
PyTorch-完整的模型训练套路
模型训练
目录
1. 准备
1.1 使用Cifar10
1.2 item的用法
import torch
a = torch.tensor(3)
print(a)
print(a.item())
tensor(3)
3
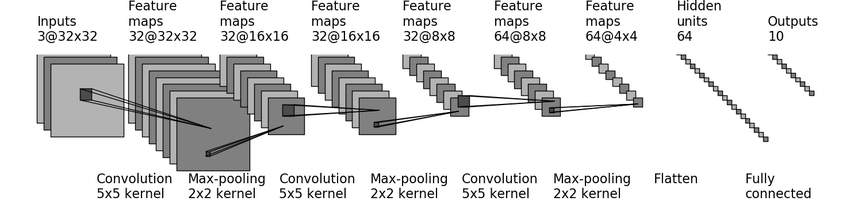
1.3 model的搭建
model.py
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
# 搭建神经网络
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.model = nn.Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
# 测试
if __name__ == '__main__':
myModule = MyModule()
input = torch.ones((64, 3, 32, 32))
output = myModule(input)
print(output.shape) # torch.Size([64, 10])
1.4 数据集、参数设置以及训练开始
train.py
import torch.optim.optimizer
import torchvision
from model import *
from torch.utils.data import DataLoader
# 1.数据集准备
train_data = torchvision.datasets.CIFAR10('../dataset', train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10('../dataset', train=False, transform=torchvision.transforms.ToTensor(),
download=True)
train_data_size = len(train_data)
test_data_size = len(test_data)
# print(train_data_size, test_data_size) # 50000 10000
# 2.加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 3.创建网络模型
myModule = MyModule()
# 4.损失函数
loss_fn = nn.CrossEntropyLoss()
# 5.优化器
learningRate = 1e-2
optimizer = torch.optim.SGD(myModule.parameters(), lr=learningRate)
# 6.设置训练网络的一些参数
total_train_step = 0 # 记录训练的次数
total_test_step = 0 # 记录测试的次数
epoch = 10 # 记录训练的轮数
for i in range(epoch):
# 开始训练
for data in train_dataloader:
imgs, targets = data
outputs = myModule(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
# a.梯度清零
optimizer.zero_grad()
loss.backward() # b.反向传播,拿到梯度
optimizer.step() # c.对参数进行优化
total_train_step = total_train_step + 1
print("训练次数: {},loss: {}".format(total_train_step, loss.item()))
Files already downloaded and verified
Files already downloaded and verified
训练次数: 1,loss: 2.291430711746216
训练次数: 2,loss: 2.294950485229492
训练次数: 3,loss: 2.3185925483703613
训练次数: 4,loss: 2.2968363761901855
训练次数: 5,loss: 2.30112886428833
训练次数: 6,loss: 2.3146629333496094
训练次数: 7,loss: 2.3073482513427734
训练次数: 8,loss: 2.3127682209014893......
1.5 测试集
目的:可以拿测试集来验证模型训练的怎么样了。
train.py
import torch.optim.optimizer
import torchvision
from model import *
from torch.utils.data import DataLoader
# 1.数据集准备
train_data = torchvision.datasets.CIFAR10('../dataset', train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10('../dataset', train=False, transform=torchvision.transforms.ToTensor(),
download=True)
train_data_size = len(train_data)
test_data_size = len(test_data)
# print(train_data_size, test_data_size) # 50000 10000
# 2.加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 3.创建网络模型
myModule = MyModule()
# 4.损失函数
loss_fn = nn.CrossEntropyLoss()
# 5.优化器
learningRate = 1e-2
optimizer = torch.optim.SGD(myModule.parameters(), lr=learningRate)
# 6.设置训练网络的一些参数
total_train_step = 0 # 记录训练的次数
total_test_step = 0 # 记录测试的次数
epoch = 10 # 记录训练的轮数
for i in range(epoch):
print("-----第{}轮训练开始-----".format(i + 1))
# 开始训练
for data in train_dataloader:
imgs, targets = data
outputs = myModule(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
# a.梯度清零
optimizer.zero_grad()
loss.backward() # b.反向传播,拿到梯度
optimizer.step() # c.对参数进行优化
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数: {},loss: {}".format(total_train_step, loss.item()))
# 测试步骤开始
# 这一部分没有梯度,不需要再调优参数
total_test_loss = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
outputs = myModule(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss
print("整体测试集上的Loss: {}".format(total_test_loss))
-----第1轮训练开始-----
训练次数: 100,loss: 2.298675060272217
训练次数: 200,loss: 2.285764694213867
训练次数: 300,loss: 2.2791736125946045
训练次数: 400,loss: 2.233513593673706
训练次数: 500,loss: 2.1184940338134766
训练次数: 600,loss: 2.019355297088623
训练次数: 700,loss: 2.0219309329986572
整体测试集上的Loss: 316.859619140625
-----第2轮训练开始-----
训练次数: 800,loss: 1.8966532945632935
训练次数: 900,loss: 1.8539228439331055
训练次数: 1000,loss: 1.9396780729293823
训练次数: 1100,loss: 1.9399535655975342
训练次数: 1200,loss: 1.6813435554504395
训练次数: 1300,loss: 1.6371924877166748
训练次数: 1400,loss: 1.744162678718567
训练次数: 1500,loss: 1.7939480543136597
整体测试集上的Loss: 296.5897216796875
1.6 使用tensorboard
目的:画出Loss曲线,Making sure gradient descent is working correctly.
