Transformer 自然语言处理(三)
原文:Natural Language Processing with Transformers译者:飞龙协议:CC BY-NC-SA 4.0第八章:使 transformers 在生产中更高效在之前的章节中,您已经看到了 transformers 如何被微调以在各种任务上产生出色的结果。然而,在许多情况下,准确性(或者您正在优化的任何指标)是不够的;如果您的最先进模型太慢或太大,无法满足应用程序
原文:Natural Language Processing with Transformers
译者:飞龙
第八章:使 transformers 在生产中更高效
在之前的章节中,您已经看到了 transformers 如何被微调以在各种任务上产生出色的结果。然而,在许多情况下,准确性(或者您正在优化的任何指标)是不够的;如果您的最先进模型太慢或太大,无法满足应用程序的业务需求,那么它就不是很有用。一个明显的替代方案是训练一个更快、更紧凑的模型,但模型容量的减少通常会伴随着性能的下降。那么当您需要一个快速、紧凑但高度准确的模型时,您该怎么办呢?
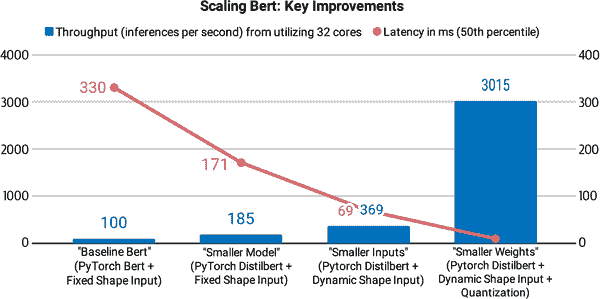
在本章中,我们将探讨四种互补的技术,可以用来加速预测并减少您的 transformer 模型的内存占用:知识蒸馏、量化、修剪和使用 Open Neural Network Exchange (ONNX)格式和 ONNX Runtime (ORT)进行图优化。我们还将看到其中一些技术如何结合起来产生显著的性能提升。例如,这是 Roblox 工程团队在他们的文章“我们如何在 CPU 上扩展 BERT 以处理 10 亿+日请求”中采取的方法,正如图 8-1 所示,他们发现结合知识蒸馏和量化使他们的 BERT 分类器的延迟和吞吐量提高了 30 倍以上!

图 8-1. Roblox 如何通过知识蒸馏、动态填充和权重量化扩展 BERT(照片由 Roblox 员工 Quoc N. Le 和 Kip Kaehler 提供)
为了说明与每种技术相关的好处和权衡,我们将以意图检测为案例研究;这是基于文本的助手的重要组成部分,低延迟对于实时维持对话至关重要。在学习的过程中,您将学习如何创建自定义训练器,执行高效的超参数搜索,并了解实施最前沿研究所需的内容,使用 Transformers。让我们开始吧!
Transformers。让我们开始吧!
以意图检测为案例研究
假设我们正在尝试为公司的呼叫中心构建一个基于文本的助手,以便客户可以在不需要与人类代理交谈的情况下请求其账户余额或进行预订。为了理解客户的目标,我们的助手需要能够将各种自然语言文本分类为一组预定义的动作或意图。例如,客户可能会发送以下关于即将到来的旅行的消息:
嘿,我想在 11 月 1 日到 11 月 15 日在巴黎租一辆车,我需要一辆 15 座位的面包车。
我们的意图分类器可以自动将此分类为租车意图,然后触发一个动作和响应。为了在生产环境中具有鲁棒性,我们的分类器还需要能够处理超出范围的查询,即客户提出不属于任何预定义意图的查询,系统应该产生一个回退响应。例如,在图 8-2 中显示的第二种情况中,客户询问有关体育的问题(超出范围),文本助手错误地将其分类为已知的范围内意图之一,并返回发薪日的响应。在第三种情况下,文本助手已经被训练来检测超出范围的查询(通常标记为一个单独的类),并告知客户它可以回答关于哪些主题的问题。

