Transformers 4.37 中文文档(九十二)
原文:huggingface.co/docs/transformersOWLv2原始文本:huggingface.co/docs/transformers/v4.37.2/en/model_doc/owlv2概述OWLv2 是由 Matthias Minderer、Alexey Gritsenko 和 Neil Houlsby 在《扩展开放词汇目标检测》中提出的。OWLv2 通过自训练扩展了 OW
OWLv2
原始文本:
huggingface.co/docs/transformers/v4.37.2/en/model_doc/owlv2
概述
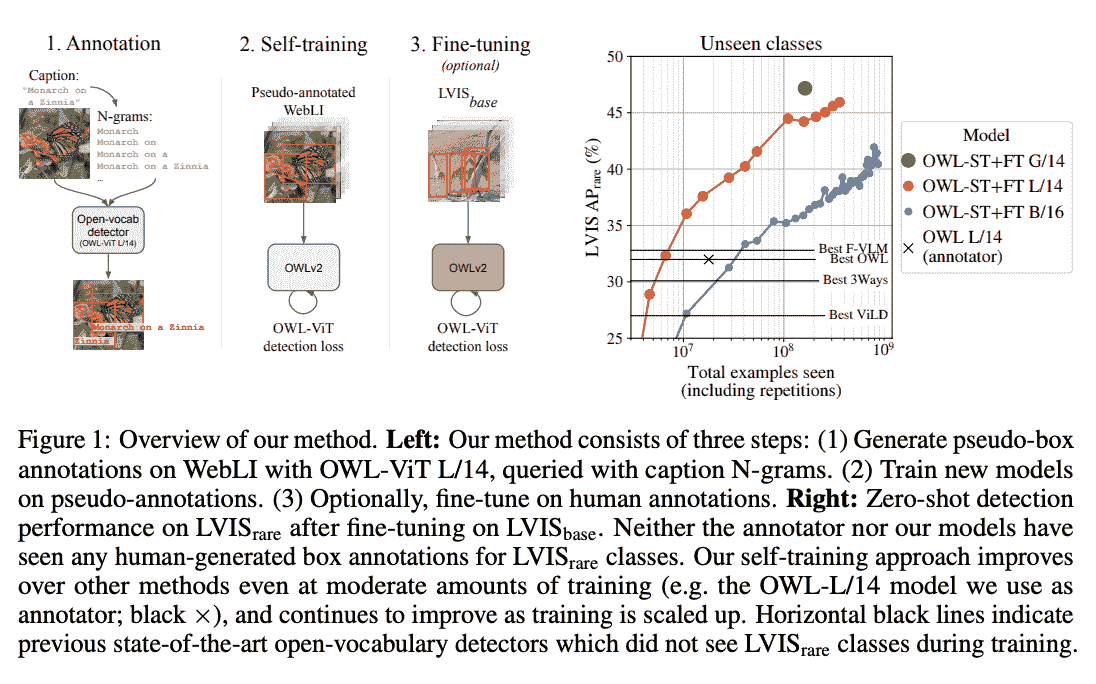
OWLv2 是由 Matthias Minderer、Alexey Gritsenko 和 Neil Houlsby 在《扩展开放词汇目标检测》中提出的。OWLv2 通过自训练扩展了 OWL-ViT,利用现有的检测器在图像-文本对上生成伪框注释。这导致在零样本目标检测方面取得了比先前最先进技术的巨大进展。
该论文的摘要如下:
开放词汇目标检测受益于预训练的视觉语言模型,但仍受到可用检测训练数据量的限制。虽然可以通过使用 Web 图像-文本对作为弱监督来扩展检测训练数据,但这在可比较于图像级预训练的规模上尚未实现。在这里,我们通过自训练扩展检测数据,利用现有的检测器在图像-文本对上生成伪框注释。在扩展自训练中的主要挑战是标签空间的选择、伪注释过滤和训练效率。我们提出了 OWLv2 模型和 OWL-ST 自训练配方,以解决这些挑战。OWLv2 在可比较的训练规模下(约 1000 万个示例)已经超越了先前最先进的开放词汇检测器的性能。然而,通过 OWL-ST,我们可以扩展到超过 10 亿个示例,进一步取得了巨大的改进:在 L/14 架构下,OWL-ST 将 LVIS 稀有类别的 AP 从 31.2%提高到 44.6%(相对改进 43%)。OWL-ST 为开放世界定位解锁了 Web 规模的训练,类似于图像分类和语言建模所见到的情况。
 OWLv2 高层次概述。摘自原始论文。
OWLv2 高层次概述。摘自原始论文。
用法示例
OWLv2 就像其前身 OWL-ViT 一样,是一个零样本文本条件的目标检测模型。OWL-ViT 使用 CLIP 作为其多模态骨干,具有类似 ViT 的 Transformer 来获取视觉特征和因果语言模型来获取文本特征。为了将 CLIP 用于检测,OWL-ViT 移除了视觉模型的最终标记池化层,并将轻量级分类和框头附加到每个 Transformer 输出标记上。通过用从文本模型获得的类名嵌入替换固定的分类层权重,实现了开放词汇分类。作者首先从头开始训练 CLIP,然后使用二部匹配损失在标准检测数据集上端到端地微调它,包括分类和框头。每个图像可以使用一个或多个文本查询来执行零样本文本条件的目标检测。
Owlv2ImageProcessor 可用于调整(或重新缩放)和规范化模型的图像,而 CLIPTokenizer 用于编码文本。Owlv2Processor 将 Owlv2ImageProcessor 和 CLIPTokenizer 包装成单个实例,以便同时编码文本和准备图像。以下示例展示了如何使用 Owlv2Processor 和 Owlv2ForObjectDetection 执行目标检测。
>>> import requests
>>> from PIL import Image
>>> import torch
>>> from transformers import Owlv2Processor, Owlv2ForObjectDetection
>>> processor = Owlv2Processor.from_pretrained("google/owlv2-base-patch16-ensemble")
>>> model = Owlv2ForObjectDetection.from_pretrained("google/owlv2-base-patch16-ensemble")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = [["a photo of a cat", "a photo of a dog"]]
>>> inputs = processor(text=texts, images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> # Target image sizes (height, width) to rescale box predictions [batch_size, 2]
>>> target_sizes = torch.Tensor([image.size[::-1]])
>>> # Convert outputs (bounding boxes and class logits) to Pascal VOC Format (xmin, ymin, xmax, ymax)
>>> results = processor.post_process_object_detection(outputs=outputs, target_sizes=target_sizes, threshold=0.1)
>>> i = 0 # Retrieve predictions for the first image for the corresponding text queries
>>> text = texts[i]
>>> boxes, scores, labels = results[i]["boxes"], results[i]["scores"], results[i]["labels"]
>>> for box, score, label in zip(boxes, scores, labels):
... box = [round(i, 2) for i in box.tolist()]
... print(f"Detected {text[label]} with confidence {round(score.item(), 3)} at location {box}")
Detected a photo of a cat with confidence 0.614 at location [341.67, 17.54, 642.32, 278.51]
Detected a photo of a cat with confidence 0.665 at location [6.75, 38.97, 326.62, 354.85]
资源
-
可以在这里找到使用 OWLv2 进行零样本和一次性(图像引导)目标检测的演示笔记本。
-
零样本目标检测任务指南
OWLv2 的架构与 OWL-ViT 相同,但是目标检测头现在还包括一个物体性分类器,用于预测(与查询无关的)预测框包含物体(而不是背景)的可能性。物体性分数可用于独立于文本查询对预测进行排名或过滤。使用 OWLv2 与 OWL-ViT 相同,但使用新的、更新的图像处理器(Owlv2ImageProcessor)。
Owlv2Config
class transformers.Owlv2Config
( text_config = None vision_config = None projection_dim = 512 logit_scale_init_value = 2.6592 return_dict = True **kwargs )
参数
-
text_config(dict, 可选) — 用于初始化 Owlv2TextConfig 的配置选项字典。 -
vision_config(dict, 可选) — 用于初始化 Owlv2VisionConfig 的配置选项字典。 -
projection_dim(int, 可选, 默认为 512) — 文本和视觉投影层的维度。 -
logit_scale_init_value(float, 可选, 默认为 2.6592) — logit_scale 参数的初始值。默认值与原始 OWLv2 实现相同。 -
return_dict(bool, 可选, 默认为True) — 模型是否应返回一个字典。如果为False,则返回一个元组。 -
kwargs(可选) — 关键字参数的字典。
Owlv2Config 是存储 Owlv2Model 配置的配置类。它用于根据指定的参数实例化一个 OWLv2 模型,定义文本模型和视觉模型配置。使用默认值实例化配置将产生类似于 OWLv2 google/owlv2-base-patch16 架构的配置。
配置对象继承自 PretrainedConfig ,可用于控制模型输出。阅读来自 PretrainedConfig 的文档以获取更多信息。
from_text_vision_configs
( text_config: Dict vision_config: Dict **kwargs ) → export const metadata = 'undefined';Owlv2Config
返回
Owlv2Config
配置对象的实例
从 owlv2 文本模型配置和 owlv2 视觉模型配置实例化一个 Owlv2Config(或派生类)。
Owlv2TextConfig
class transformers.Owlv2TextConfig
( vocab_size = 49408 hidden_size = 512 intermediate_size = 2048 num_hidden_layers = 12 num_attention_heads = 8 max_position_embeddings = 16 hidden_act = 'quick_gelu' layer_norm_eps = 1e-05 attention_dropout = 0.0 initializer_range = 0.02 initializer_factor = 1.0 pad_token_id = 0 bos_token_id = 49406 eos_token_id = 49407 **kwargs )
参数
-
vocab_size(int, optional, defaults to 49408) — OWLv2 文本模型的词汇量。定义了在调用 Owlv2TextModel 时可以表示的不同标记的数量。 -
hidden_size(int, optional, defaults to 512) — 编码器层和池化器层的维度。 -
intermediate_size(int, optional, defaults to 2048) — Transformer 编码器中“中间”(即前馈)层的维度。 -
num_hidden_layers(int, optional, defaults to 12) — Transformer 编码器中的隐藏层数。 -
num_attention_heads(int, optional, defaults to 8) — Transformer 编码器中每个注意力层的注意力头数。 -
max_position_embeddings(int, optional, defaults to 16) — 该模型可能使用的最大序列长度。通常将其设置为较大的值以防万一(例如 512、1024 或 2048)。 -
hidden_act(strorfunction, optional, defaults to"quick_gelu") — 编码器和池化器中的非线性激活函数(函数或字符串)。如果是字符串,支持"gelu"、"relu"、"selu"和"gelu_new"以及"quick_gelu"。 -
layer_norm_eps(float, optional, defaults to 1e-05) — 层归一化层使用的 epsilon。 -
attention_dropout(float, optional, defaults to 0.0) — 注意力概率的丢弃比率。 -
initializer_range(float, optional, defaults to 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 -
initializer_factor(float, optional, defaults to 1.0) — 用于初始化所有权重矩阵的因子(应保持为 1,用于内部初始化测试)。 -
pad_token_id(int, optional, defaults to 0) — 输入序列中填充标记的 id。 -
bos_token_id(int, optional, defaults to 49406) — 输入序列中序列开始标记的 id。 -
eos_token_id(int, optional, defaults to 49407) — 输入序列中序列结束标记的 id。
这是用于存储 Owlv2TextModel 配置的配置类。根据指定的参数实例化一个 Owlv2 文本编码器,定义模型架构。使用默认值实例化配置将产生类似于 Owlv2 google/owlv2-base-patch16架构的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读 PretrainedConfig 的文档以获取更多信息。
示例:
>>> from transformers import Owlv2TextConfig, Owlv2TextModel
>>> # Initializing a Owlv2TextModel with google/owlv2-base-patch16 style configuration
>>> configuration = Owlv2TextConfig()
>>> # Initializing a Owlv2TextConfig from the google/owlv2-base-patch16 style configuration
>>> model = Owlv2TextModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
Owlv2VisionConfig
class transformers.Owlv2VisionConfig
( hidden_size = 768 intermediate_size = 3072 num_hidden_layers = 12 num_attention_heads = 12 num_channels = 3 image_size = 768 patch_size = 16 hidden_act = 'quick_gelu' layer_norm_eps = 1e-05 attention_dropout = 0.0 initializer_range = 0.02 initializer_factor = 1.0 **kwargs )
参数
-
hidden_size(int, optional, defaults to 768) — 编码器层和池化器层的维度。 -
intermediate_size(int, optional, defaults to 3072) — Transformer 编码器中“中间”(即前馈)层的维度。 -
num_hidden_layers(int, optional, defaults to 12) — Transformer 编码器中的隐藏层数。 -
num_attention_heads(int, optional, defaults to 12) — Transformer 编码器中每个注意力层的注意力头数。 -
num_channels(int, optional, defaults to 3) — 输入图像中的通道数。 -
image_size(int, optional, defaults to 768) — 每个图像的大小(分辨率)。 -
patch_size(int, optional, defaults to 16) — 每个补丁的大小(分辨率)。 -
hidden_act(strorfunction, optional, defaults to"quick_gelu") — 编码器和池化器中的非线性激活函数(函数或字符串)。如果是字符串,支持"gelu"、"relu"、"selu"和"gelu_new"以及"quick_gelu"。 -
layer_norm_eps(float, optional, defaults to 1e-05) — 层归一化层使用的 epsilon。 -
attention_dropout(float, optional, defaults to 0.0) — 注意力概率的丢弃比率。 -
initializer_range(float, optional, defaults to 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 -
initializer_factor(float, optional, defaults to 1.0) — 用于初始化所有权重矩阵的因子(应保持为 1,用于内部初始化测试)。
这是一个配置类,用于存储 Owlv2VisionModel 的配置。根据指定的参数实例化一个 OWLv2 图像编码器,定义模型架构。使用默认值实例化配置将产生类似于 OWLv2 google/owlv2-base-patch16 架构的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读 PretrainedConfig 的文档以获取更多信息。
示例:
>>> from transformers import Owlv2VisionConfig, Owlv2VisionModel
>>> # Initializing a Owlv2VisionModel with google/owlv2-base-patch16 style configuration
>>> configuration = Owlv2VisionConfig()
>>> # Initializing a Owlv2VisionModel model from the google/owlv2-base-patch16 style configuration
>>> model = Owlv2VisionModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
Owlv2ImageProcessor
class transformers.Owlv2ImageProcessor
( do_rescale: bool = True rescale_factor: Union = 0.00392156862745098 do_pad: bool = True do_resize: bool = True size: Dict = None resample: Resampling = <Resampling.BILINEAR: 2> do_normalize: bool = True image_mean: Union = None image_std: Union = None **kwargs )
参数
-
do_rescale(bool, optional, defaults toTrue) — 是否按指定的比例rescale_factor对图像进行重新缩放。可以被preprocess方法中的do_rescale覆盖。 -
rescale_factor(intorfloat, optional, defaults to1/255) — 如果重新缩放图像,要使用的缩放因子。可以被preprocess方法中的rescale_factor覆盖。 -
do_pad(bool, optional, defaults toTrue) — 是否将图像填充为带有灰色像素的正方形,位于底部和右侧。可以被preprocess方法中的do_pad覆盖。 -
do_resize(bool, optional, defaults toTrue) — 控制是否将图像的(高度、宽度)尺寸调整为指定的size。可以被preprocess方法中的do_resize覆盖。 -
size(Dict[str, int]optional, defaults to{"height" -- 960, "width": 960}): 要调整图像大小到的尺寸。可以被preprocess方法中的size覆盖。 -
resample(PILImageResampling, optional, defaults toResampling.BILINEAR) — 如果调整图像大小,要使用的重采样方法。可以被preprocess方法中的resample覆盖。 -
do_normalize(bool, optional, defaults toTrue) — 是否对图像进行归一化。可以被preprocess方法中的do_normalize参数覆盖。 -
image_mean(floatorList[float], optional, defaults toOPENAI_CLIP_MEAN) — 如果对图像进行归一化要使用的均值。这是一个浮点数或与图像通道数相同长度的浮点数列表。可以被preprocess方法中的image_mean参数覆盖。 -
image_std(float或List[float], optional, 默认为OPENAI_CLIP_STD) — 如果对图像进行归一化,则使用的标准差。这是一个浮点数或与图像中通道数相同长度的浮点数列表。可以被preprocess方法中的image_std参数覆盖。
构建一个 OWLv2 图像处理器。
preprocess
( images: Union do_pad: bool = None do_resize: bool = None size: Dict = None do_rescale: bool = None rescale_factor: float = None do_normalize: bool = None image_mean: Union = None image_std: Union = None return_tensors: Union = None data_format: ChannelDimension = <ChannelDimension.FIRST: 'channels_first'> input_data_format: Union = None **kwargs )
