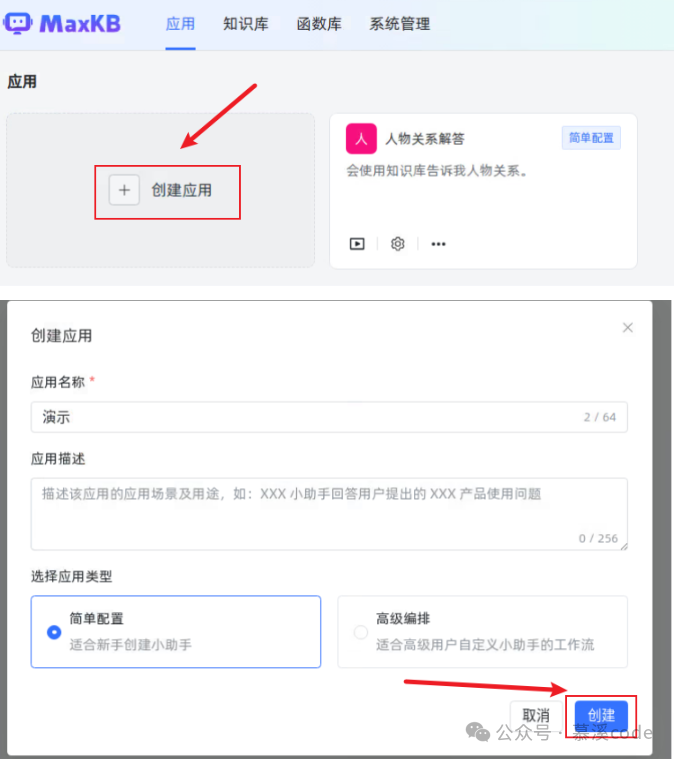
-
创建你的应用
-
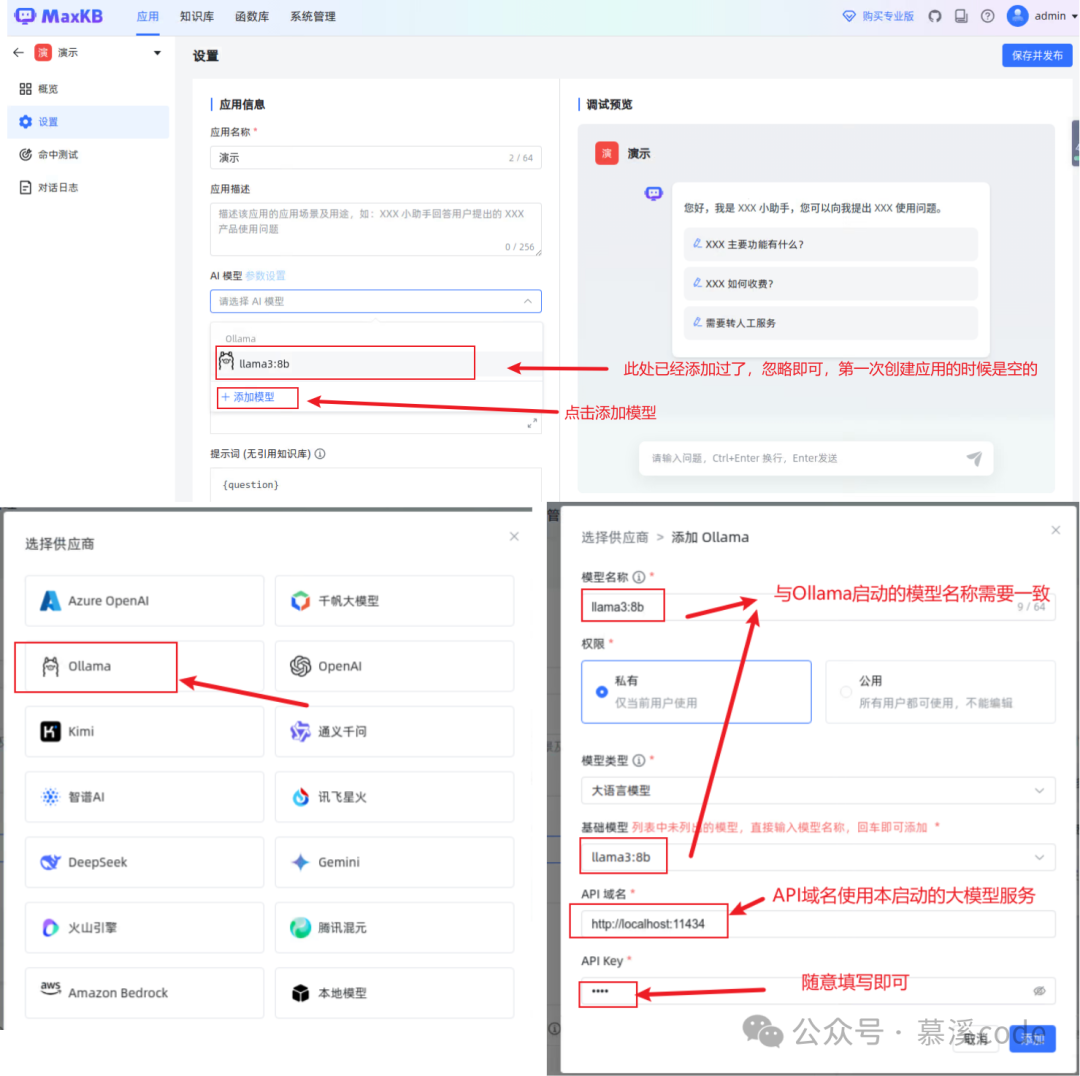
新增本地后端大模型。
-
绑定创建好的知识库
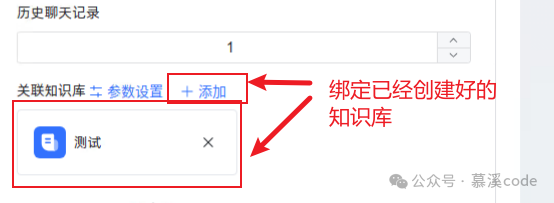
保存并发布你的应用,你的知识库AI应用就已经搭建完成啦!!!
一、大模型全套的学习路线
学习大型人工智能模型,如GPT-3、BERT或任何其他先进的神经网络模型,需要系统的方法和持续的努力。既然要系统的学习大模型,那么学习路线是必不可少的,下面的这份路线能帮助你快速梳理知识,形成自己的体系。
L1级别:AI大模型时代的华丽登场

L2级别:AI大模型API应用开发工程

L3级别:大模型应用架构进阶实践

L4级别:大模型微调与私有化部署

一般掌握到第四个级别,市场上大多数岗位都是可以胜任,但要还不是天花板,天花板级别要求更加严格,对于算法和实战是非常苛刻的。建议普通人掌握到L4级别即可。
以上的AI大模型学习路线,不知道为什么发出来就有点糊,高清版可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。
本文转自 https://blog.csdn.net/Everly_/article/details/143504581?spm=1001.2014.3001.5501,如有侵权,请联系删除。

尧米是由西云算力与CSDN联合运营的AI算力和模型开源社区品牌,为基于DaModel智算平台的AI应用企业和泛AI开发者提供技术交流与成果转化平台。
更多推荐


 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)