图 8-2. 人类(右)和基于文本的助手(左)之间的三次交流,涉及个人理财(由 Stefan Larson 等人提供)
作为基准,我们微调了一个 BERT-base 模型,在 CLINC150 数据集上达到了约 94%的准确性。这个数据集包括 150 个意图和 10 个领域(如银行和旅行)中的 22,500 个范围内查询,还包括属于oos意图类别的 1,200 个范围外查询。在实践中,我们还会收集自己的内部数据集,但使用公共数据是快速迭代和生成初步结果的好方法。
让我们从 Hugging Face Hub 下载我们微调的模型,并将其包装成文本分类的管道:
from transformers import pipeline
bert_ckpt = "transformersbook/bert-base-uncased-finetuned-clinc"
pipe = pipeline("text-classification", model=bert_ckpt)
现在我们有了一个管道,我们可以传递一个查询以从模型获取预测的意图和置信度分数:
query = """Hey, I'd like to rent a vehicle from Nov 1st to Nov 15th in
Paris and I need a 15 passenger van"""
pipe(query)
[{'label': 'car_rental', 'score': 0.549003541469574}]
很好,car_rental意图是有意义的。现在让我们看看创建一个基准,我们可以用来评估我们基准模型的性能。
创建性能基准
与其他机器学习模型一样,在生产环境中部署 transformers 涉及在几个约束条件之间进行权衡,最常见的是:
模型性能
我们的模型在反映生产数据的精心设计的测试集上表现如何?当错误的成本很高时(最好通过人为干预来减轻),或者当我们需要对数百万个示例进行推断,并且模型指标的小幅改进可以转化为大幅增益时,这一点尤为重要。
延迟
我们的模型能够多快地提供预测?我们通常关心实时环境中的延迟,这些环境处理大量流量,就像 Stack Overflow 需要一个分类器来快速检测网站上不受欢迎的评论一样。
内存
我们如何部署像 GPT-2 或 T5 这样需要占用几 GB 磁盘存储和内存的百亿参数模型?内存在移动设备或边缘设备中扮演着特别重要的角色,因为模型必须在没有强大的云服务器的情况下生成预测。
未能解决这些约束条件可能会对应用程序的用户体验产生负面影响。更常见的是,可能会导致运行昂贵的云服务器的成本激增,而这些服务器可能只需要处理少量请求。为了探索如何使用各种压缩技术优化这些约束条件,让我们从创建一个简单的基准开始,该基准可以测量给定管道和测试集的每个数量:
class PerformanceBenchmark:
def __init__(self, pipeline, dataset, optim_type="BERT baseline"):
self.pipeline = pipeline
self.dataset = dataset
self.optim_type = optim_type
def compute_accuracy(self):
# We'll define this later
pass
def compute_size(self):
# We'll define this later
pass
def time_pipeline(self):
# We'll define this later
pass
def run_benchmark(self):
metrics = {}
metrics[self.optim_type] = self.compute_size()
metrics[self.optim_type].update(self.time_pipeline())
metrics[self.optim_type].update(self.compute_accuracy())
return metrics
我们定义了一个optim_type参数,以跟踪我们在本章中将涵盖的不同优化技术。我们将使用run_benchmark()方法将所有指标收集到一个字典中,键由optim_type给出。
让我们现在通过在测试集上计算模型的准确性来为这个类添加一些具体内容。首先,我们需要一些数据进行测试,所以让我们下载用于微调基准模型的 CLINC150 数据集。我们可以通过以下方式从 Hub 获取数据集: 。
。
from datasets import load_dataset
clinc = load_dataset("clinc_oos", "plus")
在这里,plus配置是指包含超出范围的训练示例的子集。CLINC150 数据集中的每个示例都包括text列中的查询及其对应的意图。我们将使用测试集来对我们的模型进行基准测试,所以让我们看一下数据集的一个示例:
sample = clinc["test"][42]
sample
{'intent': 133, 'text': 'transfer $100 from my checking to saving account'}
意图以 ID 的形式提供,但我们可以通过访问数据集的features属性轻松获取到字符串的映射(反之亦然):
intents = clinc["test"].features["intent"]
intents.int2str(sample["intent"])
'transfer'
现在我们对 CLINC150 数据集的内容有了基本的了解,让我们实现PerformanceBenchmark的compute_accuracy()方法。由于数据集在意图类别上是平衡的,我们将使用准确性作为我们的度量标准。我们可以通过以下方式使用 数据集加载这个度量标准:
数据集加载这个度量标准:
from datasets import load_metric
accuracy_score = load_metric("accuracy")
准确度指标期望预测和参考(即,真实标签)是整数。我们可以使用管道从text字段中提取预测,然后使用我们的intents对象的“str2int()”方法将每个预测映射到其相应的 ID。以下代码在返回数据集的准确度之前收集所有的预测和标签。让我们也将其添加到我们的“PerformanceBenchmark”类中:
def compute_accuracy(self):
"""This overrides the PerformanceBenchmark.compute_accuracy() method"""
preds, labels = [], []
for example in self.dataset:
pred = self.pipeline(example["text"])[0]["label"]
label = example["intent"]
preds.append(intents.str2int(pred))
labels.append(label)
accuracy = accuracy_score.compute(predictions=preds, references=labels)
print(f"Accuracy on test set - {accuracy['accuracy']:.3f}")
return accuracy
PerformanceBenchmark.compute_accuracy = compute_accuracy
接下来,让我们使用 PyTorch 的“torch.save()”函数来计算我们模型的大小,将模型序列化到磁盘上。在内部,“torch.save()”使用 Python 的pickle模块,可以用来保存从模型到张量到普通 Python 对象的任何东西。在 PyTorch 中,保存模型的推荐方式是使用它的state_dict,这是一个 Python 字典,将模型中的每一层映射到它的可学习参数(即,权重和偏置)。让我们看看我们基准模型的state_dict中存储了什么:
list(pipe.model.state_dict().items())[42]
('bert.encoder.layer.2.attention.self.value.weight',
tensor([[-1.0526e-02, -3.2215e-02, 2.2097e-02, ..., -6.0953e-03,
4.6521e-03, 2.9844e-02],
[-1.4964e-02, -1.0915e-02, 5.2396e-04, ..., 3.2047e-05,
-2.6890e-02, -2.1943e-02],
[-2.9640e-02, -3.7842e-03, -1.2582e-02, ..., -1.0917e-02,