参数
-
images(ImageInput) — 要预处理的图像。期望单个或批量的像素值范围为 0 到 255 的图像。如果传入像素值在 0 到 1 之间的图像,请设置do_rescale=False。 -
do_pad(bool, optional, 默认为self.do_pad) — 是否将图像填充为带有灰色像素的正方形,位于底部和右侧。 -
do_resize(bool, optional, 默认为self.do_resize) — 是否调整图像大小。 -
size(Dict[str, int], optional, 默认为self.size) — 调整图像大小的尺寸。 -
do_rescale(bool, optional, defaults toself.do_rescale) — 是否将图像值重新缩放到[0-1]之间。 -
rescale_factor(float, optional, 默认为self.rescale_factor) — 如果do_rescale设置为True,则重新缩放图像的重新缩放因子。 -
do_normalize(bool, optional, 默认为self.do_normalize) — 是否对图像进行归一化。 -
image_mean(float或List[float], optional, 默认为self.image_mean) — 图像均值。 -
image_std(float或List[float], optional, 默认为self.image_std) — 图像标准差。 -
return_tensors(str或TensorType, optional) — 要返回的张量类型。可以是以下之一:-
未设置:返回一个
np.ndarray列表。 -
TensorType.TENSORFLOW或'tf': 返回类型为tf.Tensor的批次。 -
TensorType.PYTORCH或'pt': 返回类型为torch.Tensor的批次。 -
TensorType.NUMPY或'np': 返回类型为np.ndarray的批次。 -
TensorType.JAX或'jax': 返回类型为jax.numpy.ndarray的批次。
-
-
data_format(ChannelDimension或str, optional, 默认为ChannelDimension.FIRST) — 输出图像的通道维度格式。可以是以下之一:-
"channels_first"或ChannelDimension.FIRST: 图像格式为(num_channels, height, width)。 -
"channels_last"或ChannelDimension.LAST: 图像格式为(height, width, num_channels)。 -
未设置:使用输入图像的通道维度格式。
-
-
input_data_format(ChannelDimension或str, optional) — 输入图像的通道维度格式。如果未设置,将从输入图像中推断通道维度格式。可以是以下之一:-
"channels_first"或ChannelDimension.FIRST: 图像格式为(num_channels, height, width)。 -
"channels_last"或ChannelDimension.LAST: 图像格式为(height, width, num_channels)。 -
"none"或ChannelDimension.NONE: 图像格式为(height, width)。
-
预处理一个图像或图像批次。
post_process_object_detection
( outputs threshold: float = 0.1 target_sizes: Union = None ) → export const metadata = 'undefined';List[Dict]
参数
-
outputs(OwlViTObjectDetectionOutput) — 模型的原始输出。 -
threshold(float, optional) — 保留对象检测预测的分数阈值。 -
target_sizes(torch.Tensor或List[Tuple[int, int]], optional) — 形状为(batch_size, 2)的张量或包含每个图像目标尺寸(height, width)的元组列表(Tuple[int, int])。如果未设置,预测将不会被调整大小。
返回
List[Dict]
一个字典列表,每个字典包含模型预测的批次中每个图像的分数、标签和框。
将 OwlViTForObjectDetection 的原始输出转换为最终边界框,格式为(top_left_x, top_left_y, bottom_right_x, bottom_right_y)。
post_process_image_guided_detection
( outputs threshold = 0.0 nms_threshold = 0.3 target_sizes = None ) → export const metadata = 'undefined';List[Dict]
参数
-
outputs(OwlViTImageGuidedObjectDetectionOutput) — 模型的原始输出。 -
threshold(float, 可选, 默认为 0.0) — 用于过滤预测框的最小置信度阈值。 -
nms_threshold(float, 可选, 默认为 0.3) — 用于非最大抑制重叠框的 IoU 阈值。 -
target_sizes(torch.Tensor, 可选) — 形状为(batch_size, 2)的张量,其中每个条目是批次中相应图像的(高度、宽度)。如果设置,预测的归一化边界框将重新缩放为目标大小。如果保持为 None,则预测不会被反归一化。
返回
List[Dict]
一个字典列表,每个字典包含批次中模型预测的图像的分数、标签和框。所有标签都设置为 None,因为OwlViTForObjectDetection.image_guided_detection执行一次性目标检测。
将 OwlViTForObjectDetection.image_guided_detection()的输出转换为 COCO api 期望的格式。
Owlv2Processor
class transformers.Owlv2Processor
( image_processor tokenizer **kwargs )
参数
-
image_processor(Owlv2ImageProcessor) — 图像处理器是必需的输入。 -
tokenizer([CLIPTokenizer,CLIPTokenizerFast]) — 标记器是必需的输入。
构建一个 Owlv2 处理器,将 Owlv2ImageProcessor 和 CLIPTokenizer/CLIPTokenizerFast 包装成一个单一处理器,继承了图像处理器和标记器功能。有关更多信息,请参阅__call__()和 decode()。
batch_decode
( *args **kwargs )
此方法将其所有参数转发到 CLIPTokenizerFast 的 batch_decode()。有关更多信息,请参阅此方法的文档字符串。
decode
( *args **kwargs )
此方法将其所有参数转发到 CLIPTokenizerFast 的 decode()。有关更多信息,请参阅此方法的文档字符串。
post_process_image_guided_detection
( *args **kwargs )
此方法将其所有参数转发到OwlViTImageProcessor.post_process_one_shot_object_detection。有关更多信息,请参阅此方法的文档字符串。
post_process_object_detection
( *args **kwargs )
此方法将其所有参数转发到 OwlViTImageProcessor.post_process_object_detection()。有关更多信息,请参阅此方法的文档字符串。
Owlv2Model
class transformers.Owlv2Model
( config: Owlv2Config )
参数
config(Owvl2Config) — 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
此模型继承自 PreTrainedModel。查看超类文档以获取库实现的所有模型的通用方法(例如下载或保存,调整输入嵌入大小,修剪头等)。
此模型还是 PyTorch 的torch.nn.Module子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以获取与一般用法和行为相关的所有事项。
forward
( input_ids: Optional = None pixel_values: Optional = None attention_mask: Optional = None return_loss: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_base_image_embeds: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.models.owlv2.modeling_owlv2.Owlv2Output or tuple(torch.FloatTensor)
参数
-
input_ids(torch.LongTensor,形状为(batch_size, sequence_length)) — 词汇表中输入序列标记的索引。可以使用 AutoTokenizer 获取索引。有关详细信息,请参见 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。什么是输入 ID? -
pixel_values(torch.FloatTensor,形状为(batch_size, num_channels, height, width)) — 像素值。 -
attention_mask(torch.Tensor,形状为(batch_size, sequence_length),可选) — 避免在填充标记索引上执行注意力的掩码。选择的掩码值在[0, 1]中:-
对于
未被掩盖的标记为 1, -
对于
被掩盖的标记为 0。什么是注意力掩码?
-
-
return_loss(bool, 可选) — 是否返回对比损失。 -
output_attentions(bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回的张量下的attentions。 -
output_hidden_states(bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回的张量下的hidden_states。 -
return_base_image_embeds(bool, 可选) — 是否返回基本图像嵌入。 -
return_dict(bool, 可选) — 是否返回 ModelOutput 而不是普通元组。
返回
transformers.models.owlv2.modeling_owlv2.Owlv2Output或tuple(torch.FloatTensor)
一个transformers.models.owlv2.modeling_owlv2.Owlv2Output或一个torch.FloatTensor元组(如果传递了return_dict=False或config.return_dict=False)包含根据配置(<class 'transformers.models.owlv2.configuration_owlv2.Owlv2Config'>)和输入的各种元素。
-
loss(torch.FloatTensor,形状为(1,),可选,当return_loss为True时返回) — 图像-文本相似性的对比损失。 -
logits_per_image(torch.FloatTensor,形状为(image_batch_size, text_batch_size)) —image_embeds和text_embeds之间的缩放点积分数。这代表图像-文本相似性分数。 -
logits_per_text(torch.FloatTensor,形状为(text_batch_size, image_batch_size)) —text_embeds和image_embeds之间的缩放点积分数。这代表文本-图像相似性分数。 -
text_embeds(torch.FloatTensorof shape(batch_size * num_max_text_queries, output_dim) — 通过将池化输出应用于 Owlv2TextModel 的投影层获得的文本嵌入。 -
image_embeds(torch.FloatTensorof shape(batch_size, output_dim) — 通过将池化输出应用于 Owlv2VisionModel 的投影层获得的图像嵌入。 -
text_model_output(TupleBaseModelOutputWithPooling) — Owlv2TextModel 的输出。 -
vision_model_output(BaseModelOutputWithPooling) — Owlv2VisionModel 的输出。
Owlv2Model 的前向方法,覆盖了__call__特殊方法。
尽管前向传递的配方需要在此函数内定义,但应该在此之后调用Module实例,而不是这个,因为前者负责运行预处理和后处理步骤,而后者则默默地忽略它们。
示例:
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, Owlv2Model
>>> model = Owlv2Model.from_pretrained("google/owlv2-base-patch16-ensemble")
>>> processor = AutoProcessor.from_pretrained("google/owlv2-base-patch16-ensemble")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = processor(text=[["a photo of a cat", "a photo of a dog"]], images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> logits_per_image = outputs.logits_per_image # this is the image-text similarity score
>>> probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
get_text_features
( input_ids: Optional = None attention_mask: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';text_features (torch.FloatTensor of shape (batch_size, output_dim)
参数
-
input_ids(torch.LongTensorof shape(batch_size * num_max_text_queries, sequence_length)) — 词汇表中输入序列标记的索引。可以使用 AutoTokenizer 获取索引。有关详细信息,请参见 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。什么是输入 ID? -
attention_mask(torch.Tensorof shape(batch_size, num_max_text_queries, sequence_length), optional) — 避免在填充标记索引上执行注意力的掩码。选择在[0, 1]中的掩码值:-
1 表示未被掩盖的标记,
-
0 表示被掩盖的标记。什么是注意力掩码?
-
-
output_attentions(bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 -
output_hidden_states(bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 -
return_dict(bool, optional) — 是否返回一个 ModelOutput 而不是一个普通的元组。
返回
text_features (torch.FloatTensor of shape (batch_size, output_dim)
通过将池化输出应用于 Owlv2TextModel 的投影层获得的文本嵌入。
Owlv2Model 的前向方法,覆盖了__call__特殊方法。
尽管前向传递的配方需要在此函数内定义,但应该在此之后调用Module实例,而不是这个,因为前者负责运行预处理和后处理步骤,而后者则默默地忽略它们。
示例:
>>> from transformers import AutoProcessor, Owlv2Model
>>> model = Owlv2Model.from_pretrained("google/owlv2-base-patch16-ensemble")
>>> processor = AutoProcessor.from_pretrained("google/owlv2-base-patch16-ensemble")
>>> inputs = processor(
... text=[["a photo of a cat", "a photo of a dog"], ["photo of a astranaut"]], return_tensors="pt"
... )
>>> text_features = model.get_text_features(**inputs)
get_image_features
( pixel_values: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';image_features (torch.FloatTensor of shape (batch_size, output_dim)
参数
-
pixel_values(torch.FloatTensorof shape(batch_size, num_channels, height, width)) — 像素值。 -
output_attentions(bool,可选)— 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 -
output_hidden_states(bool,可选)— 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 -
return_dict(bool,可选)— 是否返回 ModelOutput 而不是普通元组。
返回
image_features(形状为(batch_size, output_dim)的torch.FloatTensor
通过将投影层应用于 Owlv2VisionModel 的汇聚输出获得的图像嵌入。
Owlv2Model 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的方法需要在此函数内定义,但应该在此之后调用Module实例,而不是在此处调用,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, Owlv2Model
>>> model = Owlv2Model.from_pretrained("google/owlv2-base-patch16-ensemble")
>>> processor = AutoProcessor.from_pretrained("google/owlv2-base-patch16-ensemble")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = processor(images=image, return_tensors="pt")
>>> image_features = model.get_image_features(**inputs)
Owlv2TextModel
class transformers.Owlv2TextModel
( config: Owlv2TextConfig )
forward
( input_ids: Tensor attention_mask: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.BaseModelOutputWithPooling or tuple(torch.FloatTensor)
参数
-
input_ids(形状为(batch_size * num_max_text_queries, sequence_length)的torch.LongTensor)— 词汇表中输入序列标记的索引。可以使用 AutoTokenizer 获取索引。有关详细信息,请参见 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。什么是输入 ID? -
attention_mask(形状为(batch_size, num_max_text_queries, sequence_length)的torch.Tensor,可选)— 避免在填充标记索引上执行注意力的蒙版。在[0, 1]中选择的蒙版值:-
对于“未屏蔽”的标记返回 1,
-
对于“屏蔽”的标记返回 0。什么是注意力蒙版?