train.py
import torch.optim.optimizer
import torchvision
from torch.utils.tensorboard import SummaryWriter
from model import *
from torch.utils.data import DataLoader
# 1.数据集准备
train_data = torchvision.datasets.CIFAR10('../dataset', train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10('../dataset', train=False, transform=torchvision.transforms.ToTensor(),
download=True)
train_data_size = len(train_data)
test_data_size = len(test_data)
# print(train_data_size, test_data_size) # 50000 10000
# 2.加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 3.创建网络模型
myModule = MyModule()
# 4.损失函数
loss_fn = nn.CrossEntropyLoss()
# 5.优化器
learningRate = 1e-2
optimizer = torch.optim.SGD(myModule.parameters(), lr=learningRate)
# 6.设置训练网络的一些参数
total_train_step = 0 # 记录训练的次数
total_test_step = 0 # 记录测试的次数
epoch = 10 # 记录训练的轮数
# 添加tensorboard
writer = SummaryWriter('logs_train')
for i in range(epoch):
print("-----第{}轮训练开始-----".format(i + 1))
# 开始训练
for data in train_dataloader:
imgs, targets = data
outputs = myModule(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
# a.梯度清零
optimizer.zero_grad()
loss.backward() # b.反向传播,拿到梯度
optimizer.step() # c.对参数进行优化
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数: {},loss: {}".format(total_train_step, loss.item()))
# 画出损失函数
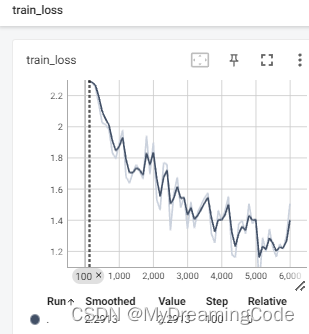
writer.add_scalar('train_loss', loss.item(), total_train_step)
# 测试步骤开始
# 这一部分没有梯度,不需要再调优参数
total_test_loss = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
outputs = myModule(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss
print("整体测试集上的Loss: {}".format(total_test_loss))
total_test_step = total_test_step + 1
writer.add_scalar('test_loss', total_test_loss, total_test_step)
writer.close()

1.7 保存每一轮的训练结果:
for i in range(epoch):
print("-----第{}轮训练开始-----".format(i + 1))
# 开始训练
for data in train_dataloader:
imgs, targets = data
outputs = myModule(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
# a.梯度清零
optimizer.zero_grad()
loss.backward() # b.反向传播,拿到梯度
optimizer.step() # c.对参数进行优化
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数: {},loss: {}".format(total_train_step, loss.item()))
# 画出损失函数
writer.add_scalar('train_loss', loss.item(), total_train_step)
# 测试步骤开始
# 这一部分没有梯度,不需要再调优参数
total_test_loss = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
outputs = myModule(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss
print("整体测试集上的Loss: {}".format(total_test_loss))
total_test_step = total_test_step + 1
writer.add_scalar('test_loss', total_test_loss, total_test_step)
# 保存每一轮训练的结果
torch.save(myModule, 'myModule_{}.pth'.format(i))