3.1152e-02, -9.7786e-03],
...,
[-1.5116e-02, -3.3226e-02, 4.2063e-02, ..., -5.2652e-03,
1.1093e-02, 2.9703e-03],
[-3.6809e-02, 5.6848e-02, -2.6544e-02, ..., -4.0114e-02,
6.7487e-03, 1.0511e-03],
[-2.4961e-02, 1.4747e-03, -5.4271e-02, ..., 2.0004e-02,
2.3981e-02, -4.2880e-02]]))
我们可以清楚地看到每个键/值对对应于 BERT 中的特定层和张量。因此,如果我们用以下方式保存我们的模型:
torch.save(pipe.model.state_dict(), "model.pt")
我们可以使用 Python 的pathlib模块中的“Path.stat()”函数来获取有关底层文件的信息。特别是,“Path(“model.pt”).stat().st_size”将给出模型的大小(以字节为单位)。让我们将所有这些放在“compute_size()”函数中,并将其添加到PerformanceBenchmark中:
import torch
from pathlib import Path
def compute_size(self):
"""This overrides the PerformanceBenchmark.compute_size() method"""
state_dict = self.pipeline.model.state_dict()
tmp_path = Path("model.pt")
torch.save(state_dict, tmp_path)
# Calculate size in megabytes
size_mb = Path(tmp_path).stat().st_size / (1024 * 1024)
# Delete temporary file
tmp_path.unlink()
print(f"Model size (MB) - {size_mb:.2f}")
return {"size_mb": size_mb}
PerformanceBenchmark.compute_size = compute_size
最后,让我们实现“time_pipeline()”函数,以便我们可以计算每个查询的平均延迟时间。对于这个应用程序,延迟时间指的是将文本查询输入到管道中并从模型返回预测意图所需的时间。在内部,管道还会对文本进行标记化,但这比生成预测快了大约一千倍,因此对整体延迟时间的贡献可以忽略不计。衡量代码片段的执行时间的一个简单方法是使用 Python 的time模块中的“perf_counter()”函数。这个函数比“time.time()”函数具有更好的时间分辨率,非常适合获取精确的结果。
我们可以使用“perf_counter()”通过传递我们的测试查询来计时我们的管道,并计算开始和结束之间的毫秒时间差:
from time import perf_counter
for _ in range(3):
start_time = perf_counter()
_ = pipe(query)
latency = perf_counter() - start_time
print(f"Latency (ms) - {1000 * latency:.3f}")
Latency (ms) - 85.367
Latency (ms) - 85.241
Latency (ms) - 87.275
这些结果展示了延迟时间的相当大的差异,并且表明通过管道的单次计时可能每次运行代码时都会得到完全不同的结果。因此,我们将收集多次运行的延迟时间,然后使用得到的分布来计算均值和标准差,这将让我们对数值的差异有一个概念。以下代码实现了我们需要的功能,并包括了在执行实际计时运行之前预热 CPU 的阶段:
import numpy as np
def time_pipeline(self, query="What is the pin number for my account?"):
"""This overrides the PerformanceBenchmark.time_pipeline() method"""
latencies = []
# Warmup
for _ in range(10):
_ = self.pipeline(query)
# Timed run
for _ in range(100):
start_time = perf_counter()
_ = self.pipeline(query)
latency = perf_counter() - start_time
latencies.append(latency)
# Compute run statistics
time_avg_ms = 1000 * np.mean(latencies)
time_std_ms = 1000 * np.std(latencies)
print(f"Average latency (ms) - {time_avg_ms:.2f} +\- {time_std_ms:.2f}")
return {"time_avg_ms": time_avg_ms, "time_std_ms": time_std_ms}
PerformanceBenchmark.time_pipeline = time_pipeline
为了简化问题,我们将使用相同的query值来对我们所有的模型进行基准测试。一般来说,延迟时间将取决于查询长度,一个好的做法是使用模型可能在生产环境中遇到的查询来对模型进行基准测试。
现在我们的PerformanceBenchmark类已经完成,让我们来试一试吧!让我们从对我们的 BERT 基准模型进行基准测试开始。对于基准模型,我们只需要传递管道和我们希望进行基准测试的数据集。我们将在perf_metrics字典中收集结果,以跟踪每个模型的性能:
pb = PerformanceBenchmark(pipe, clinc["test"])
perf_metrics = pb.run_benchmark()
Model size (MB) - 418.16
Average latency (ms) - 54.20 +\- 1.91
Accuracy on test set - 0.867
现在我们有了一个参考点,让我们来看看我们的第一个压缩技术:知识蒸馏。
注意
平均延迟值将取决于您所运行的硬件类型。例如,通常可以通过在 GPU 上运行推断来获得更好的性能,因为它可以实现批处理。对于本章的目的,重要的是模型之间延迟时间的相对差异。一旦确定了性能最佳的模型,我们可以探索不同的后端来减少绝对延迟时间(如果需要)。
通过知识蒸馏使模型变得更小
知识蒸馏是一种通用方法,用于训练一个较小的“学生”模型来模仿速度较慢、更大但性能更好的“教师”模型的行为。最初是在 2006 年在集成模型的背景下引入的,后来在一篇著名的 2015 年论文中将该方法推广到深度神经网络,并将其应用于图像分类和自动语音识别。
鉴于预训练语言模型参数数量不断增加的趋势(撰写时最大的模型参数超过一万亿),知识蒸馏也成为压缩这些庞大模型并使其更适合构建实际应用的流行策略。
微调的知识蒸馏
那么在训练过程中,知识实际上是如何从教师传递给学生的呢?对于微调等监督任务,主要思想是用教师的“软概率”分布来增强地面真实标签,为学生提供补充信息。例如,如果我们的 BERT-base 分类器为多个意图分配高概率,那么这可能表明这些意图在特征空间中相互靠近。通过训练学生模仿这些概率,目标是蒸馏教师学到的一些“暗知识”——也就是,仅从标签中无法获得的知识。
从数学上讲,这是如何工作的。假设我们将输入序列x提供给教师,以生成一个对数向量𝐳 ( x ) = [ z 1 ( x ) , … , z N ( x ) ]。我们可以通过应用 softmax 函数将这些对数转换为概率:
exp(z i (x)) ∑ j exp(z i (x))
然而,这并不是我们想要的,因为在许多情况下,教师会为一个类分配高概率,而其他类的概率接近于零。当发生这种情况时,教师除了地面真实标签外并没有提供太多额外信息,因此我们会在应用 softmax 之前,通过一个温度超参数T来缩放对数,从而“软化”概率。
p i ( x ) = exp(z i (x)/T) ∑ j exp(z i (x)/T)
如图 8-3 所示,T的值越高,类别上的软化概率分布就越软,可以更多地揭示老师对每个训练示例学习的决策边界。当T = 1时,我们恢复了原始的 softmax 分布。