-
-
output_attentions(bool,可选)— 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 -
output_hidden_states(bool,可选)— 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 -
return_dict(bool,可选)— 是否返回 ModelOutput 而不是普通元组。
返回
transformers.modeling_outputs.BaseModelOutputWithPooling 或tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.BaseModelOutputWithPooling 或一个torch.FloatTensor元组(如果传递了return_dict=False或config.return_dict=False时)包含各种元素,这取决于配置(<class 'transformers.models.owlv2.configuration_owlv2.Owlv2TextConfig'>)和输入。
-
last_hidden_state(形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor)— 模型最后一层的隐藏状态序列。 -
pooler_output(torch.FloatTensorof shape(batch_size, hidden_size)) — 经过用于辅助预训练任务的层进一步处理后,序列中第一个标记(分类标记)的最后一层隐藏状态。例如,对于 BERT 系列模型,这将返回经过线性层和 tanh 激活函数处理后的分类标记。线性层的权重是在预训练期间从下一个句子预测(分类)目标中训练的。 -
hidden_states(tuple(torch.FloatTensor), optional, 当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(如果模型有嵌入层,则为嵌入的输出+每层的输出)。模型在每一层输出的隐藏状态以及可选的初始嵌入输出。
-
attentions(tuple(torch.FloatTensor), optional, 当传递output_attentions=True或当config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
Owlv2TextModel 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用Module实例,而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoProcessor, Owlv2TextModel
>>> model = Owlv2TextModel.from_pretrained("google/owlv2-base-patch16")
>>> processor = AutoProcessor.from_pretrained("google/owlv2-base-patch16")
>>> inputs = processor(
... text=[["a photo of a cat", "a photo of a dog"], ["photo of a astranaut"]], return_tensors="pt"
... )
>>> outputs = model(**inputs)
>>> last_hidden_state = outputs.last_hidden_state
>>> pooled_output = outputs.pooler_output # pooled (EOS token) states
Owlv2VisionModel
class transformers.Owlv2VisionModel
( config: Owlv2VisionConfig )
forward
( pixel_values: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.BaseModelOutputWithPooling or tuple(torch.FloatTensor)
参数
-
pixel_values(torch.FloatTensorof shape(batch_size, num_channels, height, width)) — 像素值。 -
output_attentions(bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 -
output_hidden_states(bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool, optional) — 是否返回一个 ModelOutput 而不是一个普通的元组。
返回
transformers.modeling_outputs.BaseModelOutputWithPooling 或tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.BaseModelOutputWithPooling 或一个torch.FloatTensor元组(如果传递return_dict=False或当config.return_dict=False时)包含根据配置(<class 'transformers.models.owlv2.configuration_owlv2.Owlv2VisionConfig'>)和输入的不同元素。
-
last_hidden_state(torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — 模型最后一层的隐藏状态序列。 -
pooler_output(torch.FloatTensorof shape(batch_size, hidden_size)) — 序列的第一个标记(分类标记)的最后一层隐藏状态,在通过用于辅助预训练任务的层进一步处理后。例如,对于 BERT 系列模型,这返回经过线性层和双曲正切激活函数处理后的分类标记。线性层的权重是在预训练期间从下一个句子预测(分类)目标中训练的。 -
hidden_states(tuple(torch.FloatTensor), optional, 当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(如果模型有嵌入层,则为嵌入输出的输出 + 每层的输出)。模型在每一层输出的隐藏状态加上可选的初始嵌入输出。
-
attentions(tuple(torch.FloatTensor), optional, 当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。在注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。
Owlv2VisionModel 的前向方法,覆盖了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但应该在此之后调用 Module 实例,而不是在此处调用,因为前者负责运行预处理和后处理步骤,而后者则默默地忽略它们。
示例:
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, Owlv2VisionModel
>>> model = Owlv2VisionModel.from_pretrained("google/owlv2-base-patch16")
>>> processor = AutoProcessor.from_pretrained("google/owlv2-base-patch16")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_state = outputs.last_hidden_state
>>> pooled_output = outputs.pooler_output # pooled CLS states
Owlv2ForObjectDetection
class transformers.Owlv2ForObjectDetection
( config: Owlv2Config )
forward
( input_ids: Tensor pixel_values: FloatTensor attention_mask: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.models.owlv2.modeling_owlv2.Owlv2ObjectDetectionOutput or tuple(torch.FloatTensor)
参数
-
pixel_values(torch.FloatTensorof shape(batch_size, num_channels, height, width)) — 像素值。 -
input_ids(torch.LongTensorof shape(batch_size * num_max_text_queries, sequence_length), optional) — 词汇表中输入序列标记的索引。可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode() 和 PreTrainedTokenizer.call()。什么是输入 ID?。 -
attention_mask(torch.Tensorof shape(batch_size, num_max_text_queries, sequence_length), optional) — 用于避免在填充标记索引上执行注意力的掩码。掩码值选在[0, 1]之间:-
1 用于
not masked的标记, -
0 用于
masked的标记。什么是注意力掩码?
-
-
output_hidden_states(bool, optional) — 是否返回最后一个隐藏状态。有关更多详细信息,请参阅返回张量中的text_model_last_hidden_state和vision_model_last_hidden_state。 -
return_dict(bool, optional) — 是否返回 ModelOutput 而不是普通元组。
返回
transformers.models.owlv2.modeling_owlv2.Owlv2ObjectDetectionOutput 或 tuple(torch.FloatTensor)
一个 transformers.models.owlv2.modeling_owlv2.Owlv2ObjectDetectionOutput 或一个 torch.FloatTensor 元组(如果传递了 return_dict=False 或 config.return_dict=False 或 config.return_dict=False)包含根据配置(<class 'transformers.models.owlv2.configuration_owlv2.Owlv2Config'>)和输入而异的各种元素。
-
loss(torch.FloatTensor,形状为(1,),可选,当提供labels时返回)) — 总损失,作为类别预测的负对数似然(交叉熵)和边界框损失的线性组合。后者被定义为 L1 损失和广义尺度不变 IoU 损失的线性组合。 -
loss_dict(Dict,可选) — 包含各个损失的字典。用于记录。 -
logits(torch.FloatTensor,形状为(batch_size, num_patches, num_queries)) — 所有查询的分类 logits(包括无对象)。 -
objectness_logits(torch.FloatTensor,形状为(batch_size, num_patches, 1)) — 所有图像补丁的目标性 logits。OWL-ViT 将图像表示为一组图像补丁,其中补丁的总数为(图像大小/补丁大小)**2。 -
pred_boxes(torch.FloatTensor,形状为(batch_size, num_patches, 4)) — 所有查询的归一化框坐标,表示为(中心 _x,中心 _y,宽度,高度)。这些值在[0, 1]范围内归一化,相对于批处理中每个单独图像的大小(忽略可能的填充)。您可以使用 post_process_object_detection()来检索未归一化的边界框。 -
text_embeds(torch.FloatTensor,形状为(batch_size, num_max_text_queries, output_dim) — 通过将投影层应用于 Owlv2TextModel 的汇集输出获得的文本嵌入。 -
image_embeds(torch.FloatTensor,形状为(batch_size, patch_size, patch_size, output_dim) — Owlv2VisionModel 的汇集输出。OWLv2 将图像表示为一组图像补丁,并为每个补丁计算图像嵌入。 -
class_embeds(torch.FloatTensor,形状为(batch_size, num_patches, hidden_size)) — 所有图像补丁的类别嵌入。OWLv2 将图像表示为一组图像补丁,其中补丁的总数为(图像大小/补丁大小)**2。 -
text_model_output(TupleBaseModelOutputWithPooling) — Owlv2TextModel 的输出。 -
vision_model_output(BaseModelOutputWithPooling) — Owlv2VisionModel 的输出。
Owlv2ForObjectDetection 的前向方法,覆盖__call__特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用Module实例,而不是在此处调用,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> import requests
>>> from PIL import Image
>>> import numpy as np
>>> import torch
>>> from transformers import AutoProcessor, Owlv2ForObjectDetection
>>> from transformers.utils.constants import OPENAI_CLIP_MEAN, OPENAI_CLIP_STD
>>> processor = AutoProcessor.from_pretrained("google/owlv2-base-patch16-ensemble")
>>> model = Owlv2ForObjectDetection.from_pretrained("google/owlv2-base-patch16-ensemble")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = [["a photo of a cat", "a photo of a dog"]]
>>> inputs = processor(text=texts, images=image, return_tensors="pt")
>>> # forward pass
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> # Note: boxes need to be visualized on the padded, unnormalized image
>>> # hence we'll set the target image sizes (height, width) based on that
>>> def get_preprocessed_image(pixel_values):
... pixel_values = pixel_values.squeeze().numpy()
... unnormalized_image = (pixel_values * np.array(OPENAI_CLIP_STD)[:, None, None]) + np.array(OPENAI_CLIP_MEAN)[:, None, None]
... unnormalized_image = (unnormalized_image * 255).astype(np.uint8)
... unnormalized_image = np.moveaxis(unnormalized_image, 0, -1)
... unnormalized_image = Image.fromarray(unnormalized_image)
... return unnormalized_image
>>> unnormalized_image = get_preprocessed_image(inputs.pixel_values)
>>> target_sizes = torch.Tensor([unnormalized_image.size[::-1]])
>>> # Convert outputs (bounding boxes and class logits) to final bounding boxes and scores
>>> results = processor.post_process_object_detection(
... outputs=outputs, threshold=0.2, target_sizes=target_sizes
... )
>>> i = 0 # Retrieve predictions for the first image for the corresponding text queries
>>> text = texts[i]
>>> boxes, scores, labels = results[i]["boxes"], results[i]["scores"], results[i]["labels"]
>>> for box, score, label in zip(boxes, scores, labels):
... box = [round(i, 2) for i in box.tolist()]
... print(f"Detected {text[label]} with confidence {round(score.item(), 3)} at location {box}")
Detected a photo of a cat with confidence 0.614 at location [512.5, 35.08, 963.48, 557.02]
Detected a photo of a cat with confidence 0.665 at location [10.13, 77.94, 489.93, 709.69]
image_guided_detection
( pixel_values: FloatTensor query_pixel_values: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.models.owlv2.modeling_owlv2.Owlv2ImageGuidedObjectDetectionOutput or tuple(torch.FloatTensor)
参数
-
pixel_values(torch.FloatTensor,形状为(batch_size, num_channels, height, width)) — 像素值。 -
query_pixel_values(torch.FloatTensor,形状为(batch_size, num_channels, height, width)) — 要检测的查询图像的像素值。每个目标图像传入一个查询图像。 -
output_attentions(bool,可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 -
output_hidden_states(bool,可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool,可选) — 是否返回 ModelOutput 而不是普通元组。
返回
transformers.models.owlv2.modeling_owlv2.Owlv2ImageGuidedObjectDetectionOutput 或 tuple(torch.FloatTensor)
一个transformers.models.owlv2.modeling_owlv2.Owlv2ImageGuidedObjectDetectionOutput 或一个torch.FloatTensor元组(如果传递了return_dict=False或config.return_dict=False)包含各种元素,具体取决于配置(<class 'transformers.models.owlv2.configuration_owlv2.Owlv2Config'>)和输入。
-
logits(torch.FloatTensor,形状为(batch_size, num_patches, num_queries)) — 所有查询的分类 logits(包括无对象)。 -
target_pred_boxes(torch.FloatTensor,形状为(batch_size, num_patches, 4)) — 所有查询的标准化框坐标,表示为(中心 _x,中心 _y,宽度,高度)。这些值在[0, 1]范围内标准化,相对于批处理中每个单独目标图像的大小(忽略可能的填充)。您可以使用 post_process_object_detection()来检索未标准化的边界框。 -
query_pred_boxes(torch.FloatTensor,形状为(batch_size, num_patches, 4)) — 所有查询的标准化框坐标,表示为(中心 _x,中心 _y,宽度,高度)。这些值在[0, 1]范围内标准化,相对于批处理中每个单独查询图像的大小(忽略可能的填充)。您可以使用 post_process_object_detection()来检索未标准化的边界框。 -
image_embeds(torch.FloatTensor,形状为(batch_size, patch_size, patch_size, output_dim) — Owlv2VisionModel 的汇总输出。OWLv2 将图像表示为一组图像补丁,并为每个补丁计算图像嵌入。 -
query_image_embeds(torch.FloatTensor,形状为(batch_size, patch_size, patch_size, output_dim) — Owlv2VisionModel 的汇总输出。OWLv2 将图像表示为一组图像补丁,并为每个补丁计算图像嵌入。 -
class_embeds(torch.FloatTensor,形状为(batch_size, num_patches, hidden_size)) — 所有图像补丁的类别嵌入。OWLv2 将图像表示为一组图像补丁,其中补丁的总数为(图像大小/补丁大小)**2。 -
text_model_output(TupleBaseModelOutputWithPooling) — Owlv2TextModel 的输出。 -
vision_model_output(BaseModelOutputWithPooling) — Owlv2VisionModel 的输出。
Owlv2ForObjectDetection 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的配方需要在此函数内定义,但应该在之后调用Module实例,而不是在此处调用,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> import requests
>>> from PIL import Image
>>> import torch
>>> import numpy as np
>>> from transformers import AutoProcessor, Owlv2ForObjectDetection
>>> from transformers.utils.constants import OPENAI_CLIP_MEAN, OPENAI_CLIP_STD
>>> processor = AutoProcessor.from_pretrained("google/owlv2-base-patch16-ensemble")
>>> model = Owlv2ForObjectDetection.from_pretrained("google/owlv2-base-patch16-ensemble")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> query_url = "http://images.cocodataset.org/val2017/000000001675.jpg"
>>> query_image = Image.open(requests.get(query_url, stream=True).raw)
>>> inputs = processor(images=image, query_images=query_image, return_tensors="pt")
>>> # forward pass
>>> with torch.no_grad():
... outputs = model.image_guided_detection(**inputs)
>>> # Note: boxes need to be visualized on the padded, unnormalized image
>>> # hence we'll set the target image sizes (height, width) based on that
>>> def get_preprocessed_image(pixel_values):
... pixel_values = pixel_values.squeeze().numpy()
... unnormalized_image = (pixel_values * np.array(OPENAI_CLIP_STD)[:, None, None]) + np.array(OPENAI_CLIP_MEAN)[:, None, None]
... unnormalized_image = (unnormalized_image * 255).astype(np.uint8)
... unnormalized_image = np.moveaxis(unnormalized_image, 0, -1)
... unnormalized_image = Image.fromarray(unnormalized_image)
... return unnormalized_image
>>> unnormalized_image = get_preprocessed_image(inputs.pixel_values)
>>> target_sizes = torch.Tensor([unnormalized_image.size[::-1]])
>>> # Convert outputs (bounding boxes and class logits) to Pascal VOC format (xmin, ymin, xmax, ymax)
>>> results = processor.post_process_image_guided_detection(
... outputs=outputs, threshold=0.9, nms_threshold=0.3, target_sizes=target_sizes
... )
>>> i = 0 # Retrieve predictions for the first image
>>> boxes, scores = results[i]["boxes"], results[i]["scores"]
>>> for box, score in zip(boxes, scores):
... box = [round(i, 2) for i in box.tolist()]
... print(f"Detected similar object with confidence {round(score.item(), 3)} at location {box}")
Detected similar object with confidence 0.938 at location [490.96, 109.89, 821.09, 536.11]
Detected similar object with confidence 0.959 at location [8.67, 721.29, 928.68, 732.78]
Detected similar object with confidence 0.902 at location [4.27, 720.02, 941.45, 761.59]
Detected similar object with confidence 0.985 at location [265.46, -58.9, 1009.04, 365.66]
Detected similar object with confidence 1.0 at location [9.79, 28.69, 937.31, 941.64]
Detected similar object with confidence 0.998 at location [869.97, 58.28, 923.23, 978.1]
