在ubuntu24.04上安装Ollama并设置跨域访问
Ollama 是一个基于 Go 语言开发的简单易用的本地大模型运行框架。它同时支持Nvidia和AMD显卡,最主要的是国内下载模型的速度很快。我们在前几期文章中介绍的lobechat,oneapi等应用,可以方便的利用ollama构建本地大模型运行平台。接下来我们就介绍如何构建ollama的运行平台。
Ollama 是一个基于 Go 语言开发的简单易用的本地大模型运行框架。它同时支持Nvidia和AMD显卡,最主要的是国内下载模型的速度很快。
我们在前几期文章中介绍的lobechat,oneapi等应用,可以方便的利用ollama构建本地大模型运行平台。接下来我们就介绍如何构建ollama的运行平台。
设备构成:
1、Nvidia P40两片,32G内存。
2、ubuntu24.04操作系统。
具体安装过程如下:
一:安装Ollama
1、准备环境
#安装gcc和g++
sudo apt update
sudo apt install gcc g++
#安装make
sudo apt install make
sudo apt install make-guile2、安装Nvidia驱动
#编辑黑名单配置。
vim /etc/modprobe.d/blacklist.conf
#在文件的最后添加下面两行。
blacklist nouveau
options nouveau modeset=0
#然后,输入下面的命令更新并重启。
update-initramfs -u
reboot
#重启后输入下面的命令验证是否禁用成功,成功的话这行命令不会有输出。
lsmod | grep nouveau
#驱动安装
#首先,使用apt卸载已有的驱动,命令如下。
apt-get purge nvidia*
#进入驱动所在路径,赋予执行权限,并执行安装命令
chmod +x NVIDIA-Linux-x86_64-535.86.05.run
./NVIDIA-Linux-x86_64-535.86.05.run3、安装cuda
#下载cuda
wget https://developer.download.nvidia.com/compute/cuda/12.4.0/local_installers/cuda_12.4.0_550.54.14_linux.run
#安装cuda
./cuda_12.4.0_550.54.14_linux.run设置环境变量
vim ~/.bashrc
在文件最下面加上这些
PATH=$PATH:/usr/local/cuda/bin
LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64
LIBRARY_PATH=$LIBRARY_PATH:/usr/local/cuda/lib64使生效
source ~/.bashrc4、安装cudnn
下载cudnn(需要自己注册用户),下载地址如下:
cuDNN Archive | NVIDIA Developer
安装cudnn
xz -d cudnn-linux-x86_64-8.9.4.25_cuda12-archive.tar.xz
tar -xvf cudnn-linux-x86_64-8.9.4.25_cuda12-archive.tar
cp /root/cudnn-linux-x86_64-8.9.4.25_cuda12-archive/include/cudnn.* /usr/local/cuda/include/
cp /root/cudnn-linux-x86_64-8.9.4.25_cuda12-archive/lib/* /usr/local/cuda/lib64/
chmod a+r /usr/local/cuda/include/cudnn*.h /usr/local/cuda/lib64/libcudnn*5、安装python环境
apt-get install python3 python3-pip6、安装ollama
curl -fsSL https://ollama.com/install.sh | sh
二:配置ollama跨域访问
vim /etc/systemd/system/ollama.service修改成下面这样
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="OLLAMA_HOST=0.0.0.0"
Environment="OLLAMA_ORIGINS=*"
[Install]
WantedBy=default.target可以使用ollama --version再次确认安装是否成功。