图 8-3。一个使用 one-hot 编码的硬标签(左)、softmax 概率(中)和软化类别概率(右)的比较。
由于学生还产生了自己的软化概率q i ( x ),我们可以使用Kullback-Leibler(KL)散度来衡量两个概率分布之间的差异:
D KL ( p , q ) = ∑ i p i ( x ) log p i (x) q i (x)
通过 KL 散度,我们可以计算当我们用学生来近似老师的概率分布时损失了多少。这使我们能够定义知识蒸馏损失:
L KD = T 2 D KL
其中T 2是一个归一化因子,用于考虑软标签产生的梯度大小按1 / T 2缩放的事实。对于分类任务,学生的损失是蒸馏损失和地面真实标签的交叉熵损失L CE的加权平均:
L student = α L CE + ( 1 - α ) L KD
其中α是一个控制每个损失相对强度的超参数。整个过程的图表如图 8-4 所示;在推断时,温度被设置为 1,以恢复标准的 softmax 概率。

图 8-4。知识蒸馏过程
预训练的知识蒸馏
知识蒸馏也可以在预训练期间使用,以创建一个通用的学生模型,随后可以在下游任务上进行精细调整。在这种情况下,教师是一个预训练的语言模型,如 BERT,它将其关于掩码语言建模的知识转移到学生身上。例如,在 DistilBERT 论文中,⁸掩码语言建模损失L mlm被知识蒸馏的一个项和余弦嵌入损失L cos = 1 - cos ( h s , h t )来对齐教师和学生之间的隐藏状态向量的方向:
L DistilBERT = α L mlm + β L KD + γ L cos
由于我们已经有了一个经过精细调整的 BERT-base 模型,让我们看看如何使用知识蒸馏来对一个更小更快的模型进行精细调整。为了做到这一点,我们需要一种方法来将交叉熵损失与L KD项相结合。幸运的是,我们可以通过创建自己的训练器来实现这一点!
创建知识蒸馏训练器
要实现知识蒸馏,我们需要向Trainer基类添加一些内容:
-
新的超参数α和T,它们控制蒸馏损失的相对权重以及标签的概率分布应该被平滑的程度
-
经过精细调整的教师模型,我们的情况下是 BERT-base
-
结合交叉熵损失和知识蒸馏损失的新损失函数
添加新的超参数非常简单,因为我们只需要对TrainingArguments进行子类化,并将它们包含为新的属性:
from transformers import TrainingArguments
class DistillationTrainingArguments(TrainingArguments):
def __init__(self, *args, alpha=0.5, temperature=2.0, **kwargs):
super().__init__(*args, **kwargs)
self.alpha = alpha
self.temperature = temperature
对于训练器本身,我们需要一个新的损失函数。实现这一点的方法是通过对Trainer进行子类化,并覆盖compute_loss()方法,以包括知识蒸馏损失项L KD:
import torch.nn as nn
import torch.nn.functional as F
from transformers import Trainer
class DistillationTrainer(Trainer):
def __init__(self, *args, teacher_model=None, **kwargs):
super().__init__(*args, **kwargs)
self.teacher_model = teacher_model
def compute_loss(self, model, inputs, return_outputs=False):
outputs_stu = model(**inputs)
# Extract cross-entropy loss and logits from student
loss_ce = outputs_stu.loss
logits_stu = outputs_stu.logits
# Extract logits from teacher
with torch.no_grad():
outputs_tea = self.teacher_model(**inputs)
logits_tea = outputs_tea.logits
# Soften probabilities and compute distillation loss
loss_fct = nn.KLDivLoss(reduction="batchmean")
loss_kd = self.args.temperature ** 2 * loss_fct(
F.log_softmax(logits_stu / self.args.temperature, dim=-1),
F.softmax(logits_tea / self.args.temperature, dim=-1))
# Return weighted student loss
loss = self.args.alpha * loss_ce + (1. - self.args.alpha) * loss_kd
return (loss, outputs_stu) if return_outputs else loss
让我们解开一下这段代码。当我们实例化DistillationTrainer时,我们传递了一个已经在我们的任务上进行了微调的老师模型。接下来,在compute_loss()方法中,我们从学生和老师那里提取 logits,通过温度对它们进行缩放,然后在传递给 PyTorch 的nn.KLDivLoss()函数之前,使用 softmax 对它们进行归一化以计算 KL 散度。nn.KLDivLoss()的一个怪癖是,它期望输入以对数概率的形式,标签以正常概率的形式。这就是为什么我们使用F.log_softmax()函数对学生的 logits 进行归一化,而老师的 logits 则使用标准 softmax 转换为概率。nn.KLDivLoss()中的reduction=batchmean参数指定我们在批维度上平均损失。
提示
您还可以使用 Transformers 库的 Keras API 进行知识蒸馏。为此,您需要实现一个自定义的
Transformers 库的 Keras API 进行知识蒸馏。为此,您需要实现一个自定义的Distiller类,覆盖tf.keras.Model()的train_step()、test_step()和compile()方法。请参阅Keras 文档了解如何实现。
选择一个好的学生初始化
现在我们有了自定义的训练器,您可能会问的第一个问题是,我们应该为学生选择哪个预训练语言模型?一般来说,我们应该为学生选择一个较小的模型,以减少延迟和内存占用。从文献中得出的一个很好的经验法则是,当老师和学生是相同的模型类型时,知识蒸馏效果最好。⁹这样做的一个可能原因是,不同的模型类型,比如 BERT 和 RoBERTa,可能具有不同的输出嵌入空间,这会妨碍学生模仿老师的能力。在我们的案例研究中,老师是 BERT,因此 DistilBERT 是一个自然的候选,因为它的参数少了 40%,并且已经在下游任务中取得了良好的结果。
首先,我们需要对我们的查询进行标记化和编码,因此让我们实例化来自 DistilBERT 的标记器,并创建一个简单的tokenize_text()函数来处理预处理:
from transformers import AutoTokenizer
student_ckpt = "distilbert-base-uncased"
student_tokenizer = AutoTokenizer.from_pretrained(student_ckpt)
def tokenize_text(batch):
return student_tokenizer(batch["text"], truncation=True)
clinc_enc = clinc.map(tokenize_text, batched=True, remove_columns=["text"])
clinc_enc = clinc_enc.rename_column("intent", "labels")
在这里,我们已经删除了text列,因为我们不再需要它,我们还将intent列重命名为labels,以便训练器可以自动检测到它。¹⁰
现在我们已经处理了我们的文本,接下来我们需要做的是为我们的DistillationTrainer定义超参数和compute_metrics()函数。我们还将把所有的模型推送到 Hugging Face Hub,所以让我们首先登录到我们的账户:
from huggingface_hub import notebook_login
notebook_login()
接下来,我们将定义训练过程中要跟踪的指标。就像我们在性能基准测试中所做的那样,我们将使用准确性作为主要指标。这意味着我们可以在compute_metrics()函数中重用我们的accuracy_score()函数,这个函数将包含在DistillationTrainer中:
def compute_metrics(pred):
predictions, labels = pred
predictions = np.argmax(predictions, axis=1)
return accuracy_score.compute(predictions=predictions, references=labels)
在这个函数中,序列建模头部的预测以 logits 的形式出现,因此我们使用np.argmax()函数找到最有信心的类别预测,并将其与地面真相标签进行比较。
接下来我们需要定义训练参数。为了热身,我们将设置α = 1,以查看 DistilBERT 在没有来自教师的任何信号的情况下的表现。¹¹然后我们将我们的微调模型推送到一个名为distilbert-base-uncased-finetuned-clinc的新存储库,所以我们只需要在DistillationTrainingArguments的output_dir参数中指定它:
batch_size = 48
finetuned_ckpt = "distilbert-base-uncased-finetuned-clinc"
student_training_args = DistillationTrainingArguments(
output_dir=finetuned_ckpt, evaluation_strategy = "epoch",
num_train_epochs=5, learning_rate=2e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size, alpha=1, weight_decay=0.01,
push_to_hub=True)
我们还调整了一些默认超参数值,比如 epochs 的数量,权重衰减和学习率。接下来要做的是初始化一个学生模型。由于我们将使用训练器进行多次运行,我们将创建一个student_init()函数,以便在每次调用train()方法时初始化一个新模型。当我们将这个函数传递给DistillationTrainer时,这将确保我们每次调用train()方法时初始化一个新模型。
我们还需要做的另一件事是为学生模型提供每个意图和标签 ID 之间的映射。这些映射可以从我们在流水线中下载的 BERT-base 模型中获得:
id2label = pipe.model.config.id2label
label2id = pipe.model.config.label2id
有了这些映射,我们现在可以使用AutoConfig类创建一个自定义模型配置,这是我们在第三章和第四章中遇到的。让我们使用这个为我们的学生创建一个包含标签映射信息的配置:
from transformers import AutoConfig
num_labels = intents.num_classes
student_config = (AutoConfig
.from_pretrained(student_ckpt, num_labels=num_labels,
id2label=id2label, label2id=label2id))
在这里,我们还指定了我们的模型应该期望的类的数量。然后我们可以将这个配置提供给AutoModelForSequenceClassification类的from_pretrained()函数,如下所示:
import torch
from transformers import AutoModelForSequenceClassification
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def student_init():
return (AutoModelForSequenceClassification
.from_pretrained(student_ckpt, config=student_config).to(device))
现在我们已经拥有了我们的蒸馏训练器所需的所有要素,让我们加载教师并进行微调:
teacher_ckpt = "transformersbook/bert-base-uncased-finetuned-clinc"
teacher_model = (AutoModelForSequenceClassification
.from_pretrained(teacher_ckpt, num_labels=num_labels)
.to(device))
distilbert_trainer = DistillationTrainer(model_init=student_init,
teacher_model=teacher_model, args=student_training_args,
train_dataset=clinc_enc['train'], eval_dataset=clinc_enc['validation'],
compute_metrics=compute_metrics, tokenizer=student_tokenizer)
distilbert_trainer.train()
| Epoch | Training Loss | Validation Loss | Accuracy |
|---|---|---|---|
| — | — | — | — |
| 1 | 4.2923 | 3.289337 | 0.742258 |
| 2 | 2.6307 | 1.883680 | 0.828065 |
| 3 | 1.5483 | 1.158315 | 0.896774 |
| 4 | 1.0153 | 0.861815 | 0.909355 |
| 5 | 0.7958 | 0.777289 | 0.917419 |
验证集上的 92%准确率看起来相当不错,与 BERT-base 教师实现的 94%相比。现在我们已经对 DistilBERT 进行了微调,让我们将模型推送到 Hub,以便以后重用:
distilbert_trainer.push_to_hub("Training completed!")
现在我们的模型已经安全地存储在 Hub 上,我们可以立即在性能基准测试的流水线中使用它:
finetuned_ckpt = "transformersbook/distilbert-base-uncased-finetuned-clinc"
pipe = pipeline("text-classification", model=finetuned_ckpt)
然后我们可以将这个流水线传递给我们的PerformanceBenchmark类,以计算与这个模型相关的指标:
optim_type = "DistilBERT"
pb = PerformanceBenchmark(pipe, clinc["test"], optim_type=optim_type)
perf_metrics.update(pb.run_benchmark())
Model size (MB) - 255.89
Average latency (ms) - 27.53 +\- 0.60
Accuracy on test set - 0.858
为了将这些结果与我们的基准进行比较,让我们创建一个散点图,显示准确性与延迟之间的关系,每个点的半径对应于磁盘上模型的大小。以下函数可以满足我们的需求,并将当前优化类型标记为虚线圆圈,以便与以前的结果进行比较:
import pandas as pd
def plot_metrics(perf_metrics, current_optim_type):
df = pd.DataFrame.from_dict(perf_metrics, orient='index')
for idx in df.index:
df_opt = df.loc[idx]
# Add a dashed circle around the current optimization type
if idx == current_optim_type:
plt.scatter(df_opt["time_avg_ms"], df_opt["accuracy"] * 100,
alpha=0.5, s=df_opt["size_mb"], label=idx,
marker='$\u25CC$')
else:
plt.scatter(df_opt["time_avg_ms"], df_opt["accuracy"] * 100,
s=df_opt["size_mb"], label=idx, alpha=0.5)
legend = plt.legend(bbox_to_anchor=(1,1))
for handle in legend.legendHandles:
handle.set_sizes([20])
plt.ylim(80,90)
# Use the slowest model to define the x-axis range
xlim = int(perf_metrics["BERT baseline"]["time_avg_ms"] + 3)
plt.xlim(1, xlim)
plt.ylabel("Accuracy (%)")
plt.xlabel("Average latency (ms)")
plt.show()
plot_metrics(perf_metrics, optim_type)