Detected similar object with confidence 0.985 at location [309.23, 21.07, 371.61, 932.02]
Detected similar object with confidence 0.947 at location [27.93, 859.45, 969.75, 915.44]
Detected similar object with confidence 0.996 at location [785.82, 41.38, 880.26, 966.37]
Detected similar object with confidence 0.998 at location [5.08, 721.17, 925.93, 998.41]
Detected similar object with confidence 0.969 at location [6.7, 898.1, 921.75, 949.51]
Detected similar object with confidence 0.966 at location [47.16, 927.29, 981.99, 942.14]
Detected similar object with confidence 0.924 at location [46.4, 936.13, 953.02, 950.78]
Perceiver
原文链接:
huggingface.co/docs/transformers/v4.37.2/en/model_doc/perceiver
概述
Perceiver IO 模型由 Andrew Jaegle、Sebastian Borgeaud、Jean-Baptiste Alayrac、Carl Doersch、Catalin Ionescu、David Ding、Skanda Koppula、Daniel Zoran、Andrew Brock、Evan Shelhamer、Olivier Hénaff、Matthew M. Botvinick、Andrew Zisserman、Oriol Vinyals、João Carreira 在《Perceiver IO: A General Architecture for Structured Inputs & Outputs》中提出。
Perceiver IO 是对 Perceiver 的泛化,可以处理任意输出以及任意输入。原始的 Perceiver 只产生单个分类标签。除了分类标签,Perceiver IO 还可以生成(例如)语言、光流和带有音频的多模态视频。这是使用与原始 Perceiver 相同的构建模块完成的。Perceiver IO 的计算复杂度与输入和输出大小呈线性关系,大部分处理发生在潜在空间中,使我们能够处理比标准 Transformer 处理能力更大的输入和输出。这意味着,例如,Perceiver IO 可以直接使用字节执行类似 BERT 的掩码语言建模,而不是使用标记化的输入。
论文的摘要如下:
最近提出的 Perceiver 模型在多个领域(图像、音频、多模态、点云)上取得了良好的结果,同时在计算和内存方面与输入大小呈线性关系。虽然 Perceiver 支持多种类型的输入,但它只能产生非常简单的输出,如类别分数。Perceiver IO 通过学习灵活地查询模型的潜在空间来产生任意大小和语义的输出,克服了这一限制,同时保留了原始模型的吸引人特性。Perceiver IO 仍然将模型深度与数据大小分离,并且仍然与数据大小呈线性关系,但现在是相对于输入和输出大小。完整的 Perceiver IO 模型在具有高度结构化输出空间的任务上取得了强大的结果,例如自然语言和视觉理解、星际争霸 II 以及多任务和多模态领域。作为亮点,Perceiver IO 在 GLUE 语言基准测试中与基于 Transformer 的 BERT 基线相匹配,无需输入标记化,并在 Sintel 光流估计中实现了最先进的性能。
以下是 Perceiver 工作原理的 TLDR:
Transformer 的自注意机制的主要问题是随着序列长度的增加,时间和内存需求呈二次方增长。因此,像 BERT 和 RoBERTa 这样的模型受限于最大 512 个标记的序列长度。Perceiver 旨在通过在一组潜在变量上执行自注意,而不是在输入上执行自注意,从而解决这个问题,并且仅使用输入进行交叉注意力。这样,时间和内存需求不再取决于输入的长度,因为使用固定数量的潜在变量,如 256 或 512。这些变量是随机初始化的,之后通过反向传播进行端到端训练。
在内部,PerceiverModel 将创建潜在变量,其形状为(batch_size, num_latents, d_latents)的张量。必须向模型提供输入(可以是文本、图像、音频等),模型将使用这些输入与潜在变量进行交叉注意力。Perceiver 编码器的输出是相同形状的张量。然后可以类似于 BERT,通过沿序列维度取平均值将潜在变量的最后隐藏状态转换为分类 logits,并在其上放置一个线性层,将d_latents投影到num_labels。
这是原始 Perceiver 论文的想法。但是,它只能输出分类 logits。在后续工作 PerceiverIO 中,他们将其泛化,使模型还可以产生任意大小的输出。你可能会问,如何实现?其实想法相对简单:定义任意大小的输出,然后使用潜在变量的最后隐藏状态执行交叉注意力,使用输出作为查询,潜在变量作为键和值。
那么假设有人想要使用 Perceiver 执行掩码语言建模(类似 BERT)。由于 Perceiver 的输入长度不会影响自注意力层的计算时间,可以提供原始字节,将inputs的长度提供给模型为 2048。如果现在屏蔽掉这 2048 个标记中的某些标记,可以将outputs定义为形状为:(batch_size, 2048, 768)。接下来,使用潜在变量的最终隐藏状态执行交叉注意力以更新outputs张量。经过交叉注意力后,仍然有形状为(batch_size, 2048, 768)的张量。然后可以在顶部放置一个常规的语言建模头部,将最后一个维度投影到模型的词汇量大小,即创建形状为(batch_size, 2048, 262)的 logits(因为 Perceiver 使用 262 个字节 ID 的词汇量大小)。
 Perceiver IO 架构。取自原始论文
Perceiver IO 架构。取自原始论文
Perceiver 不 与torch.nn.DataParallel一起使用,因为 PyTorch 中存在错误,请参阅问题#36035
资源
-
开始使用 Perceiver 的最快方法是查看教程笔记本。
-
如果您想要完全了解模型如何工作并在库中实现,请参考博客文章。请注意,库中提供的模型仅展示了您可以使用 Perceiver 做什么的一些示例。还有许多其他用例,包括问答,命名实体识别,目标检测,音频分类,视频分类等。
-
文本分类任务指南
-
掩码语言建模任务指南
-
图像分类任务指南
Perceiver 特定的输出
class transformers.models.perceiver.modeling_perceiver.PerceiverModelOutput
( logits: FloatTensor = None last_hidden_state: FloatTensor = None hidden_states: Optional = None attentions: Optional = None cross_attentions: Optional = None )
参数
-
logits(形状为(batch_size, num_labels)的torch.FloatTensor)—分类(如果config.num_labels==1则为回归)得分(SoftMax 之前)。 -
last_hidden_state(形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor)—模型最后一层的隐藏状态序列。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回)—形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(一个用于嵌入的输出+一个用于每个层的输出)。模型在每一层的输出的隐藏状态加上初始嵌入输出。 -
attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或当config.output_attentions=True时返回)—形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每个层一个)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。 -
cross_attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每个层一个)。解码器的交叉注意力层的注意力权重,注意力 softmax 后用于计算交叉注意力头中的加权平均值。
Perceiver 基础模型输出的基类,包括潜在的隐藏状态、注意力和交叉注意力。
class transformers.models.perceiver.modeling_perceiver.PerceiverDecoderOutput
( logits: FloatTensor = None cross_attentions: Optional = None )
参数
-
logits(torch.FloatTensor,形状为(batch_size, num_labels)) — 基本解码器的输出。 -
cross_attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每个层一个)。解码器的交叉注意力层的注意力权重,注意力 softmax 后用于计算交叉注意力头中的加权平均值。
Perceiver 解码器输出的基类,包括潜在的交叉注意力。
class transformers.models.perceiver.modeling_perceiver.PerceiverMaskedLMOutput
( loss: Optional = None logits: FloatTensor = None hidden_states: Optional = None attentions: Optional = None cross_attentions: Optional = None )
参数
-
loss(torch.FloatTensor,形状为(1,),可选,当提供labels时返回) — 掩码语言建模(MLM)损失。 -
logits(torch.FloatTensor,形状为(batch_size, sequence_length, config.vocab_size)) — 语言建模头的预测分数(SoftMax 之前每个词汇标记的分数)。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(一个用于嵌入的输出 + 一个用于每个层的输出)。模型在每个层的输出的隐藏状态加上初始嵌入输出。 -
attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, num_latents, num_latents)的torch.FloatTensor元组(每个层一个)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。 -
cross_attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每个层一个)。解码器的交叉注意力层的注意力权重,注意力 softmax 后用于计算交叉注意力头中的加权平均值。
Perceiver 掩码语言模型输出的基类。
class transformers.models.perceiver.modeling_perceiver.PerceiverClassifierOutput
( loss: Optional = None logits: FloatTensor = None hidden_states: Optional = None attentions: Optional = None cross_attentions: Optional = None )
参数
-
loss(torch.FloatTensor,形状为(1,),可选,当提供labels时返回) — 分类(如果config.num_labels==1则为回归)损失。 -
logits(torch.FloatTensor,形状为(batch_size, config.num_labels)) — 分类(如果config.num_labels==1则为回归)分数(SoftMax 之前)。 -
hidden_states(tuple(torch.FloatTensor), 可选, 当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组。模型在每一层输出的隐藏状态加上初始嵌入输出。 -
attentions(tuple(torch.FloatTensor), 可选, 当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。在注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。 -
cross_attentions(tuple(torch.FloatTensor), 可选, 当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。解码器的交叉注意力层的注意力权重,在注意力 softmax 之后,用于计算交叉注意力头中的加权平均值。
Perceiver 的序列/图像分类模型、光流和多模态自编码的输出的基类。
PerceiverConfig
class transformers.PerceiverConfig
( num_latents = 256 d_latents = 1280 d_model = 768 num_blocks = 1 num_self_attends_per_block = 26 num_self_attention_heads = 8 num_cross_attention_heads = 8 qk_channels = None v_channels = None cross_attention_shape_for_attention = 'kv' self_attention_widening_factor = 1 cross_attention_widening_factor = 1 hidden_act = 'gelu' attention_probs_dropout_prob = 0.1 initializer_range = 0.02 layer_norm_eps = 1e-12 use_query_residual = True vocab_size = 262 max_position_embeddings = 2048 image_size = 56 train_size = [368, 496] num_frames = 16 audio_samples_per_frame = 1920 samples_per_patch = 16 output_shape = [1, 16, 224, 224] output_num_channels = 512 _label_trainable_num_channels = 1024 **kwargs )
参数
-
num_latents(int, 可选, 默认为 256) — 潜在嵌入的数量。 -
d_latents(int, 可选, 默认为 1280) — 潜在嵌入的维度。 -
d_model(int, 可选, 默认为 768) — 输入的维度。仅在使用[PerceiverTextPreprocessor]或未提供预处理器时提供。 -
num_blocks(int, 可选, 默认为 1) — Transformer 编码器中的块数。 -
num_self_attends_per_block(int, 可选, 默认为 26) — 每个块中的自注意力层的数量。 -
num_self_attention_heads(int, 可选, 默认为 8) — Transformer 编码器中每个自注意力层的注意力头数。 -
num_cross_attention_heads(int, 可选, 默认为 8) — Transformer 编码器中每个交叉注意力层的注意力头数。 -
qk_channels(int, 可选) — 在编码器的交叉注意力和自注意力层中应用注意力之前投影查询+键的维度。如果未指定,将默认保留查询的维度。 -
v_channels(int, 可选) — 在编码器的交叉注意力和自注意力层中应用注意力之前投影值的维度。如果未指定,将默认保留查询的维度。 -
cross_attention_shape_for_attention(str, 可选, 默认为"kv") — 在编码器的交叉注意力层中降采样查询和键时使用的维度。 -
self_attention_widening_factor(int, 可选, 默认为 1) — Transformer 编码器中交叉注意力层中前馈层的维度。 -
cross_attention_widening_factor(int, 可选, 默认为 1) — Transformer 编码器中自注意力层中前馈层的维度。 -
hidden_act(str或function, 可选, 默认为"gelu") — 编码器和池化器中的非线性激活函数(函数或字符串)。如果是字符串,支持"gelu"、"relu"、"selu"和"gelu_new"。 -
attention_probs_dropout_prob(float, 可选, 默认为 0.1) — 注意力概率的丢弃比率。 -
initializer_range(float, 可选, 默认为 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 -
layer_norm_eps(float, 可选, 默认为 1e-12) — 层归一化层使用的 epsilon。 -
use_query_residual(float, optional, defaults toTrue) — 是否在编码器的交叉注意力层中添加查询残差。 -
vocab_size(int, optional, defaults to 262) — 用于掩码语言建模模型的词汇量。 -
max_position_embeddings(int, optional, defaults to 2048) — 掩码语言建模模型可能使用的最大序列长度。通常将其设置为较大的值以防万一(例如,512、1024 或 2048)。 -
image_size(int, optional, defaults to 56) — 预处理后的图像大小,用于 PerceiverForImageClassificationLearned。 -
train_size(List[int], optional, defaults to[368, 496]) — 光流模型图像的训练大小。 -
num_frames(int, optional, defaults to 16) — 多模态自编码模型中使用的视频帧数。 -
audio_samples_per_frame(int, optional, defaults to 1920) — 多模态自编码模型中每帧的音频样本数。 -
samples_per_patch(int, optional, defaults to 16) — 在预处理音频时,每个补丁的音频样本数,用于多模态自编码模型。 -
output_shape(List[int], optional, defaults to[1, 16, 224, 224]) — 多模态自编码模型视频解码器查询的输出形状(批量大小、帧数、高度、宽度)。这不包括通道维度。 -
output_num_channels(int, optional, defaults to 512) — 每个模态解码器的输出通道数。
这是用于存储 PerceiverModel 配置的配置类。它用于根据指定的参数实例化 Perceiver 模型,定义模型架构。使用默认值实例化配置将产生类似于 Perceiver deepmind/language-perceiver 架构的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读来自 PretrainedConfig 的文档以获取更多信息。
示例:
>>> from transformers import PerceiverModel, PerceiverConfig
>>> # Initializing a Perceiver deepmind/language-perceiver style configuration
>>> configuration = PerceiverConfig()
>>> # Initializing a model from the deepmind/language-perceiver style configuration
>>> model = PerceiverModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
PerceiverTokenizer
class transformers.PerceiverTokenizer
( pad_token = '[PAD]' bos_token = '[BOS]' eos_token = '[EOS]' mask_token = '[MASK]' cls_token = '[CLS]' sep_token = '[SEP]' model_max_length = 2048 **kwargs )
参数
-
pad_token(str, optional, defaults to"[PAD]") — 用于填充的标记,例如在批处理不同长度的序列时使用。 -
bos_token(str, optional, defaults to"[BOS]") — BOS 标记(在词汇表中保留,但实际上未使用)。 -
eos_token(str, optional, defaults to"[EOS]") — 序列结束标记(在词汇表中保留,但实际上未使用)。在使用特殊标记构建序列时,这不是用于序列结尾的标记。实际使用的标记是
sep_token。 -
mask_token(str, optional, defaults to"[MASK]") — MASK 标记,用于掩码语言建模。 -
cls_token(str, optional, defaults to"[CLS]") — CLS 标记(在词汇表中保留,但实际上未使用)。 -
sep_token(str, optional, defaults to"[SEP]") — 用于从两个序列构建序列时使用的分隔符标记。
构建一个 Perceiver 标记器。Perceiver 简单地使用原始字节 utf-8 编码。
此标记器继承自 PreTrainedTokenizer,其中包含大多数主要方法。用户应参考此超类以获取有关这些方法的更多信息。
__call__
( text: Union = None text_pair: Union = None text_target: Union = None text_pair_target: Union = None add_special_tokens: bool = True padding: Union = False truncation: Union = None max_length: Optional = None stride: int = 0 is_split_into_words: bool = False pad_to_multiple_of: Optional = None return_tensors: Union = None return_token_type_ids: Optional = None return_attention_mask: Optional = None return_overflowing_tokens: bool = False return_special_tokens_mask: bool = False return_offsets_mapping: bool = False return_length: bool = False verbose: bool = True **kwargs ) → export const metadata = 'undefined';BatchEncoding
参数
-
text(str,List[str],List[List[str]], 可选) — 要编码的序列或序列批次。每个序列可以是字符串或字符串列表(预分词字符串)。如果序列以字符串列表(预分词)的形式提供,则必须设置is_split_into_words=True(以消除与序列批次的歧义)。 -
text_pair(str,List[str],List[List[str]], 可选) — 要编码的序列或序列批次。每个序列可以是字符串或字符串列表(预分词字符串)。如果序列以字符串列表(预分词)的形式提供,则必须设置is_split_into_words=True(以消除与序列批次的歧义)。 -
text_target(str,List[str],List[List[str]], 可选) — 要编码为目标文本的序列或序列批次。每个序列可以是字符串或字符串列表(预分词字符串)。如果序列以字符串列表(预分词)的形式提供,则必须设置is_split_into_words=True(以消除与序列批次的歧义)。 -
text_pair_target(str,List[str],List[List[str]], 可选) — 要编码为目标文本的序列或序列批次。每个序列可以是字符串或字符串列表(预分词字符串)。如果序列以字符串列表(预分词)的形式提供,则必须设置is_split_into_words=True(以消除与序列批次的歧义)。 -
add_special_tokens(bool, 可选, 默认为True) — 在编码序列时是否添加特殊标记。这将使用底层的PretrainedTokenizerBase.build_inputs_with_special_tokens函数,该函数定义了自动添加到输入 id 的标记。如果要自动添加bos或eos标记,则这很有用。 -
padding(bool,str或 PaddingStrategy, 可选, 默认为False) — 激活和控制填充。接受以下值:-
True或'longest': 填充到批次中最长的序列(如果只提供单个序列,则不进行填充)。 -
'max_length': 填充到指定的最大长度(使用参数max_length)或模型的最大可接受输入长度(如果未提供该参数)。 -
False或'do_not_pad'(默认): 不进行填充(即可以输出长度不同的序列批次)。
-
-
truncation(bool,str或 TruncationStrategy, 可选, 默认为False) — 激活和控制截断。接受以下值:-
True或'longest_first': 截断到指定的最大长度(使用参数max_length)或模型的最大可接受输入长度(如果未提供该参数)。如果提供了一对序列(或一批对序列),则将逐标记截断,从一对序列中最长的序列中删除一个标记。 -
'only_first': 截断到指定的最大长度(使用参数max_length)或模型的最大可接受输入长度(如果未提供该参数)。如果提供了一对序列(或一批对序列),则只会截断第一个序列。 -
'only_second': 截断到指定的最大长度(使用参数max_length)或模型的最大可接受输入长度(如果未提供该参数)。如果提供了一对序列(或一批对序列),则只会截断第二个序列。 -
False或'do_not_truncate'(默认): 不截断(即可以输出长度大于模型最大可接受输入大小的批次)。
-
-
max_length(int, optional) — 控制截断/填充参数之一使用的最大长度。如果未设置或设置为
None,则如果截断/填充参数之一需要最大长度,则将使用预定义的模型最大长度。如果模型没有特定的最大输入长度(如 XLNet),则将禁用截断/填充到最大长度。 -
stride(int, optional, 默认为 0) — 如果与max_length一起设置为一个数字,则当return_overflowing_tokens=True时返回的溢出标记将包含截断序列末尾的一些标记,以提供截断和溢出序列之间的一些重叠。此参数的值定义重叠标记的数量。 -
is_split_into_words(bool, optional, 默认为False) — 输入是否已经预先标记化(例如,已分割为单词)。如果设置为True,分词器会假定输入已经分割为单词(例如,通过在空格上分割),然后对其进行标记化。这对于 NER 或标记分类很有用。 -
pad_to_multiple_of(int, optional) — 如果设置,将填充序列到提供的值的倍数。需要激活padding。这对于在具有计算能力>= 7.5(Volta)的 NVIDIA 硬件上启用 Tensor Cores 特别有用。 -
return_tensors(str或 TensorType, optional) — 如果设置,将返回张量而不是 Python 整数列表。可接受的值为:-
'tf':返回 TensorFlowtf.constant对象。 -
'pt':返回 PyTorchtorch.Tensor对象。 -
'np':返回 Numpynp.ndarray对象。
-
-
return_token_type_ids(bool, optional) — 是否返回标记类型 ID。如果保持默认设置,将根据特定分词器的默认值返回标记类型 ID,由return_outputs属性定义。什么是标记类型 ID?