重新加载systemd守护进程并启用Ollama服务
sudo systemctl daemon-reload
sudo systemctl enable ollama
sudo systemctl start ollama三:Ollama基本操作
1、下载模型
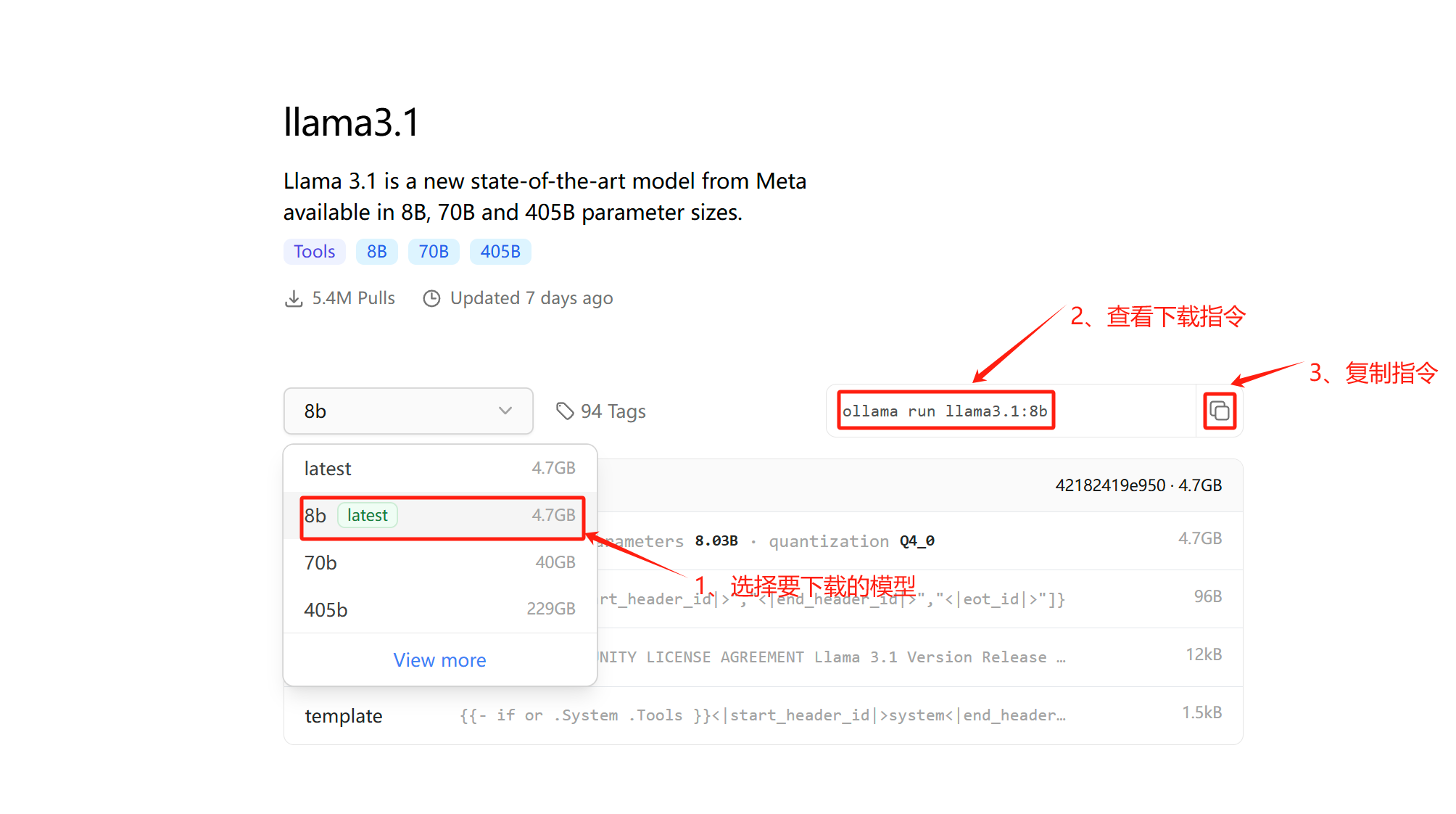
ollama run llama3.1:8b仅拉取镜像,但不运行
ollama pull llama3.1:8b2、删除模型
#显示安装的模型列表
ollama list
#删除指定的模型
ollama rm llama3.1:8b3、卸载ollama
删除systemd中创建的ollama服务
sudo systemctl stop ollama
sudo systemctl disable ollama
sudo rm /etc/systemd/system/ollama.service
sudo systemctl daemon-reload删除ollama的二进制文件
sudo rm /usr/local/bin/ollama
删除用户和组
sudo userdel ollama
sudo groupdel ollama

尧米是由西云算力与CSDN联合运营的AI算力和模型开源社区品牌,为基于DaModel智算平台的AI应用企业和泛AI开发者提供技术交流与成果转化平台。
更多推荐


 15
15 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)