从图中我们可以看到,通过使用一个更小的模型,我们成功地显著降低了平均延迟。而这一切只需牺牲了略微超过 1%的准确性!让我们看看是否可以通过包括教师的蒸馏损失并找到α和T的良好值来缩小最后的差距。
使用 Optuna 找到良好的超参数
为了找到α和T的良好值,我们可以在 2D 参数空间上进行网格搜索。但一个更好的选择是使用Optuna,¹²这是一个专为这种任务设计的优化框架。Optuna 通过多次trials优化目标函数来制定搜索问题。例如,假设我们希望最小化 Rosenbrock 的“香蕉函数”:
f ( x , y ) = (1-x) 2 + 100 (y-x 2 ) 2
这是一个著名的优化框架的测试案例。如图 8-5 所示,该函数因其曲线轮廓而得名,并且在( x , y ) = ( 1 , 1 )处有一个全局最小值。找到这个谷是一个简单的优化问题,但收敛到全局最小值却不是。

图 8-5。两个变量的 Rosenbrock 函数的绘图
在 Optuna 中,我们可以通过定义一个objective()函数来找到f ( x , y )的最小值,该函数返回f ( x , y )的值:
def objective(trial):
x = trial.suggest_float("x", -2, 2)
y = trial.suggest_float("y", -2, 2)
return (1 - x) ** 2 + 100 * (y - x ** 2) ** 2
trial.suggest_float对象指定要均匀采样的参数范围;Optuna 还提供suggest_int和suggest_categorical用于整数和分类参数。Optuna 将多个试验收集为一个study,因此我们只需将objective()函数传递给study.optimize()来创建一个如下:
import optuna
study = optuna.create_study()
study.optimize(objective, n_trials=1000)
一旦研究完成,我们就可以按照以下方式找到最佳参数:
study.best_params
{'x': 1.003024865971437, 'y': 1.00315167589307}
通过一千次试验,Optuna 已经成功找到了* x 和 y 的值,这些值与全局最小值相当接近。要在 Transformers 中使用 Optuna,我们首先定义要优化的超参数空间。除了 α 和T*之外,我们还将包括训练周期的数量如下:
Transformers 中使用 Optuna,我们首先定义要优化的超参数空间。除了 α 和T*之外,我们还将包括训练周期的数量如下:
def hp_space(trial):
return {"num_train_epochs": trial.suggest_int("num_train_epochs", 5, 10),
"alpha": trial.suggest_float("alpha", 0, 1),
"temperature": trial.suggest_int("temperature", 2, 20)}
使用Trainer进行超参数搜索非常简单;我们只需要指定要运行的试验次数和要优化的方向。因为我们希望获得最佳准确度,所以在训练器的hyperparameter_search()方法中指定direction="maximize",并按如下方式传递超参数搜索空间:
best_run = distilbert_trainer.hyperparameter_search(
n_trials=20, direction="maximize", hp_space=hp_space)
hyperparameter_search()方法返回一个BestRun对象,其中包含了被最大化的目标值(默认为所有指标的总和)和该运行所使用的超参数:
print(best_run)
BestRun(run_id='1', objective=0.927741935483871,
hyperparameters={'num_train_epochs': 10, 'alpha': 0.12468168730193585,
'temperature': 7})
这个α的值告诉我们,大部分的训练信号来自知识蒸馏项。让我们使用这些值更新我们的训练参数,并运行最终的训练:
for k,v in best_run.hyperparameters.items():
setattr(student_training_args, k, v)
# Define a new repository to store our distilled model
distilled_ckpt = "distilbert-base-uncased-distilled-clinc"
student_training_args.output_dir = distilled_ckpt
# Create a new Trainer with optimal parameters
distil_trainer = DistillationTrainer(model_init=student_init,
teacher_model=teacher_model, args=student_training_args,
train_dataset=clinc_enc['train'], eval_dataset=clinc_enc['validation'],
compute_metrics=compute_metrics, tokenizer=student_tokenizer)
distil_trainer.train();
| Epoch | Training Loss | Validation Loss | Accuracy |
|---|---|---|---|
| — | — | — | — |
| 1 | 0.9031 | 0.574540 | 0.736452 |
| 2 | 0.4481 | 0.285621 | 0.874839 |
| 3 | 0.2528 | 0.179766 | 0.918710 |
| 4 | 0.1760 | 0.139828 | 0.929355 |
| 5 | 0.1416 | 0.121053 | 0.934839 |
| 6 | 0.1243 | 0.111640 | 0.934839 |
| 7 | 0.1133 | 0.106174 | 0.937742 |
| 8 | 0.1075 | 0.103526 | 0.938710 |
| 9 | 0.1039 | 0.101432 | 0.938065 |
| 10 | 0.1018 | 0.100493 | 0.939355 |
值得注意的是,尽管参数数量几乎减少了一半,我们已经成功训练出学生模型与教师模型的准确度相匹配!让我们将模型推送到 Hub 以供将来使用:
distil_trainer.push_to_hub("Training complete")
基准测试我们的精炼模型
现在我们有了一个准确的学生,让我们创建一个流水线,并重新进行我们的基准测试,看看我们在测试集上的表现如何:
distilled_ckpt = "transformersbook/distilbert-base-uncased-distilled-clinc"
pipe = pipeline("text-classification", model=distilled_ckpt)
optim_type = "Distillation"
pb = PerformanceBenchmark(pipe, clinc["test"], optim_type=optim_type)
perf_metrics.update(pb.run_benchmark())
Model size (MB) - 255.89
Average latency (ms) - 25.96 +\- 1.63
Accuracy on test set - 0.868
为了将这些结果放在上下文中,让我们还用我们的plot_metrics()函数将它们可视化:
plot_metrics(perf_metrics, optim_type)

正如预期的那样,与 DistilBERT 基准相比,模型大小和延迟基本保持不变,但准确性得到了改善,甚至超过了教师的表现!解释这一令人惊讶的结果的一种方式是,教师很可能没有像学生那样系统地进行精细调整。这很好,但我们实际上可以使用一种称为量化的技术进一步压缩我们的精炼模型。这是下一节的主题。
使用量化使模型更快
我们现在已经看到,通过知识蒸馏,我们可以通过将信息从教师传递到更小的学生来减少运行推断的计算和内存成本。量化采用了不同的方法;它不是减少计算的数量,而是通过使用低精度数据类型(如 8 位整数(INT8))代替通常的 32 位浮点数(FP32)来使它们更加高效。减少位数意味着结果模型需要更少的内存存储,并且像矩阵乘法这样的操作可以通过整数运算更快地执行。值得注意的是,这些性能增益可以在几乎没有准确性损失的情况下实现!
量化背后的基本思想是,我们可以通过将张量中的浮点值f的范围[ f max , f min ]映射到一个较小的范围[ q max , q min ]中的固定点数q,并线性分布所有值。从数学上讲,这种映射由以下方程描述:
f = f max -f min q max -q min ( q - Z ) = S ( q - Z )
缩放因子S是一个正的浮点数,常数Z与q具有相同的类型,被称为零点,因为它对应于浮点值f = 0的量化值。请注意,映射需要是仿射的,这样当我们将定点数反量化为浮点数时,我们会得到浮点数。¹³ 转换的示例显示在图 8-6 中。