-
return_attention_mask(bool, optional) — 是否返回注意力掩码。如果保持默认设置,将根据特定分词器的默认值返回注意力掩码,由return_outputs属性定义。什么是注意力掩码?
-
return_overflowing_tokens(bool, optional, 默认为False) — 是否返回溢出的标记序列。如果提供了一对输入 id 序列(或一批对),并且truncation_strategy = longest_first或True,则会引发错误,而不是返回溢出标记。 -
return_special_tokens_mask(bool, optional, 默认为False) — 是否返回特殊标记掩码信息。 -
return_offsets_mapping(bool, optional, 默认为False) — 是否返回每个标记的(char_start, char_end)。这仅适用于继承自 PreTrainedTokenizerFast 的快速分词器,如果使用 Python 的分词器,此方法将引发
NotImplementedError。 -
return_length(bool, optional, 默认为False) — 是否返回编码输入的长度。 -
verbose(bool, optional, 默认为True) — 是否打印更多信息和警告。**kwargs — 传递给self.tokenize()方法
返回
BatchEncoding
具有以下字段的 BatchEncoding:
-
input_ids— 要馈送到模型的标记 id 列表。什么是输入 ID?
-
token_type_ids— 要馈送到模型的标记类型 id 列表(当return_token_type_ids=True或self.model_input_names中包含*token_type_ids*时)。什么是标记类型 ID?
-
attention_mask— 指定哪些令牌应该被模型关注的索引列表(当return_attention_mask=True或self.model_input_names中包含*attention_mask*时)。什么是注意力掩码?
-
overflowing_tokens— 溢出的令牌序列列表(当指定max_length并且return_overflowing_tokens=True时)。 -
num_truncated_tokens— 截断的令牌数(当指定max_length并且return_overflowing_tokens=True时)。 -
special_tokens_mask— 由 0 和 1 组成的列表,其中 1 指定添加的特殊令牌,0 指定常规序列令牌(当add_special_tokens=True和return_special_tokens_mask=True时)。 -
length— 输入的长度(当return_length=True时)
用于对一个或多个序列或一个或多个序列对进行标记和准备模型的主要方法。
感知器特征提取器
class transformers.PerceiverFeatureExtractor
( *args **kwargs )
__call__
( images **kwargs )
预处理图像或一批图像。
感知器图像处理器
class transformers.PerceiverImageProcessor
( do_center_crop: bool = True crop_size: Dict = None do_resize: bool = True size: Dict = None resample: Resampling = <Resampling.BICUBIC: 3> do_rescale: bool = True rescale_factor: Union = 0.00392156862745098 do_normalize: bool = True image_mean: Union = None image_std: Union = None **kwargs )
参数
-
do_center_crop(bool,可选,默认为True) — 是否对图像进行中心裁剪。如果输入尺寸小于任何边的crop_size,则图像将填充零,然后进行中心裁剪。可以被preprocess方法中的do_center_crop参数覆盖。 -
crop_size(Dict[str, int],可选,默认为{"height" -- 256, "width": 256}): 应用中心裁剪时的期望输出大小。可以被preprocess方法中的crop_size参数覆盖。 -
do_resize(bool,可选,默认为True) — 是否将图像调整大小为(size["height"], size["width"])。可以被preprocess方法中的do_resize参数覆盖。 -
size(Dict[str, int]可选,默认为{"height" -- 224, "width": 224}): 调整大小后的图像尺寸。可以被preprocess方法中的size参数覆盖。 -
resample(PILImageResampling,可选,默认为PILImageResampling.BICUBIC) — 定义在调整图像大小时要使用的重采样滤波器。可以被preprocess方法中的resample参数覆盖。 -
do_rescale(bool,可选,默认为True) — 是否按指定比例rescale_factor重新缩放图像。可以被preprocess方法中的do_rescale参数覆盖。 -
rescale_factor(int或float,可选,默认为1/255) — 定义重新缩放图像时要使用的比例因子。可以被preprocess方法中的rescale_factor参数覆盖。do_normalize — 是否对图像进行归一化。可以被preprocess方法中的do_normalize参数覆盖。 -
image_mean(float或List[float],可选,默认为IMAGENET_STANDARD_MEAN) — 如果对图像进行归一化,则使用的均值。这是一个浮点数或与图像通道数相同长度的浮点数列表。可以被preprocess方法中的image_mean参数覆盖。 -
image_std(float或List[float],可选,默认为IMAGENET_STANDARD_STD) — 如果对图像进行归一化,则使用的标准差。这是一个浮点数或与图像通道数相同长度的浮点数列表。可以被preprocess方法中的image_std参数覆盖。
构建感知器图像处理器。
preprocess
( images: Union do_center_crop: Optional = None crop_size: Optional = None do_resize: Optional = None size: Optional = None resample: Resampling = None do_rescale: Optional = None rescale_factor: Optional = None do_normalize: Optional = None image_mean: Union = None image_std: Union = None return_tensors: Union = None data_format: ChannelDimension = <ChannelDimension.FIRST: 'channels_first'> input_data_format: Union = None **kwargs )
参数
-
images(ImageInput) — 要预处理的图像。期望单个图像或图像批次,像素值范围为 0 到 255。如果传入像素值在 0 到 1 之间的图像,请设置do_rescale=False。 -
do_center_crop(bool, optional, defaults toself.do_center_crop) — 是否将图像居中裁剪到crop_size。 -
crop_size(Dict[str, int], optional, defaults toself.crop_size) — 应用中心裁剪后的期望输出大小。 -
do_resize(bool, optional, defaults toself.do_resize) — 是否调整图像大小。 -
size(Dict[str, int], optional, defaults toself.size) — 调整大小后的图像尺寸。 -
resample(int, optional, defaults toself.resample) — 如果调整图像大小,则使用的重采样滤波器。这可以是枚举PILImageResampling中的一个。仅在do_resize设置为True时有效。 -
do_rescale(bool, optional, defaults toself.do_rescale) — 是否重新缩放图像。 -
rescale_factor(float, optional, defaults toself.rescale_factor) — 如果do_rescale设置为True,则重新缩放图像的重新缩放因子。 -
do_normalize(bool, optional, defaults toself.do_normalize) — 是否对图像进行归一化。 -
image_mean(floatorList[float], optional, defaults toself.image_mean) — 图像均值。 -
image_std(floatorList[float], optional, defaults toself.image_std) — 图像标准差。 -
return_tensors(strorTensorType, optional) — 要返回的张量类型。可以是以下之一:-
未设置:返回一个
np.ndarray列表。 -
TensorType.TENSORFLOW或'tf': 返回类型为tf.Tensor的批次。 -
TensorType.PYTORCH或'pt': 返回类型为torch.Tensor的批次。 -
TensorType.NUMPY或'np': 返回类型为np.ndarray的批次。 -
TensorType.JAX或'jax': 返回类型为jax.numpy.ndarray的批次。
-
-
data_format(ChannelDimension或str, optional, defaults toChannelDimension.FIRST) — 输出图像的通道维度格式。可以是以下之一:-
ChannelDimension.FIRST: 图像格式为(num_channels, height, width)。 -
ChannelDimension.LAST: 图像格式为(height, width, num_channels)。
-
-
input_data_format(ChannelDimension或str, optional) — 输入图像的通道维度格式。如果未设置,则从输入图像中推断通道维度格式。可以是以下之一:-
"channels_first"或ChannelDimension.FIRST: 图像格式为(num_channels, height, width)。 -
"channels_last"或ChannelDimension.LAST: 图像格式为(height, width, num_channels)。 -
"none"或ChannelDimension.NONE: 图像格式为(height, width)。
-
对图像或图像批次进行预处理。
PerceiverTextPreprocessor
class transformers.models.perceiver.modeling_perceiver.PerceiverTextPreprocessor
( config: PerceiverConfig )
参数
config(PerceiverConfig) — 模型配置。
Perceiver 编码器的文本预处理。可用于嵌入inputs并添加位置编码。
嵌入的维度由配置的d_model属性确定。
PerceiverImagePreprocessor
class transformers.models.perceiver.modeling_perceiver.PerceiverImagePreprocessor
( config prep_type = 'conv' spatial_downsample: int = 4 temporal_downsample: int = 1 position_encoding_type: str = 'fourier' in_channels: int = 3 out_channels: int = 64 conv_after_patching: bool = False conv_after_patching_in_channels: int = 54 conv2d_use_batchnorm: bool = True concat_or_add_pos: str = 'concat' project_pos_dim: int = -1 **position_encoding_kwargs )
参数
-
config([PerceiverConfig]) — 模型配置。 -
prep_type(str, optional, defaults to"conv") — 预处理类型。可以是“conv1x1”,"conv",“patches”,“pixels”。 -
spatial_downsample(int, optional, defaults to 4) — 空间下采样因子。 -
temporal_downsample(int, optional, defaults to 1) — 时间下采样因子(仅在存在时间维度的情况下相关)。 -
position_encoding_type(str, 可选, 默认为"fourier") — 位置编码类型。可以是"fourier"或“trainable”。 -
in_channels(int, 可选, 默认为 3) — 输入中的通道数。 -
out_channels(int, 可选, 默认为 64) — 输出中的通道数。 -
conv_after_patching(bool, 可选, 默认为False) — 是否在修补后应用卷积层。 -
conv_after_patching_in_channels(int, 可选, 默认为 54) — 修补后卷积层输入中的通道数。 -
conv2d_use_batchnorm(bool, 可选, 默认为True) — 是否在卷积层中使用批量归一化。 -
concat_or_add_pos(str, 可选, 默认为"concat") — 如何将位置编码连接到输入。可以是"concat"或“add”。 -
project_pos_dim(int, 可选, 默认为-1) — 要投影到的位置编码的维度。如果为-1,则不应用投影。 -
*
*position_encoding_kwargs(Dict, 可选) — 位置编码的关键字参数。
感知器编码器的图像预处理。
注意:out_channels参数指的是卷积层的输出通道数,如果prep_type设置为“conv1x1”或“conv”。如果添加绝对位置嵌入,必须确保位置编码 kwargs 的num_channels设置为out_channels。
感知器独热预处理器
class transformers.models.perceiver.modeling_perceiver.PerceiverOneHotPreprocessor
( config: PerceiverConfig )
参数
config(PerceiverConfig) — 模型配置。
感知器编码器的独热预处理器。可用于向输入添加一个虚拟索引维度。
感知器音频预处理器
class transformers.models.perceiver.modeling_perceiver.PerceiverAudioPreprocessor
( config prep_type: str = 'patches' samples_per_patch: int = 96 position_encoding_type: str = 'fourier' concat_or_add_pos: str = 'concat' out_channels = 64 project_pos_dim = -1 **position_encoding_kwargs )
参数
-
config([PerceiverConfig]) — 模型配置。 -
prep_type(str, 可选, 默认为"patches") — 要使用的预处理器类型。仅支持"patches"。 -
samples_per_patch(int, 可选, 默认为 96) — 每个修补的样本数。 -
position_encoding_type(str, 可选, 默认为"fourier") — 要使用的位置编码类型。可以是“trainable”或"fourier"。 -
concat_or_add_pos(str, 可选, 默认为"concat") — 如何将位置编码连接到输入。可以是"concat"或“add”。 -
out_channels(int, 可选, 默认为 64) — 输出中的通道数。 -
project_pos_dim(int, 可选, 默认为-1) — 要投影到的位置编码的维度。如果为-1,则不应用投影。 -
*
*position_encoding_kwargs(Dict, 可选) — 位置编码的关键字参数。
感知器编码器的音频预处理。
感知器多模态预处理器
class transformers.models.perceiver.modeling_perceiver.PerceiverMultimodalPreprocessor
( modalities: Mapping mask_probs: Optional = None min_padding_size: int = 2 )
参数
-
modalities(Mapping[str, PreprocessorType]) — 将模态名称映射到预处理器的字典。 -
mask_probs(Dict[str, float]) — 将模态名称映射到该模态的掩蔽概率的字典。 -
min_padding_size(int, 可选, 默认为 2) — 所有模态的最小填充大小。最终输出将具有通道数,等于所有模态中最大通道数加上 min_padding_size。
感知器编码器的多模态预处理。
对每个模态进行预处理,然后使用可训练的位置嵌入进行填充,以具有相同数量的通道。
感知器投影解码器
class transformers.models.perceiver.modeling_perceiver.PerceiverProjectionDecoder
( config )
参数
config(PerceiverConfig)— 模型配置。
基准投影解码器(无交叉注意力)。
PerceiverBasicDecoder
class transformers.models.perceiver.modeling_perceiver.PerceiverBasicDecoder
( config: PerceiverConfig output_num_channels: int position_encoding_type: Optional = 'trainable' output_index_dims: Optional = None num_channels: Optional = 128 subsampled_index_dims: Optional = None qk_channels: Optional = None v_channels: Optional = None num_heads: Optional = 1 widening_factor: Optional = 1 use_query_residual: Optional = False concat_preprocessed_input: Optional = False final_project: Optional = True position_encoding_only: Optional = False **position_encoding_kwargs )
参数
-
config([PerceiverConfig])— 模型配置。 -
output_num_channels(int,optional)— 输出中的通道数。仅在设置final_project为True时使用。 -
position_encoding_type(str, optional, defaults to “trainable”) — 使用的位置编码类型。可以是“trainable”、“fourier”或“none”。 -
output_index_dims(int,optional)— 输出查询的维度数。如果‘position_encoding_type’ == ‘none’,则忽略。 -
num_channels(int,optional,默认为 128)— 解码器查询的通道数。如果‘position_encoding_type’ == ‘none’,则忽略。 -
qk_channels(int,optional)— 交叉注意力层中查询和键的通道数。 -
v_channels(int,optional)— 交叉注意力层中值的通道数。 -
num_heads(int,optional,默认为 1)— 交叉注意力层中的注意力头数。 -
widening_factor(int,optional,默认为 1)— 交叉注意力层的扩展因子。 -
use_query_residual(bool,optional,默认为False)— 是否在查询和交叉注意力层的输出之间使用残差连接。 -
concat_preprocessed_input(bool,optional,默认为False)— 是否将预处理输入连接到查询。 -
final_project(bool,optional,默认为True)— 是否将交叉注意力层的输出投影到目标维度。 -
position_encoding_only(bool,optional,默认为False)— 是否仅使用此类来定义输出查询。
基于交叉注意力的解码器。此类可用于使用交叉注意力操作解码潜在状态的最终隐藏状态,其中潜在状态生成键和值。
此类的输出形状取决于如何定义输出查询(也称为解码器查询)。
PerceiverClassificationDecoder
class transformers.models.perceiver.modeling_perceiver.PerceiverClassificationDecoder
( config **decoder_kwargs )
参数
config(PerceiverConfig)— 模型配置。