writer.close()
2. 计算整体的正确率
目的:查看训练的网络模型在测试集上的效果。
方法:预测正确的数量/整体的数量。
argmax:可以返回指定维度上最大值的索引。
test.py
import torch
outputs = torch.tensor([
[0.1, 0.2],
[0.3, 0.4]
])
# 填1的时候横向看,可以返回指定维度最大值的序号
preds = outputs.argmax(1)
targets = torch.tensor([0, 1])
print(preds == targets)
# 计算对应位置相等的个数
print((preds == targets).sum())
tensor([False, True])
tensor(1)
for i in range(epoch):
print("-----第{}轮训练开始-----".format(i + 1))
# 开始训练
for data in train_dataloader:
imgs, targets = data
outputs = myModule(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
# a.梯度清零
optimizer.zero_grad()
loss.backward() # b.反向传播,拿到梯度
optimizer.step() # c.对参数进行优化
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数: {},loss: {}".format(total_train_step, loss.item()))
# 画出损失函数
writer.add_scalar('train_loss', loss.item(), total_train_step)
# 测试步骤开始
# 这一部分没有梯度,不需要再调优参数
total_test_loss = 0
total_accuracy = 0 # 整体正确的个数
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
outputs = myModule(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss: {}".format(total_test_loss))
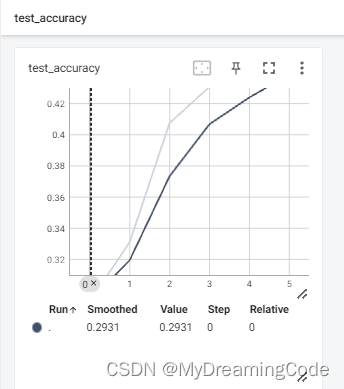
print("整体测试集上的正确率:{}".format(total_accuracy / test_data_size))
writer.add_scalar('test_accuracy', total_accuracy / test_data_size, total_test_step)
total_test_step = total_test_step + 1
writer.add_scalar('test_loss', total_test_loss, total_test_step)
# 保存每一轮训练的结果
torch.save(myModule, './model_save/myModule_{}.pth'.format(i))
writer.close()
Files already downloaded and verified
Files already downloaded and verified
-----第1轮训练开始-----
训练次数: 100,loss: 2.291329860687256
训练次数: 200,loss: 2.2846291065216064
训练次数: 300,loss: 2.2555723190307617
训练次数: 400,loss: 2.145618438720703
训练次数: 500,loss: 2.0252487659454346
训练次数: 600,loss: 2.0127859115600586
训练次数: 700,loss: 1.9800595045089722
整体测试集上的Loss: 307.11065673828125
整体测试集上的正确率:0.2930999994277954
-----第2轮训练开始-----
训练次数: 800,loss: 1.8316386938095093
训练次数: 900,loss: 1.7961711883544922
训练次数: 1000,loss: 1.8935333490371704
训练次数: 1100,loss: 1.9779611825942993
训练次数: 1200,loss: 1.679609775543213
训练次数: 1300,loss: 1.6376134157180786
训练次数: 1400,loss: 1.707167148590088
训练次数: 1500,loss: 1.7555652856826782
整体测试集上的Loss: 292.63409423828125
整体测试集上的正确率:0.3312000036239624
-----第3轮训练开始-----
训练次数: 1600,loss: 1.7143256664276123
训练次数: 1700,loss: 1.6653105020523071
训练次数: 1800,loss: 1.942317247390747
训练次数: 1900,loss: 1.697310209274292
训练次数: 2000,loss: 1.8977160453796387
训练次数: 2100,loss: 1.532772183418274
训练次数: 2200,loss: 1.4647372961044312
训练次数: 2300,loss: 1.7696183919906616
整体测试集上的Loss: 257.3481750488281
整体测试集上的正确率:0.4074999988079071......