图 8-6。将浮点数量化为无符号 8 位整数(由 Manas Sahni 提供)
现在,Transformer(以及深度神经网络更普遍地)成为量化的主要候选对象的一个主要原因是权重和激活倾向于在相对较小的范围内取值。这意味着我们不必将所有可能的 FP32 数字范围压缩到 INT8 表示的 256 个数字中。为了看到这一点,让我们从我们精简模型中挑选出一个注意力权重矩阵,并绘制值的频率分布:
import matplotlib.pyplot as plt
state_dict = pipe.model.state_dict()
weights = state_dict["distilbert.transformer.layer.0.attention.out_lin.weight"]
plt.hist(weights.flatten().numpy(), bins=250, range=(-0.3,0.3), edgecolor="C0")
plt.show()

我们可以看到,权重的值分布在接近零的小范围内[-0.1,0.1]。现在,假设我们想要将这个张量量化为带符号的 8 位整数。在这种情况下,我们整数的可能值范围是[qmax,qmin] = [-128,127]。零点与 FP32 的零点重合,比例因子根据前面的方程计算:
zero_point = 0
scale = (weights.max() - weights.min()) / (127 - (-128))
为了获得量化张量,我们只需要反转映射q=f/S+Z,将值夹紧,四舍五入到最近的整数,并使用Tensor.char()函数将结果表示为torch.int8数据类型:
(weights / scale + zero_point).clamp(-128, 127).round().char()
tensor([[ -5, -8, 0, ..., -6, -4, 8],
[ 8, 3, 1, ..., -4, 7, 0],
[ -9, -6, 5, ..., 1, 5, -3],
...,
[ 6, 0, 12, ..., 0, 6, -1],
[ 0, -2, -12, ..., 12, -7, -13],
[-13, -1, -10, ..., 8, 2, -2]], dtype=torch.int8)
太好了,我们刚刚量化了我们的第一个张量!在 PyTorch 中,我们可以使用quantize_per_tensor()函数和量化数据类型torch.qint来简化转换,该数据类型针对整数算术操作进行了优化:
from torch import quantize_per_tensor
dtype = torch.qint8
quantized_weights = quantize_per_tensor(weights, scale, zero_point, dtype)
quantized_weights.int_repr()
tensor([[ -5, -8, 0, ..., -6, -4, 8],
[ 8, 3, 1, ..., -4, 7, 0],
[ -9, -6, 5, ..., 1, 5, -3],
...,
[ 6, 0, 12, ..., 0, 6, -1],
[ 0, -2, -12, ..., 12, -7, -13],
[-13, -1, -10, ..., 8, 2, -2]], dtype=torch.int8)
图 8-7 中的图表清楚地显示了只映射一些权重值并对其余值进行四舍五入所引起的离散化。

图 8-7。量化对 Transformer 权重的影响
为了完成我们的小分析,让我们比较使用 FP32 和 INT8 值计算两个权重张量的乘法需要多长时间。对于 FP32 张量,我们可以使用 PyTorch 的@运算符进行相乘:
%%timeit
weights @ weights
393 µs ± 3.84 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
对于量化张量,我们需要QFunctional包装类,以便我们可以使用特殊的torch.qint8数据类型执行操作:
from torch.nn.quantized import QFunctional
q_fn = QFunctional()
这个类支持各种基本操作,比如加法,在我们的情况下,我们可以通过以下方式计算量化张量的乘法时间:
%%timeit
q_fn.mul(quantized_weights, quantized_weights)
23.3 µs ± 298 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
与我们的 FP32 计算相比,使用 INT8 张量几乎快 100 倍!通过使用专门的后端运行量化运算符,还可以获得更大的收益。截至本书编写时,PyTorch 支持:
-
具有 AVX2 支持或更高版本的 x86 CPU
-
ARM CPU(通常用于移动/嵌入式设备)
由于 INT8 数字的位数比 FP32 数字少四倍,量化还将内存存储需求减少了多达四倍。在我们的简单示例中,我们可以通过使用Tensor.storage()函数和 Python 的sys模块中的getsizeof()函数来比较权重张量及其量化版本的底层存储大小来验证这一点:
import sys
sys.getsizeof(weights.storage()) / sys.getsizeof(quantized_weights.storage())
3.999633833760527
对于一个大规模的 Transformer,实际的压缩率取决于哪些层被量化(正如我们将在下一节看到的,通常只有线性层被量化)。
那么量化有什么问题?改变模型中所有计算的精度会在模型的计算图中的每个点引入小的扰动,这可能会影响模型的性能。量化模型有几种方法,各有利弊。对于深度神经网络,通常有三种主要的量化方法:
动态量化
使用动态量化时,在训练期间不会发生任何变化,调整只会在推断期间进行。与我们将讨论的所有量化方法一样,模型的权重在推断时间之前被转换为 INT8。除了权重,模型的激活也被量化。这种方法是动态的,因为量化是即时发生的。这意味着所有矩阵乘法都可以使用高度优化的 INT8 函数进行计算。在这里讨论的所有量化方法中,动态量化是最简单的方法。然而,使用动态量化时,激活以浮点格式写入和读取到内存中。整数和浮点之间的转换可能成为性能瓶颈。
静态量化
我们可以避免在推断期间将激活量化为浮点数,而是预先计算量化方案。静态量化通过观察数据的代表性样本上的激活模式来实现这一点。理想的量化方案被计算然后保存。这使我们能够跳过 INT8 和 FP32 值之间的转换,并加快计算速度。然而,这需要访问一个良好的数据样本,并且在管道中引入了一个额外的步骤,因为现在我们需要在执行推断之前训练和确定量化方案。静态量化没有解决的一个方面是:训练和推断期间精度之间的差异,这导致模型指标(例如准确性)下降。
量化感知训练
通过“伪”量化 FP32 值来有效模拟训练期间的量化效果。在训练期间,不使用 INT8 值,而是将 FP32 值四舍五入以模拟量化效果。这在前向和后向传递过程中都会进行,可以改善模型指标的性能,超过静态和动态量化。
使用 transformers 进行推断的主要瓶颈是与这些模型中庞大数量的权重相关的计算和内存带宽。因此,动态量化目前是自然语言处理中基于 transformer 的模型的最佳方法。在较小的计算机视觉模型中,限制因素是激活的内存带宽,这就是为什么通常使用静态量化(或者在性能下降太显著的情况下使用量化感知训练)的原因。
在 PyTorch 中实现动态量化非常简单,可以用一行代码完成:
from torch.quantization import quantize_dynamic
model_ckpt = "transformersbook/distilbert-base-uncased-distilled-clinc"
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
model = (AutoModelForSequenceClassification
.from_pretrained(model_ckpt).to("cpu"))
model_quantized = quantize_dynamic(model, {nn.Linear}, dtype=torch.qint8)
在这里,我们将完整精度模型传递给quantize_dynamic(),并指定我们要量化的 PyTorch 层类的集合。dtype参数指定目标精度,可以是fp16或qint8。一个好的做法是选择您的评估指标所能容忍的最低精度。在本章中,我们将使用 INT8,很快就会看到它对我们模型的准确性几乎没有影响。
对我们的量化模型进行基准测试
我们的模型现在已经量化,让我们通过基准测试并可视化结果:
pipe = pipeline("text-classification", model=model_quantized,
tokenizer=tokenizer)
optim_type = "Distillation + quantization"
pb = PerformanceBenchmark(pipe, clinc["test"], optim_type=optim_type)
perf_metrics.update(pb.run_benchmark())
Model size (MB) - 132.40
Average latency (ms) - 12.54 +\- 0.73
Accuracy on test set - 0.876
plot_metrics(perf_metrics, optim_type)