基于交叉注意力的分类解码器。用于逻辑输出的轻量级PerceiverBasicDecoder包装器。将 Perceiver 编码器的输出(形状为(batch_size,num_latents,d_latents))转换为形状为(batch_size,num_labels)的张量。查询的形状为(batch_size,1,num_labels)。
PerceiverOpticalFlowDecoder
class transformers.models.perceiver.modeling_perceiver.PerceiverOpticalFlowDecoder
( config output_image_shape output_num_channels = 2 rescale_factor = 100.0 **decoder_kwargs )
基于交叉注意力的光流解码器。
PerceiverBasicVideoAutoencodingDecoder
class transformers.models.perceiver.modeling_perceiver.PerceiverBasicVideoAutoencodingDecoder
( config: PerceiverConfig output_shape: List position_encoding_type: str **decoder_kwargs )
参数
-
config([PerceiverConfig])— 模型配置。 -
output_shape(List[int]) — 输出的形状为(batch_size, num_frames, height, width),不包括通道维度。 -
position_encoding_type(str) — 要使用的位置编码类型。可以是“trainable”、“fourier”或“none”。
基于交叉注意力的视频自编码解码器。[PerceiverBasicDecoder]的轻量级包装器,具有视频重塑逻辑。
PerceiverMultimodalDecoder
class transformers.models.perceiver.modeling_perceiver.PerceiverMultimodalDecoder
( config: PerceiverConfig modalities: Dict num_outputs: int output_num_channels: int min_padding_size: Optional = 2 subsampled_index_dims: Optional = None **decoder_kwargs )
参数
-
config([PerceiverConfig]) — 模型配置。 -
modalities(Dict[str, PerceiverAbstractDecoder]) — 将模态名称映射到该模态的解码器的字典。 -
num_outputs(int) — 解码器的输出数量。 -
output_num_channels(int) — 输出中的通道数。 -
min_padding_size(int, optional, 默认为 2) — 所有模态的最小填充大小。最终输出将具有通道数等于所有模态中最大通道数加上 min_padding_size。 -
subsampled_index_dims(Dict[str, PerceiverAbstractDecoder], optional) — 将模态名称映射到用于该模态解码器查询的子采样索引维度的字典。
通过组合单模解码器进行多模解码。构造函数的modalities参数是一个将模态名称映射到该模态的解码器的字典。该解码器将用于构造该模态的查询。特定于模态的查询使用可训练的特定于模态的参数进行填充,然后沿时间维度连接。
接下来,所有模态之间都有一个共享的交叉注意力操作。
PerceiverProjectionPostprocessor
class transformers.models.perceiver.modeling_perceiver.PerceiverProjectionPostprocessor
( in_channels: int out_channels: int )
参数
-
in_channels(int) — 输入中的通道数。 -
out_channels(int) — 输出中的通道数。
Perceiver 的投影后处理。可用于将解码器输出的通道投影到较低的维度。
PerceiverAudioPostprocessor
class transformers.models.perceiver.modeling_perceiver.PerceiverAudioPostprocessor
( config: PerceiverConfig in_channels: int postproc_type: str = 'patches' )
参数
-
config([PerceiverConfig]) — 模型配置。 -
in_channels(int) — 输入中的通道数。 -
postproc_type(str, optional, 默认为"patches") — 要使用的后处理器类型。目前只支持"patches"。
Perceiver 的音频后处理。可用于将解码器输出转换为音频特征。
PerceiverClassificationPostprocessor
class transformers.models.perceiver.modeling_perceiver.PerceiverClassificationPostprocessor
( config: PerceiverConfig in_channels: int )
参数
-
config([PerceiverConfig]) — 模型配置。 -
in_channels(int) — 输入中的通道数。
Perceiver 的分类后处理。可用于将解码器输出转换为分类 logits。
PerceiverMultimodalPostprocessor
class transformers.models.perceiver.modeling_perceiver.PerceiverMultimodalPostprocessor
( modalities: Mapping input_is_dict: bool = False )
参数
-
modalities(Mapping[str, PostprocessorType]) — 将模态名称映射到该模态的后处理器类的字典。 -
input_is_dict(bool,可选,默认为False)— 如果为 True,则假定输入为字典结构,并且输出保持相同的字典形状。如果为 False,则输入是一个张量,在后处理过程中由modality_sizes切片。
Perceiver 的多模态后处理。可用于将特定于模态的后处理器组合成单个后处理器。
PerceiverModel
class transformers.PerceiverModel
( config decoder = None input_preprocessor: Callable = None output_postprocessor: Callable = None )
参数
-
config(PerceiverConfig)— 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained()方法以加载模型权重。 -
decoder(DecoderType,可选)— 可选的解码器,用于解码编码器的潜在表示。示例包括transformers.models.perceiver.modeling_perceiver.PerceiverBasicDecoder、transformers.models.perceiver.modeling_perceiver.PerceiverClassificationDecoder、transformers.models.perceiver.modeling_perceiver.PerceiverMultimodalDecoder。 -
input_preprocessor(PreprocessorType,可选)— 可选的输入预处理器。示例包括transformers.models.perceiver.modeling_perceiver.PerceiverImagePreprocessor、transformers.models.perceiver.modeling_perceiver.PerceiverAudioPreprocessor、transformers.models.perceiver.modeling_perceiver.PerceiverTextPreprocessor、transformers.models.perceiver.modeling_perceiver.PerceiverMultimodalPreprocessor。 -
output_postprocessor(PostprocessorType,可选)— 可选的输出后处理器。示例包括transformers.models.perceiver.modeling_perceiver.PerceiverImagePostprocessor、transformers.models.perceiver.modeling_perceiver.PerceiverAudioPostprocessor、transformers.models.perceiver.modeling_perceiver.PerceiverClassificationPostprocessor、transformers.models.perceiver.modeling_perceiver.PerceiverProjectionPostprocessor、transformers.models.perceiver.modeling_perceiver.PerceiverMultimodalPostprocessor。 -
注意您可以定义自己的解码器、预处理器和/或后处理器以适应您的用例。—
感知器:一种可扩展的完全注意力架构。此模型是 PyTorch torch.nn.Module子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取与一般用法和行为相关的所有事项。
forward
( inputs: FloatTensor attention_mask: Optional = None subsampled_output_points: Optional = None head_mask: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.models.perceiver.modeling_perceiver.PerceiverModelOutput or tuple(torch.FloatTensor)
参数
-
inputs(torch.FloatTensor)— 输入到感知器。可以是任何内容:图像、文本、音频、视频等。 -
attention_mask(形状为(batch_size, sequence_length)的torch.FloatTensor,可选)— 用于避免在填充标记索引上执行注意力的遮罩。选择在[0, 1]范围内的遮罩值:-
1 表示未被遮罩的标记,
-
0 表示被遮罩的标记。
什么是注意力遮罩?
-
-
head_mask(形状为(num_heads,)或(num_layers, num_heads)的torch.FloatTensor,可选)— 用于使自注意力模块的选定头部失效的遮罩。选择在[0, 1]范围内的遮罩值:-
1 表示头部未被遮罩,
-
0 表示头部被遮罩。
-
-
output_attentions(bool,可选)— 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 -
output_hidden_states(bool,可选)— 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool,可选)- 是否返回 ModelOutput 而不是普通元组。
返回值
transformers.models.perceiver.modeling_perceiver.PerceiverModelOutput 或tuple(torch.FloatTensor)
transformers.models.perceiver.modeling_perceiver.PerceiverModelOutput 或一个torch.FloatTensor元组(如果传递return_dict=False或config.return_dict=False时)包含各种元素,取决于配置(PerceiverConfig)和输入。
-
logits(形状为(batch_size, num_labels)的torch.FloatTensor)- 分类(如果 config.num_labels==1 则为回归)得分(SoftMax 之前)。 -
last_hidden_state(形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor)- 模型最后一层的隐藏状态序列。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回)- 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组。模型在每一层输出的隐藏状态加上初始嵌入输出。 -
attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回)- 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。 -
cross_attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回)- 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组。解码器的交叉注意力层的注意力权重,在注意力 softmax 后,用于计算交叉注意力头中的加权平均值。
PerceiverModel 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用Module实例,而不是在此之后调用,因为前者负责运行前处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import PerceiverConfig, PerceiverTokenizer, PerceiverImageProcessor, PerceiverModel
>>> from transformers.models.perceiver.modeling_perceiver import (
... PerceiverTextPreprocessor,
... PerceiverImagePreprocessor,
... PerceiverClassificationDecoder,
... )
>>> import torch
>>> import requests
>>> from PIL import Image
>>> # EXAMPLE 1: using the Perceiver to classify texts
>>> # - we define a TextPreprocessor, which can be used to embed tokens
>>> # - we define a ClassificationDecoder, which can be used to decode the
>>> # final hidden states of the latents to classification logits
>>> # using trainable position embeddings
>>> config = PerceiverConfig()
>>> preprocessor = PerceiverTextPreprocessor(config)
>>> decoder = PerceiverClassificationDecoder(
... config,
... num_channels=config.d_latents,
... trainable_position_encoding_kwargs=dict(num_channels=config.d_latents, index_dims=1),
... use_query_residual=True,
... )
>>> model = PerceiverModel(config, input_preprocessor=preprocessor, decoder=decoder)
>>> # you can then do a forward pass as follows:
>>> tokenizer = PerceiverTokenizer()
>>> text = "hello world"
>>> inputs = tokenizer(text, return_tensors="pt").input_ids
>>> with torch.no_grad():
... outputs = model(inputs=inputs)
>>> logits = outputs.logits
>>> list(logits.shape)
[1, 2]
>>> # to train, one can train the model using standard cross-entropy:
>>> criterion = torch.nn.CrossEntropyLoss()
>>> labels = torch.tensor([1])
>>> loss = criterion(logits, labels)
>>> # EXAMPLE 2: using the Perceiver to classify images
>>> # - we define an ImagePreprocessor, which can be used to embed images
>>> config = PerceiverConfig(image_size=224)
>>> preprocessor = PerceiverImagePreprocessor(
... config,
... prep_type="conv1x1",
... spatial_downsample=1,
... out_channels=256,
... position_encoding_type="trainable",
... concat_or_add_pos="concat",
... project_pos_dim=256,
... trainable_position_encoding_kwargs=dict(
... num_channels=256,
... index_dims=config.image_size**2,
... ),
... )
>>> model = PerceiverModel(
... config,
... input_preprocessor=preprocessor,
... decoder=PerceiverClassificationDecoder(
... config,
... num_channels=config.d_latents,
... trainable_position_encoding_kwargs=dict(num_channels=config.d_latents, index_dims=1),
... use_query_residual=True,
... ),
... )
>>> # you can then do a forward pass as follows:
>>> image_processor = PerceiverImageProcessor()
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = image_processor(image, return_tensors="pt").pixel_values
>>> with torch.no_grad():
... outputs = model(inputs=inputs)
>>> logits = outputs.logits
>>> list(logits.shape)
[1, 2]
>>> # to train, one can train the model using standard cross-entropy:
>>> criterion = torch.nn.CrossEntropyLoss()
>>> labels = torch.tensor([1])
>>> loss = criterion(logits, labels)
PerceiverForMaskedLM
class transformers.PerceiverForMaskedLM
( config: PerceiverConfig )
参数
config(PerceiverConfig)- 模型的所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained()方法以加载模型权重。
Perceiver 用于填充语言建模的示例用法。此模型是 PyTorch torch.nn.Module子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取与一般用法和行为相关的所有信息。
forward
( inputs: Optional = None attention_mask: Optional = None head_mask: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None labels: Optional = None return_dict: Optional = None input_ids: Optional = None ) → export const metadata = 'undefined';transformers.models.perceiver.modeling_perceiver.PerceiverMaskedLMOutput or tuple(torch.FloatTensor)
参数
-
inputs(torch.FloatTensor) — 输入到感知器。可以是任何内容:图像、文本、音频、视频等。 -
attention_mask(torch.FloatTensor,形状为batch_size, sequence_length,optional) — 用于避免在填充标记索引上执行注意力的掩码。掩码值在[0, 1]中选择:-
1 表示
not masked的标记, -
0 表示
masked的标记。
什么是注意力掩码?