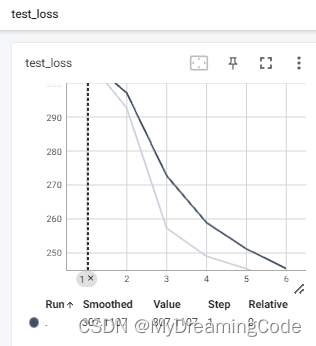
3. 其他
3.1 train与eval
它们对一些网络模型、层是有作用的。
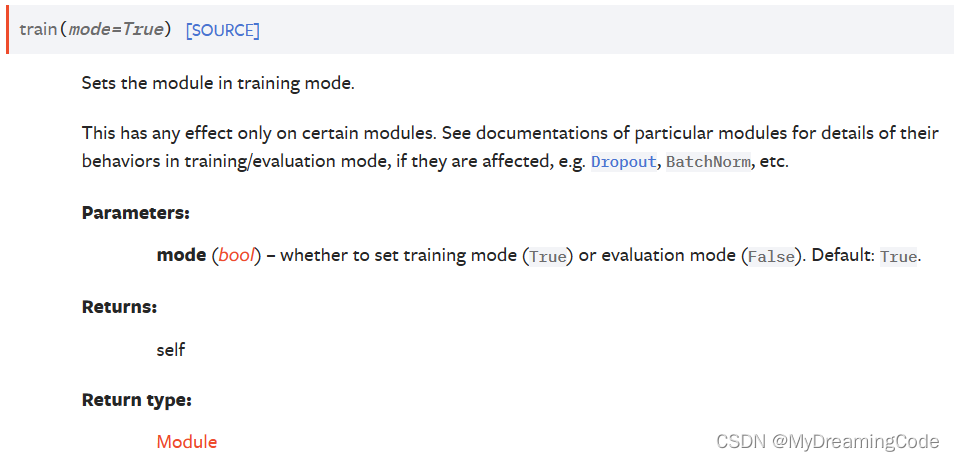
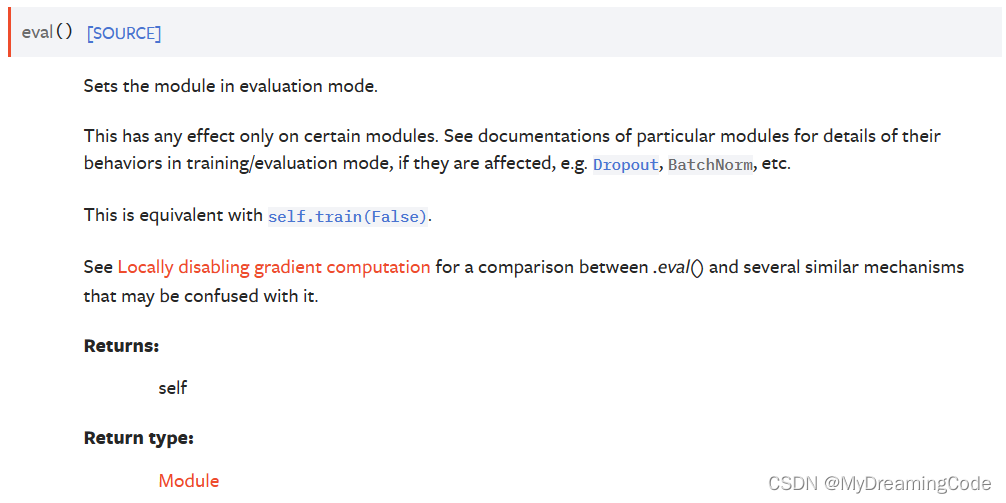
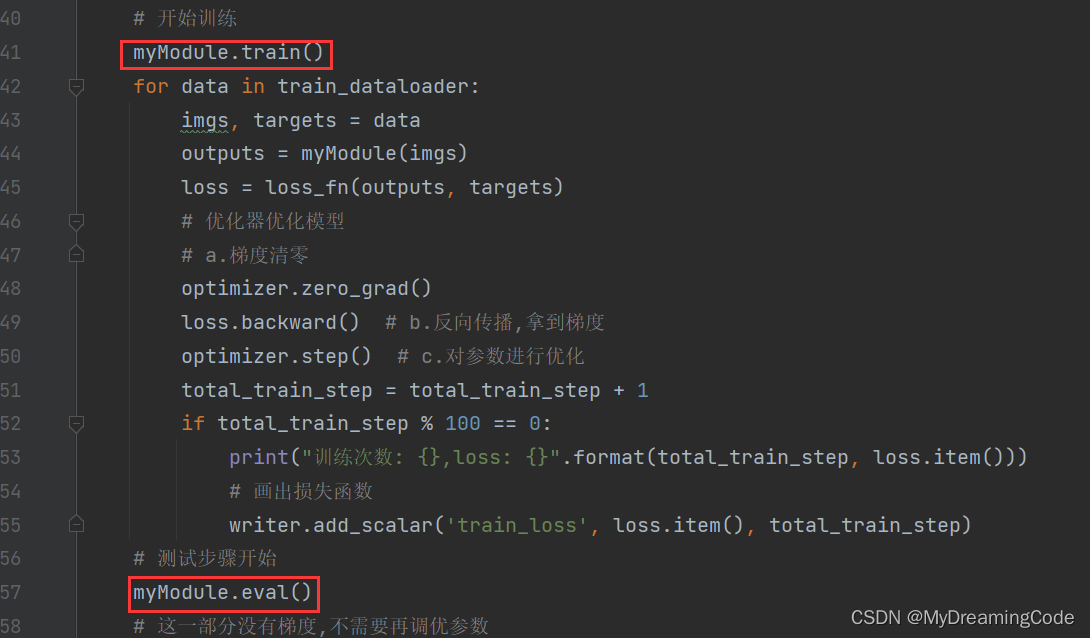
可以这样加入:
3.2 使用GPU训练
图片来源于:b站up主 我是土堆
方法一:

train_gpu_1.py
import torch.optim.optimizer
import torchvision
from torch.utils.tensorboard import SummaryWriter
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
# 1.数据集准备
train_data = torchvision.datasets.CIFAR10('../dataset', train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10('../dataset', train=False, transform=torchvision.transforms.ToTensor(),
download=True)
train_data_size = len(train_data)
test_data_size = len(test_data)
# print(train_data_size, test_data_size) # 50000 10000
# 2.加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 3.创建网络模型
# 搭建神经网络
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.model = nn.Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
myModule = MyModule()
if torch.cuda.is_available():
myModule = myModule.cuda()
# 4.损失函数
loss_fn = nn.CrossEntropyLoss()
if torch.cuda.is_available():
loss_fn = loss_fn.cuda()
# 5.优化器
learningRate = 1e-2
optimizer = torch.optim.SGD(myModule.parameters(), lr=learningRate)
# 6.设置训练网络的一些参数
total_train_step = 0 # 记录训练的次数
total_test_step = 0 # 记录测试的次数
epoch = 10 # 记录训练的轮数
# 添加tensorboard
writer = SummaryWriter('logs_train')
for i in range(epoch):
print("-----第{}轮训练开始-----".format(i + 1))
# 开始训练
myModule.train()
for data in train_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
outputs = myModule(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
# a.梯度清零
optimizer.zero_grad()
loss.backward() # b.反向传播,拿到梯度
optimizer.step() # c.对参数进行优化
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数: {},loss: {}".format(total_train_step, loss.item()))
# 画出损失函数
writer.add_scalar('train_loss', loss.item(), total_train_step)
# 测试步骤开始
myModule.eval()
# 这一部分没有梯度,不需要再调优参数
total_test_loss = 0
total_accuracy = 0 # 整体正确的个数
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
outputs = myModule(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss: {}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy / test_data_size))
writer.add_scalar('test_accuracy', total_accuracy / test_data_size, total_test_step)
total_test_step = total_test_step + 1
writer.add_scalar('test_loss', total_test_loss, total_test_step)
# 保存每一轮训练的结果
torch.save(myModule, './model_save/myModule_{}.pth'.format(i))