不错,量化模型几乎是我们精简模型大小的一半,甚至还略微提高了准确性!让我们看看是否可以通过一个强大的框架 ONNX Runtime 将我们的优化推向极限。
使用 ONNX 和 ONNX Runtime 优化推断
ONNX是一个开放标准,定义了一组通用的操作符和一种通用的文件格式,用于在各种框架中表示深度学习模型,包括 PyTorch 和 TensorFlow。¹⁴当模型导出为 ONNX 格式时,这些操作符用于构建一个计算图(通常称为中间表示),表示数据通过神经网络的流动。例如,BERT-base 的这样一个图示例显示在图 8-8 中,其中每个节点接收一些输入,应用操作如Add或Squeeze,然后将输出馈送到下一组节点。

图 8-8. BERT-base 的 ONNX 图的一个部分,在 Netron 中可视化
通过公开具有标准化操作符和数据类型的图,ONNX 使得在不同框架之间切换变得容易。例如,在 PyTorch 中训练的模型可以导出为 ONNX 格式,然后在 TensorFlow 中导入(反之亦然)。
当 ONNX 与专用加速器如ONNX Runtime或 ORT 配合使用时,它的优势就显现出来了。¹⁵ORT 通过操作符融合和常量折叠等技术提供了优化 ONNX 图的工具,¹⁶并定义了一个接口,允许您在不同类型的硬件上运行模型。这是一个强大的抽象。图 8-9 显示了 ONNX 和 ORT 生态系统的高级架构。

图 8-9. ONNX 和 ONNX Runtime 生态系统的架构(由 ONNX Runtime 团队提供)
要看到 ORT 的运行情况,我们需要做的第一件事是将我们的精炼模型转换为 ONNX 格式。 Transformers 库有一个内置函数叫做
Transformers 库有一个内置函数叫做convert_graph_to_onnx.convert(),它简化了这个过程,采取以下步骤:
-
将模型初始化为
Pipeline。 -
通过管道运行占位符输入,以便 ONNX 可以记录计算图。
-
定义动态轴以处理动态序列长度。
-
保存具有网络参数的图。
要使用这个函数,我们首先需要为 ONNX 设置一些OpenMP环境变量:
import os
from psutil import cpu_count
os.environ["OMP_NUM_THREADS"] = f"{cpu_count()}"
os.environ["OMP_WAIT_POLICY"] = "ACTIVE"
OpenMP 是一个为开发高度并行化应用程序而设计的 API。OMP_NUM_THREADS环境变量设置并行计算中使用的线程数,在 ONNX Runtime 中,OMP_WAIT_POLICY=ACTIVE指定等待线程应处于活动状态(即使用 CPU 处理器周期)。
接下来,让我们将我们的精炼模型转换为 ONNX 格式。在这里,我们需要指定参数pipeline_name="text-classification",因为convert()在转换过程中将模型包装在一个 Transformers
Transformers pipeline()函数中。除了model_ckpt之外,我们还传递了 tokenizer 来初始化管道:
from transformers.convert_graph_to_onnx import convert
model_ckpt = "transformersbook/distilbert-base-uncased-distilled-clinc"
onnx_model_path = Path("onnx/model.onnx")
convert(framework="pt", model=model_ckpt, tokenizer=tokenizer,
output=onnx_model_path, opset=12, pipeline_name="text-classification")
ONNX 使用操作符集来将不可变的操作符规范分组在一起,因此opset=12对应于 ONNX 库的特定版本。
现在我们已经保存了我们的模型,我们需要创建一个InferenceSession实例来向模型输入数据:
from onnxruntime import (GraphOptimizationLevel, InferenceSession,
SessionOptions)
def create_model_for_provider(model_path, provider="CPUExecutionProvider"):
options = SessionOptions()
options.intra_op_num_threads = 1
options.graph_optimization_level = GraphOptimizationLevel.ORT_ENABLE_ALL
session = InferenceSession(str(model_path), options, providers=[provider])
session.disable_fallback()
return session
onnx_model = create_model_for_provider(onnx_model_path)
现在当我们调用onnx_model.run()时,我们可以从 ONNX 模型中获取类别对数。让我们用测试集中的一个例子来测试一下。由于convert()的输出告诉我们 ONNX 只期望input_ids和attention_mask作为输入,我们需要从我们的样本中删除label列:
inputs = clinc_enc["test"][:1]
del inputs["labels"]
logits_onnx = onnx_model.run(None, inputs)[0]
logits_onnx.shape
(1, 151)
一旦我们有了对数,我们可以通过取 argmax 轻松获得预测的标签:
np.argmax(logits_onnx)
61
这确实与地面真实标签一致:
clinc_enc["test"][0]["labels"]
61
ONNX 模型与text-classification管道不兼容,因此我们将创建一个模仿核心行为的自定义类:
from scipy.special import softmax
class OnnxPipeline:
def __init__(self, model, tokenizer):
self.model = model
self.tokenizer = tokenizer
def __call__(self, query):
model_inputs = self.tokenizer(query, return_tensors="pt")
inputs_onnx = {k: v.cpu().detach().numpy()
for k, v in model_inputs.items()}
logits = self.model.run(None, inputs_onnx)[0][0, :]
probs = softmax(logits)
pred_idx = np.argmax(probs).item()
return [{"label": intents.int2str(pred_idx), "score": probs[pred_idx]}]
然后我们可以测试这个简单的查询,看看我们是否恢复了car_rental意图:
pipe = OnnxPipeline(onnx_model, tokenizer)
pipe(query)
[{'label': 'car_rental', 'score': 0.7848334}]
很好,我们的流水线按预期工作。下一步是为 ONNX 模型创建性能基准测试。在这里,我们可以借鉴我们与PerformanceBenchmark类一起完成的工作,只需重写compute_size()方法,保留compute_accuracy()和time_pipeline()方法。我们需要重写compute_size()方法的原因是,我们不能依赖state_dict和torch.save()来测量模型的大小,因为onnx_model在技术上是一个 ONNXInferenceSession对象,无法访问 PyTorch 的nn.Module的属性。无论如何,结果逻辑很简单,可以实现如下:
class OnnxPerformanceBenchmark(PerformanceBenchmark):
def __init__(self, *args, model_path, **kwargs):
super().__init__(*args, **kwargs)
self.model_path = model_path
def compute_size(self):
size_mb = Path(self.model_path).stat().st_size / (1024 * 1024)
print(f"Model size (MB) - {size_mb:.2f}")
return {"size_mb": size_mb}
通过我们的新基准测试,让我们看看我们的蒸馏模型转换为 ONNX 格式后的性能:
optim_type = "Distillation + ORT"
pb = OnnxPerformanceBenchmark(pipe, clinc["test"], optim_type,
model_path="onnx/model.onnx")
perf_metrics.update(pb.run_benchmark())
Model size (MB) - 255.88
Average latency (ms) - 21.02 +\- 0.55
Accuracy on test set - 0.868
plot_metrics(perf_metrics, optim_type)