-
-
head_mask(torch.FloatTensor,形状为(num_heads,)或(num_layers, num_heads),optional) — 用于使自注意力模块中选择的头部失效的掩码。掩码值在[0, 1]中选择:-
1 表示头部是
not masked, -
0 表示头部被
masked。
-
-
output_attentions(bool,optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量中的attentions。 -
output_hidden_states(bool,optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量中的hidden_states。 -
return_dict(bool,optional) — 是否返回 ModelOutput 而不是普通元组。 -
labels(torch.LongTensor,形状为(batch_size, sequence_length),optional) — 用于计算掩码语言建模损失的标签。索引应在[-100, 0, ..., config.vocab_size]内(请参阅input_ids文档字符串)。索引设置为-100的标记将被忽略(masked),损失仅计算具有标签在[0, ..., config.vocab_size]内的标记
返回
transformers.models.perceiver.modeling_perceiver.PerceiverMaskedLMOutput 或tuple(torch.FloatTensor)
一个 transformers.models.perceiver.modeling_perceiver.PerceiverMaskedLMOutput 或一个torch.FloatTensor元组(如果传递了return_dict=False或config.return_dict=False)包括根据配置(PerceiverConfig)和输入的各种元素。
-
loss(torch.FloatTensor,形状为(1,),optional, 当提供labels时返回) — 掩码语言建模(MLM)损失。 -
logits(torch.FloatTensor,形状为(batch_size, sequence_length, config.vocab_size)) — 语言建模头部的预测分数(SoftMax 之前每个词汇标记的分数)。 -
hidden_states(tuple(torch.FloatTensor), optional, 当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组。每层输出的隐藏状态加上初始嵌入输出。 -
attentions(tuple(torch.FloatTensor), optional, 当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, num_latents, num_latents)的torch.FloatTensor元组。自注意力头部中的注意力权重 softmax 后,用于计算加权平均值。 -
cross_attentions(tuple(torch.FloatTensor), optional, 当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组。解码器的交叉注意力层的注意力权重,在注意力 softmax 后使用,用于计算交叉注意力头部中的加权平均值。
PerceiverForMaskedLM 的前向方法,覆盖__call__特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用 Module 实例,而不是在此处调用,因为前者会处理运行前后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, PerceiverForMaskedLM
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("deepmind/language-perceiver")
>>> model = PerceiverForMaskedLM.from_pretrained("deepmind/language-perceiver")
>>> # training
>>> text = "This is an incomplete sentence where some words are missing."
>>> inputs = tokenizer(text, padding="max_length", return_tensors="pt")
>>> # mask " missing."
>>> inputs["input_ids"][0, 52:61] = tokenizer.mask_token_id
>>> labels = tokenizer(text, padding="max_length", return_tensors="pt").input_ids
>>> outputs = model(**inputs, labels=labels)
>>> loss = outputs.loss
>>> round(loss.item(), 2)
19.87
>>> logits = outputs.logits
>>> list(logits.shape)
[1, 2048, 262]
>>> # inference
>>> text = "This is an incomplete sentence where some words are missing."
>>> encoding = tokenizer(text, padding="max_length", return_tensors="pt")
>>> # mask bytes corresponding to " missing.". Note that the model performs much better if the masked span starts with a space.
>>> encoding["input_ids"][0, 52:61] = tokenizer.mask_token_id
>>> # forward pass
>>> with torch.no_grad():
... outputs = model(**encoding)
>>> logits = outputs.logits
>>> list(logits.shape)
[1, 2048, 262]
>>> masked_tokens_predictions = logits[0, 52:61].argmax(dim=-1).tolist()
>>> tokenizer.decode(masked_tokens_predictions)
' missing.'
PerceiverForSequenceClassification
class transformers.PerceiverForSequenceClassification
( config )
参数
config(PerceiverConfig) — 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只加载配置。查看 from_pretrained() 方法以加载模型权重。
Perceiver 用于文本分类的示例。这个模型是 PyTorch 的 torch.nn.Module 子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以获取与一般用法和行为相关的所有内容。
forward
( inputs: Optional = None attention_mask: Optional = None head_mask: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None labels: Optional = None return_dict: Optional = None input_ids: Optional = None ) → export const metadata = 'undefined';transformers.models.perceiver.modeling_perceiver.PerceiverClassifierOutput or tuple(torch.FloatTensor)
参数
-
inputs(torch.FloatTensor) — Perceiver 的输入。可以是任何东西:图像、文本、音频、视频等。 -
attention_mask(torch.FloatTensor,形状为batch_size, sequence_length,可选) — 用于避免在填充标记索引上执行注意力的掩码。掩码值选定在[0, 1]:-
1 表示标记未被
masked, -
对于被
masked的标记为 0。
什么是注意力掩码?
-
-
head_mask(torch.FloatTensor,形状为(num_heads,)或(num_layers, num_heads),可选) — 用于使自注意力模块中的选定头部失效的掩码。掩码值选定在[0, 1]:-
1 表示头部未被
masked, -
0 表示头部被
masked。
-
-
output_attentions(bool,可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 -
output_hidden_states(bool,可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool,可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。 -
labels(torch.LongTensor,形状为(batch_size,),可选) — 用于计算分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]。如果config.num_labels == 1,则计算回归损失(均方损失),如果config.num_labels > 1,则计算分类损失(交叉熵)。
返回值
transformers.models.perceiver.modeling_perceiver.PerceiverClassifierOutput 或者 tuple(torch.FloatTensor)
transformers.models.perceiver.modeling_perceiver.PerceiverClassifierOutput 或者一个 torch.FloatTensor 元组(如果传递了 return_dict=False 或者 config.return_dict=False)包含各种元素,取决于配置(PerceiverConfig)和输入。
-
loss(torch.FloatTensor,形状为(1,),可选,当提供labels时返回) — 分类(如果config.num_labels==1则为回归)损失。 -
logits(torch.FloatTensor,形状为(batch_size, config.num_labels)) — 分类(如果config.num_labels==1则为回归)分数(SoftMax 之前)。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回)- 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(一个用于嵌入的输出 + 一个用于每个层的输出)。模型在每一层的输出的隐藏状态加上初始嵌入输出。 -
attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回)- 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。在注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。 -
cross_attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回)- 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。解码器的交叉注意力层的注意力权重,在注意力 softmax 之后,用于计算交叉注意力头中的加权平均值。
PerceiverForSequenceClassification 的前向方法,覆盖了__call__特殊方法。
尽管前向传递的配方需要在此函数内定义,但应该在此之后调用Module实例,而不是这个,因为前者负责运行前处理和后处理步骤,而后者则默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, PerceiverForSequenceClassification
>>> tokenizer = AutoTokenizer.from_pretrained("deepmind/language-perceiver")
>>> model = PerceiverForSequenceClassification.from_pretrained("deepmind/language-perceiver")
>>> text = "hello world"
>>> inputs = tokenizer(text, return_tensors="pt").input_ids
>>> outputs = model(inputs=inputs)
>>> logits = outputs.logits
>>> list(logits.shape)
[1, 2]
PerceiverForImageClassificationLearned
class transformers.PerceiverForImageClassificationLearned
( config )
参数
config(PerceiverConfig)- 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
Perceiver 用于图像分类的示例用法,例如 ImageNet 任务。
该模型使用了学习的位置嵌入。换句话说,该模型没有关于图像结构的特权信息。正如论文中所示,该模型在 ImageNet 上可以达到 72.7 的 top-1 准确率。
PerceiverForImageClassificationLearned 使用 PerceiverImagePreprocessor(使用prep_type="conv1x1")来预处理输入图像,并使用 PerceiverClassificationDecoder 来解码 PerceiverModel 的潜在表示为分类 logits。
该模型是 PyTorch 的torch.nn.Module子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以获取与一般用法和行为相关的所有事项。
forward
( inputs: Optional = None attention_mask: Optional = None head_mask: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None labels: Optional = None return_dict: Optional = None pixel_values: Optional = None ) → export const metadata = 'undefined';transformers.models.perceiver.modeling_perceiver.PerceiverClassifierOutput or tuple(torch.FloatTensor)
参数
-
inputs(torch.FloatTensor)- 传递者的输入。可以是任何东西:图像、文本、音频、视频等。 -
attention_mask(形状为batch_size, sequence_length的torch.FloatTensor,可选) — 避免在填充标记索引上执行注意力的掩码。选择的掩码值在[0, 1]中:-
1 表示未被“masked”的标记。
-
对于被
masked掩盖的标记。
什么是注意力掩码?
-
-
head_mask(形状为(num_heads,)或(num_layers, num_heads)的torch.FloatTensor,可选) — 用于使自注意力模块的选定头部失效的掩码。选择的掩码值在[0, 1]中:-
1 表示头部未被“masked”,
-
0 表示头部被
masked。
-
-
output_attentions(bool,可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 -
output_hidden_states(bool,可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool,可选) — 是否返回 ModelOutput 而不是普通元组。 -
labels(形状为(batch_size,)的torch.LongTensor,可选) — 用于计算图像分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]中。如果config.num_labels == 1,则计算回归损失(均方损失),如果config.num_labels > 1,则计算分类损失(交叉熵)。
返回
transformers.models.perceiver.modeling_perceiver.PerceiverClassifierOutput 或tuple(torch.FloatTensor)
一个 transformers.models.perceiver.modeling_perceiver.PerceiverClassifierOutput 或一个torch.FloatTensor元组(如果传递了return_dict=False或当config.return_dict=False时)包含各种元素,取决于配置(PerceiverConfig)和输入。
-
loss(形状为(1,)的torch.FloatTensor,可选,在提供labels时返回) — 分类(如果config.num_labels==1则为回归)损失。 -
logits(形状为(batch_size, config.num_labels)的torch.FloatTensor) — 分类(如果config.num_labels==1则为回归)分数(SoftMax 之前)。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组。模型在每一层输出的隐藏状态加上初始嵌入输出。 -
attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或当config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组。注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。 -
cross_attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或当config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组。解码器的交叉注意力层的注意力权重,在注意力 softmax 之后,用于计算交叉注意力头中的加权平均值。
PerceiverForImageClassificationLearned 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用Module实例,而不是在此处调用,因为前者会负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoImageProcessor, PerceiverForImageClassificationLearned
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("deepmind/vision-perceiver-learned")
>>> model = PerceiverForImageClassificationLearned.from_pretrained("deepmind/vision-perceiver-learned")
>>> inputs = image_processor(images=image, return_tensors="pt").pixel_values
>>> outputs = model(inputs=inputs)
>>> logits = outputs.logits
>>> list(logits.shape)
[1, 1000]
>>> # model predicts one of the 1000 ImageNet classes
>>> predicted_class_idx = logits.argmax(-1).item()
>>> print("Predicted class:", model.config.id2label[predicted_class_idx])
Predicted class: tabby, tabby cat
PerceiverForImageClassificationFourier
class transformers.PerceiverForImageClassificationFourier
( config )
参数
config(PerceiverConfig)— 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained()方法以加载模型权重。
使用 Perceiver 进行图像分类的示例,例如 ImageNet 任务。
该模型使用固定的 2D Fourier 位置嵌入。如论文所示,该模型在 ImageNet 上可以达到 79.0 的 top-1 准确率,在大规模数据集(即 JFT)上预训练时可以达到 84.5 的准确率。
PerceiverForImageClassificationLearned 使用 PerceiverImagePreprocessor(使用prep_type="pixels")来预处理输入图像,并使用 PerceiverClassificationDecoder 来解码 PerceiverModel 的潜在表示为分类 logits。
该模型是 PyTorch torch.nn.Module的子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有信息。
forward
( inputs: Optional = None attention_mask: Optional = None head_mask: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None labels: Optional = None return_dict: Optional = None pixel_values: Optional = None ) → export const metadata = 'undefined';transformers.models.perceiver.modeling_perceiver.PerceiverClassifierOutput or tuple(torch.FloatTensor)
参数
-
inputs(torch.FloatTensor)— 输入到感知器。可以是任何内容:图像、文本、音频、视频等。 -
attention_mask(形状为batch_size, sequence_length的torch.FloatTensor,可选)— 用于避免在填充标记索引上执行注意力的掩码。选择的掩码值为[0, 1]:-
对于未被掩盖的标记,
-
0 表示头部被掩盖。
什么是注意力掩码?
-
-
head_mask(形状为(num_heads,)或(num_layers, num_heads)的torch.FloatTensor,可选)— 用于使自注意力模块的选定头部失效的掩码。选择的掩码值为[0, 1]:-
1 表示头部未被掩盖,
-
0 表示头部被掩盖。
-
-
output_attentions(bool,可选)— 是否返回所有注意力层的注意力张量。有关更多详细信息,请查看返回张量下的attentions。 -
output_hidden_states(bool,可选)— 是否返回所有层的隐藏状态。有关更多详细信息,请查看返回张量下的hidden_states。 -
return_dict(bool,可选)— 是否返回一个 ModelOutput 而不是一个普通元组。 -
labels(形状为(batch_size,)的torch.LongTensor,可选)— 用于计算图像分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。如果config.num_labels == 1,则计算回归损失(均方损失),如果config.num_labels > 1,则计算分类损失(交叉熵)。
返回
transformers.models.perceiver.modeling_perceiver.PerceiverClassifierOutput 或tuple(torch.FloatTensor)
一个 transformers.models.perceiver.modeling_perceiver.PerceiverClassifierOutput 或一个torch.FloatTensor元组(如果传递return_dict=False或config.return_dict=False时)包含根据配置(PerceiverConfig)和输入的各种元素。
-
loss(形状为(1,)的torch.FloatTensor,可选,当提供labels时返回)- 分类(如果 config.num_labels==1 则为回归)损失。 -
logits(形状为(batch_size, config.num_labels)的torch.FloatTensor)- 分类(如果 config.num_labels==1 则为回归)得分(SoftMax 之前)。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回)- 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(一个用于嵌入的输出+一个用于每个层的输出)。模型在每一层输出的隐藏状态加上初始嵌入输出。 -
attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回)- 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。 -
cross_attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回)- 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。解码器的交叉注意力层的注意力权重,在注意力 softmax 之后,用于计算交叉注意力头中的加权平均值。
PerceiverForImageClassificationFourier 的前向方法,覆盖__call__特殊方法。
虽然前向传递的方法需要在此函数内定义,但应该在此之后调用Module实例,而不是在此处调用,因为前者会负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoImageProcessor, PerceiverForImageClassificationFourier
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("deepmind/vision-perceiver-fourier")
>>> model = PerceiverForImageClassificationFourier.from_pretrained("deepmind/vision-perceiver-fourier")
>>> inputs = image_processor(images=image, return_tensors="pt").pixel_values
>>> outputs = model(inputs=inputs)
>>> logits = outputs.logits
>>> list(logits.shape)
[1, 1000]
>>> # model predicts one of the 1000 ImageNet classes
>>> predicted_class_idx = logits.argmax(-1).item()
>>> print("Predicted class:", model.config.id2label[predicted_class_idx])
Predicted class: tabby, tabby cat
PerceiverForImageClassificationConvProcessing
class transformers.PerceiverForImageClassificationConvProcessing
( config )
参数
config(PerceiverConfig)- 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained()方法以加载模型权重。
使用 Perceiver 进行图像分类的示例,用于诸如 ImageNet 之类的任务。
该模型使用 2D conv+maxpool 预处理网络。如论文所示,该模型在 ImageNet 上可以实现 82.1 的 top-1 准确率。
PerceiverForImageClassificationLearned 使用 PerceiverImagePreprocessor(使用 prep_type="conv")来预处理输入图像,并使用 PerceiverClassificationDecoder 来解码 PerceiverModel 的潜在表示为分类 logits。
此模型是 PyTorch torch.nn.Module 的子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以获取与一般用法和行为相关的所有事项。
forward
( inputs: Optional = None attention_mask: Optional = None head_mask: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None labels: Optional = None return_dict: Optional = None pixel_values: Optional = None ) → export const metadata = 'undefined';transformers.models.perceiver.modeling_perceiver.PerceiverClassifierOutput or tuple(torch.FloatTensor)
参数
-
inputs(torch.FloatTensor)— 输入到感知器。可以是任何内容:图像、文本、音频、视频等。 -
attention_mask(torch.FloatTensor,形状为batch_size, sequence_length,可选)— 用于避免在填充标记索引上执行注意力的掩码。掩码值选在[0, 1]:-
1 表示
未被掩码的标记, -
0 表示标记
被掩码。
什么是注意力掩码?