writer.close()
注:访问Google colaboratory, 可以免费使用GPU。
方法二:

import torch.optim.optimizer
import torchvision
from torch.utils.tensorboard import SummaryWriter
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
# 定义训练的设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 1.数据集准备
train_data = torchvision.datasets.CIFAR10('../dataset', train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10('../dataset', train=False, transform=torchvision.transforms.ToTensor(),
download=True)
train_data_size = len(train_data)
test_data_size = len(test_data)
# print(train_data_size, test_data_size) # 50000 10000
# 2.加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 3.创建网络模型
# 搭建神经网络
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.model = nn.Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
myModule = MyModule()
myModule = myModule.to(device)
# 4.损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
# 5.优化器
learningRate = 1e-2
optimizer = torch.optim.SGD(myModule.parameters(), lr=learningRate)
# 6.设置训练网络的一些参数
total_train_step = 0 # 记录训练的次数
total_test_step = 0 # 记录测试的次数
epoch = 10 # 记录训练的轮数
# 添加tensorboard
writer = SummaryWriter('logs_train')
for i in range(epoch):
print("-----第{}轮训练开始-----".format(i + 1))
# 开始训练
myModule.train()
for data in train_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = myModule(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
# a.梯度清零
optimizer.zero_grad()
loss.backward() # b.反向传播,拿到梯度
optimizer.step() # c.对参数进行优化
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数: {},loss: {}".format(total_train_step, loss.item()))
# 画出损失函数
writer.add_scalar('train_loss', loss.item(), total_train_step)
# 测试步骤开始
myModule.eval()
# 这一部分没有梯度,不需要再调优参数
total_test_loss = 0
total_accuracy = 0 # 整体正确的个数
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = myModule(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss: {}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy / test_data_size))
writer.add_scalar('test_accuracy', total_accuracy / test_data_size, total_test_step)
total_test_step = total_test_step + 1
writer.add_scalar('test_loss', total_test_loss, total_test_step)
# 保存每一轮训练的结果
torch.save(myModule, './model_save/myModule_{}.pth'.format(i))
writer.close()

尧米是由西云算力与CSDN联合运营的AI算力和模型开源社区品牌,为基于DaModel智算平台的AI应用企业和泛AI开发者提供技术交流与成果转化平台。
更多推荐



 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)