-
-
head_mask(torch.FloatTensor,形状为(num_heads,)或(num_layers, num_heads),可选)— 用于使自注意力模块的选定头部失效的掩码。掩码值选在[0, 1]:-
1 表示头部
未被掩码, -
0 表示头部被
掩码。
-
-
output_attentions(bool,可选)— 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回的张量下的attentions。 -
output_hidden_states(bool,可选)— 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回的张量下的hidden_states。 -
return_dict(bool,可选)— 是否返回 ModelOutput 而不是普通元组。 -
labels(torch.LongTensor,形状为(batch_size,),可选)— 用于计算图像分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]中。如果config.num_labels == 1,则计算回归损失(均方损失),如果config.num_labels > 1,则计算分类损失(交叉熵)。
返回
transformers.models.perceiver.modeling_perceiver.PerceiverClassifierOutput 或 tuple(torch.FloatTensor)
一个 transformers.models.perceiver.modeling_perceiver.PerceiverClassifierOutput 或一个 torch.FloatTensor 元组(如果传递了 return_dict=False 或当 config.return_dict=False 时)包含根据配置(PerceiverConfig)和输入的各种元素。
-
loss(torch.FloatTensor,形状为(1,),可选,在提供labels时返回)— 分类(或回归,如果 config.num_labels==1)损失。 -
logits(torch.FloatTensor,形状为(batch_size, config.num_labels))— 分类(或回归,如果 config.num_labels==1)得分(SoftMax 之前)。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回)— 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(一个用于嵌入的输出 + 一个用于每个层的输出)。模型在每个层的输出状态加上初始嵌入输出。 -
attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回)— 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。 -
cross_attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回)— 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。解码器的交叉注意力层的注意力权重,在注意力 softmax 后使用,用于计算交叉注意力头中的加权平均值。
PerceiverForImageClassificationConvProcessing 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用Module实例,而不是在此处调用,因为前者会处理运行前后的处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoImageProcessor, PerceiverForImageClassificationConvProcessing
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("deepmind/vision-perceiver-conv")
>>> model = PerceiverForImageClassificationConvProcessing.from_pretrained("deepmind/vision-perceiver-conv")
>>> inputs = image_processor(images=image, return_tensors="pt").pixel_values
>>> outputs = model(inputs=inputs)
>>> logits = outputs.logits
>>> list(logits.shape)
[1, 1000]
>>> # model predicts one of the 1000 ImageNet classes
>>> predicted_class_idx = logits.argmax(-1).item()
>>> print("Predicted class:", model.config.id2label[predicted_class_idx])
Predicted class: tabby, tabby cat
PerceiverForOpticalFlow
class transformers.PerceiverForOpticalFlow
( config )
参数
config(PerceiverConfig)— 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
Perceiver 用于光流的示例用法,用于 Sintel 和 KITTI 等任务。PerceiverForOpticalFlow 使用 PerceiverImagePreprocessor(带prep_type=“patches”)对输入图像进行预处理,并使用 PerceiverOpticalFlowDecoder 来解码 PerceiverModel 的潜在表示。
作为输入,将 2 个连续帧沿通道维度连接起来,并提取每个像素周围的 3 x 3 补丁(导致每个像素有 3 x 3 x 3 x 2 = 54 个值)。使用固定的傅立叶位置编码来编码每个像素在补丁中的位置。接下来,应用 Perceiver 编码器。为了解码,使用与输入相同的编码查询潜在表示。
这个模型是 PyTorch torch.nn.Module子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以获取与一般用法和行为相关的所有内容。
forward
( inputs: Optional = None attention_mask: Optional = None head_mask: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None labels: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.models.perceiver.modeling_perceiver.PerceiverClassifierOutput or tuple(torch.FloatTensor)
参数
-
inputs(torch.FloatTensor)— 输入到 Perceiver 的输入。可以是任何内容:图像、文本、音频、视频等。 -
attention_mask(torch.FloatTensorof shapebatch_size, sequence_length, optional) — 用于避免在填充标记索引上执行注意力的掩码。掩码值选在[0, 1]之间:-
1 表示未被掩盖的标记,
-
0 表示被掩盖的标记。
什么是注意力掩码?
-
-
head_mask(torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — 用于使自注意力模块中选择的头部失效的掩码。掩码值选在[0, 1]之间:-
1 表示头部未被掩盖,
-
0 表示头部被掩盖。
-
-
output_attentions(bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量中的attentions。 -
output_hidden_states(bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量中的hidden_states。 -
return_dict(bool, optional) — 是否返回 ModelOutput 而不是普通元组。 -
labels(torch.LongTensorof shape(batch_size,), optional) — 用于计算光流损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。
返回值
transformers.models.perceiver.modeling_perceiver.PerceiverClassifierOutput 或 tuple(torch.FloatTensor)
一个 transformers.models.perceiver.modeling_perceiver.PerceiverClassifierOutput 或者一个 torch.FloatTensor 元组(如果传递 return_dict=False 或者 config.return_dict=False)包含根据配置(PerceiverConfig)和输入不同的元素。
-
loss(torch.FloatTensorof shape(1,), optional, 当提供labels时返回) — 分类(如果config.num_labels==1则为回归)损失。 -
logits(torch.FloatTensorof shape(batch_size, config.num_labels)) — 分类(如果config.num_labels==1则为回归)得分(SoftMax 之前)。 -
hidden_states(tuple(torch.FloatTensor), optional, 当传递output_hidden_states=True或者config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(一个用于嵌入的输出 + 一个用于每层的输出)。模型在每层输出的隐藏状态加上初始嵌入输出。 -
attentions(tuple(torch.FloatTensor), optional, 当传递output_attentions=True或者config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。 -
cross_attentions(tuple(torch.FloatTensor), optional, 当传递output_attentions=True或者config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。解码器的交叉注意力层的注意力权重,在注意力 softmax 之后,用于计算交叉注意力头中的加权平均值。
PerceiverForOpticalFlow 的前向方法,覆盖了 __call__ 特殊方法。
尽管前向传递的步骤需要在此函数内定义,但应该在此之后调用 Module 实例,而不是在此处调用,因为前者会负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import PerceiverForOpticalFlow
>>> import torch
>>> model = PerceiverForOpticalFlow.from_pretrained("deepmind/optical-flow-perceiver")
>>> # in the Perceiver IO paper, the authors extract a 3 x 3 patch around each pixel,
>>> # leading to 3 x 3 x 3 = 27 values for each pixel (as each pixel also has 3 color channels)
>>> # patches have shape (batch_size, num_frames, num_channels, height, width)
>>> # the authors train on resolutions of 368 x 496
>>> patches = torch.randn(1, 2, 27, 368, 496)
>>> outputs = model(inputs=patches)
>>> logits = outputs.logits
>>> list(logits.shape)
[1, 368, 496, 2]
PerceiverForMultimodalAutoencoding
class transformers.PerceiverForMultimodalAutoencoding
( config: PerceiverConfig )
参数
config(PerceiverConfig) — 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只加载配置。查看 from_pretrained() 方法以加载模型权重。
Perceiver 用于多模态(视频)自编码的示例用法,用于类似 Kinetics-700 的任务。
PerceiverForMultimodalAutoencoding 使用 PerceiverMultimodalPreprocessor 来预处理 3 种模态:图像、音频和类标签。该预处理器使用模态特定的预处理器来分别预处理每种模态,然后将它们连接起来。可训练的位置嵌入用于将每种模态填充到相同数量的通道,以便沿着时间维度进行连接。接下来,应用 Perceiver 编码器。
PerceiverMultimodalDecoder 用于解码 PerceiverModel 的潜在表示。该解码器使用每个模态特定的解码器来构建查询。解码器查询是基于预处理后的输入创建的。然而,在单个前向传递中对整个视频进行自编码在计算上是不可行的,因此只使用解码器查询的部分与潜在表示进行交叉注意力。这由每个模态的子采样索引确定,可以作为额外输入提供给 PerceiverForMultimodalAutoencoding 的前向传递。
PerceiverMultimodalDecoder 还会将不同模态的解码器查询填充到相同数量的通道中,以便沿着时间维度进行连接。接下来,执行与 PerceiverModel 的潜在表示的交叉注意力。
最后,~models.perceiver.modeling_perceiver.PerceiverMultiModalPostprocessor 用于将此张量转换为实际视频。首先将输出分割为不同的模态,然后为每个模态应用相应的后处理器。
请注意,在评估过程中通过对分类标签进行掩码(即简单地为“标签”模态提供零张量),此自编码模型变为 Kinetics 700 视频分类器。
该模型是 PyTorch torch.nn.Module 的子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以获取与一般用法和行为相关的所有事项。
forward
( inputs: Optional = None attention_mask: Optional = None subsampled_output_points: Optional = None head_mask: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None labels: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.models.perceiver.modeling_perceiver.PerceiverClassifierOutput or tuple(torch.FloatTensor)
参数
-
inputs(torch.FloatTensor) — Perceiver 的输入。可以是任何内容:图像、文本、音频、视频等。 -
attention_mask(torch.FloatTensorof shapebatch_size, sequence_length, optional) — 用于避免在填充标记索引上执行注意力的掩码。掩码值选择在[0, 1]之间:-
对于未被掩码的标记,值为 1,
-
对于被
masked的标记为 0。
什么是注意力掩码?
-
-
head_mask(torch.FloatTensor,形状为(num_heads,)或(num_layers, num_heads),可选) — 用于使自注意力模块的选定头部失效的掩码。掩码值选定在[0, 1]范围内:-
1 表示头部未被
masked, -
0 表示头部被
masked。
-
-
output_attentions(bool,可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量中的attentions。 -
output_hidden_states(bool,可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量中的hidden_states。 -
return_dict(bool,可选) — 是否返回 ModelOutput 而不是普通元组。 -
labels(torch.LongTensor,形状为(batch_size,),可选) — 用于计算图像分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。如果config.num_labels == 1,则计算回归损失(均方损失),如果config.num_labels > 1,则计算分类损失(交叉熵)。
返回
transformers.models.perceiver.modeling_perceiver.PerceiverClassifierOutput 或 tuple(torch.FloatTensor)
一个 transformers.models.perceiver.modeling_perceiver.PerceiverClassifierOutput 或一个torch.FloatTensor元组(如果传递return_dict=False或config.return_dict=False)包含根据配置(PerceiverConfig)和输入不同元素。
-
loss(torch.FloatTensor,形状为(1,),可选,当提供labels时返回) — 分类(如果 config.num_labels==1 则为回归)损失。 -
logits(torch.FloatTensor,形状为(batch_size, config.num_labels)) — 分类(如果 config.num_labels==1 则为回归)得分(SoftMax 之前)。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(一个用于嵌入的输出 + 一个用于每层的输出)。模型在每层输出的隐藏状态加上初始嵌入输出。 -
attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。 -
cross_attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。解码器交叉注意力层的注意力权重,在注意力 softmax 之后,用于计算交叉注意力头中的加权平均值。
PerceiverForMultimodalAutoencoding 的前向方法,覆盖__call__特殊方法。
尽管前向传递的步骤需要在此函数内定义,但应该在此之后调用Module实例而不是这个,因为前者会处理运行前后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import PerceiverForMultimodalAutoencoding
>>> import torch
>>> import numpy as np
>>> # create multimodal inputs
>>> images = torch.randn((1, 16, 3, 224, 224))
>>> audio = torch.randn((1, 30720, 1))
>>> inputs = dict(image=images, audio=audio, label=torch.zeros((images.shape[0], 700)))
>>> model = PerceiverForMultimodalAutoencoding.from_pretrained("deepmind/multimodal-perceiver")
>>> # in the Perceiver IO paper, videos are auto-encoded in chunks
>>> # each chunk subsamples different index dimensions of the image and audio modality decoder queries
>>> nchunks = 128
>>> image_chunk_size = np.prod((16, 224, 224)) // nchunks
>>> audio_chunk_size = audio.shape[1] // model.config.samples_per_patch // nchunks
>>> # process the first chunk
>>> chunk_idx = 0
>>> subsampling = {
... "image": torch.arange(image_chunk_size * chunk_idx, image_chunk_size * (chunk_idx + 1)),
... "audio": torch.arange(audio_chunk_size * chunk_idx, audio_chunk_size * (chunk_idx + 1)),
... "label": None,
... }
>>> outputs = model(inputs=inputs, subsampled_output_points=subsampling)
>>> logits = outputs.logits
>>> list(logits["audio"].shape)
[1, 240]
>>> list(logits["image"].shape)
[1, 6272, 3]
>>> list(logits["label"].shape)
[1, 700]
tTensor)`
一个 transformers.models.perceiver.modeling_perceiver.PerceiverClassifierOutput 或一个torch.FloatTensor元组(如果传递return_dict=False或config.return_dict=False)包含根据配置(PerceiverConfig)和输入不同元素。
-
loss(torch.FloatTensor,形状为(1,),可选,当提供labels时返回) — 分类(如果 config.num_labels==1 则为回归)损失。 -
logits(torch.FloatTensor,形状为(batch_size, config.num_labels)) — 分类(如果 config.num_labels==1 则为回归)得分(SoftMax 之前)。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(一个用于嵌入的输出 + 一个用于每层的输出)。模型在每层输出的隐藏状态加上初始嵌入输出。 -
attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。 -
cross_attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。解码器交叉注意力层的注意力权重,在注意力 softmax 之后,用于计算交叉注意力头中的加权平均值。
PerceiverForMultimodalAutoencoding 的前向方法,覆盖__call__特殊方法。
尽管前向传递的步骤需要在此函数内定义,但应该在此之后调用Module实例而不是这个,因为前者会处理运行前后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import PerceiverForMultimodalAutoencoding
>>> import torch
>>> import numpy as np
>>> # create multimodal inputs
>>> images = torch.randn((1, 16, 3, 224, 224))
>>> audio = torch.randn((1, 30720, 1))
>>> inputs = dict(image=images, audio=audio, label=torch.zeros((images.shape[0], 700)))
>>> model = PerceiverForMultimodalAutoencoding.from_pretrained("deepmind/multimodal-perceiver")
>>> # in the Perceiver IO paper, videos are auto-encoded in chunks
>>> # each chunk subsamples different index dimensions of the image and audio modality decoder queries
>>> nchunks = 128
>>> image_chunk_size = np.prod((16, 224, 224)) // nchunks
>>> audio_chunk_size = audio.shape[1] // model.config.samples_per_patch // nchunks
>>> # process the first chunk
>>> chunk_idx = 0
>>> subsampling = {
... "image": torch.arange(image_chunk_size * chunk_idx, image_chunk_size * (chunk_idx + 1)),
... "audio": torch.arange(audio_chunk_size * chunk_idx, audio_chunk_size * (chunk_idx + 1)),
... "label": None,
... }
>>> outputs = model(inputs=inputs, subsampled_output_points=subsampling)
>>> logits = outputs.logits
>>> list(logits["audio"].shape)
[1, 240]
>>> list(logits["image"].shape)
[1, 6272, 3]
>>> list(logits["label"].shape)
[1, 700]

尧米是由西云算力与CSDN联合运营的AI算力和模型开源社区品牌,为基于DaModel智算平台的AI应用企业和泛AI开发者提供技术交流与成果转化平台。
更多推荐

 12
12 0
0- 0



 已为社区贡献51条内容
已为社区贡献51条内容

所有评论(0)