值得注意的是,转换为 ONNX 格式并使用 ONNX Runtime 为我们的蒸馏模型(即图中的“蒸馏”圈)提供了延迟增益!让我们看看是否可以通过添加量化来挤出更多性能。
与 PyTorch 类似,ORT 提供了三种模型量化的方式:动态量化、静态量化和量化感知训练。与 PyTorch 一样,我们将对我们的蒸馏模型应用动态量化。在 ORT 中,量化是通过quantize_dynamic()函数应用的,该函数需要一个 ONNX 模型的路径进行量化,一个目标路径来保存量化后的模型,以及要将权重减少到的数据类型:
from onnxruntime.quantization import quantize_dynamic, QuantType
model_input = "onnx/model.onnx"
model_output = "onnx/model.quant.onnx"
quantize_dynamic(model_input, model_output, weight_type=QuantType.QInt8)
现在模型已经被量化,让我们通过我们的基准测试运行它:
onnx_quantized_model = create_model_for_provider(model_output)
pipe = OnnxPipeline(onnx_quantized_model, tokenizer)
optim_type = "Distillation + ORT (quantized)"
pb = OnnxPerformanceBenchmark(pipe, clinc["test"], optim_type,
model_path=model_output)
perf_metrics.update(pb.run_benchmark())
Model size (MB) - 64.20
Average latency (ms) - 9.24 +\- 0.29
Accuracy on test set - 0.877
plot_metrics(perf_metrics, optim_type)

与 PyTorch 量化获得的模型相比,ORT 量化已经将模型大小和延迟减少了约 30%(蒸馏+量化 blob)。其中一个原因是 PyTorch 只优化nn.Linear模块,而 ONNX 还量化了嵌入层。从图中我们还可以看到,将 ORT 量化应用于我们的蒸馏模型与我们的 BERT 基线相比,提供了近三倍的增益!
这结束了我们对加速 Transformer 进行推断的技术的分析。我们已经看到,诸如量化之类的方法通过降低表示的精度来减小模型大小。另一种减小大小的策略是彻底删除一些权重。这种技术称为权重修剪,并且是下一节的重点。
使用权重修剪使模型更稀疏
到目前为止,我们已经看到知识蒸馏和权重量化在产生更快的推断模型方面非常有效,但在某些情况下,您可能还对模型的内存占用有很强的约束。例如,如果我们的产品经理突然决定我们的文本助手需要部署在移动设备上,那么我们需要我们的意图分类器尽可能少地占用存储空间。为了完成我们对压缩方法的调查,让我们看看如何通过识别和删除网络中最不重要的权重来减少模型参数的数量。
深度神经网络中的稀疏性
如图 8-10 所示,修剪的主要思想是在训练过程中逐渐移除权重连接(可能还有神经元),使模型逐渐变得更稀疏。结果修剪后的模型具有更少的非零参数,然后可以以紧凑的稀疏矩阵格式存储。修剪也可以与量化结合以获得进一步的压缩。

图 8-10。修剪前后的权重和神经元(由 Song Han 提供)
权重修剪方法
在数学上,大多数权重修剪方法的工作方式是计算一个重要性分数矩阵𝐒,然后按重要性选择前k百分比的权重:
Top k (𝐒) ij = 1 if S ij in top k % 0 otherwise
实际上,k 作为一个新的超参数,用来控制模型中稀疏性的程度,即权重为零值的比例。较低的 k 值对应着更稀疏的矩阵。从这些分数中,我们可以定义一个掩码矩阵 𝐌,在前向传播过程中,用一些输入 x i 掩盖权重 W ij,从而有效地创建一个稀疏的激活网络 a i:
a i = ∑ k W ik M ik x k
正如“最佳脑外科医生”论文中所讨论的那样,每种剪枝方法的核心都是一组需要考虑的问题:
-
哪些权重应该被消除?
-
剩余的权重应该如何调整以获得最佳性能?
-
如何以计算有效的方式进行网络剪枝?
这些问题的答案告诉了我们如何计算得分矩阵 𝐒,因此让我们首先看一下最早和最流行的剪枝方法之一:幅度剪枝。
幅度剪枝
顾名思义,幅度剪枝根据权重的幅度计算得分 𝐒 = ∣ W ij ∣ 1≤j,j≤n,然后从 𝐌 = Top k ( 𝐒 ) 中得出掩码。在文献中,通常通过迭代的方式应用幅度剪枝,首先训练模型学习哪些连接是重要的,然后剪枝最不重要的权重。稀疏模型然后被重新训练,并且重复这个过程,直到达到期望的稀疏度。
这种方法的一个缺点是计算需求量大:在每一步修剪中,我们都需要将模型训练到收敛。因此,通常最好逐渐增加初始稀疏度s i(通常为零)到一定步数N后的最终值s f。¹⁹
s t = s f + ( s i - s f ) 1 - t-t 0 NΔt 3 for t ∈ { t 0 , t 0 + Δ t , … , t 0 + N Δ t }
这里的想法是每隔Δ t步更新一次二进制掩码𝐌,以允许被屏蔽的权重在训练过程中重新激活,并从修剪过程中可能导致的任何精度损失中恢复过来。如图 8-11 所示,立方因子意味着权重修剪的速率在早期阶段最高(当冗余权重数量较大时),并逐渐减小。

图 8-11。用于修剪的立方稀疏调度器。
幅度修剪的一个问题是,它实际上是为纯监督学习而设计的,其中每个权重的重要性与手头的任务直接相关。相比之下,在迁移学习中,权重的重要性主要由预训练阶段确定,因此幅度修剪可能会移除对微调任务重要的连接。最近,Hugging Face 的研究人员提出了一种称为移动修剪的自适应方法——让我们来看一下。²⁰
移动修剪
移动修剪背后的基本思想是逐渐在微调过程中移除权重,使模型逐渐变得更稀疏。关键的新颖之处在于,在微调过程中,权重和分数都是可学习的。因此,与幅度修剪直接从权重派生(如幅度修剪)不同,移动修剪中的分数是任意的,并且通过梯度下降学习,就像任何其他神经网络参数一样。这意味着在反向传播中,我们还要跟踪损失L相对于分数S ij的梯度。
一旦学习了分数,就很容易使用𝐌 = Top k ( 𝐒 )生成二进制掩码。²¹
运动剪枝背后的直觉是,“移动”离零最远的权重是最重要的。换句话说,正权重在精细调整期间增加(负权重相反),这相当于说分数随着权重远离零而增加。如图 8-12 所示,这种行为与幅值剪枝不同,后者选择离零最远的权重作为最重要的权重。

图 8-12。幅值剪枝(左)和运动剪枝(右)中移除的权重的比较
这两种剪枝方法之间的差异也在剩余权重的分布中显而易见。如图 8-13 所示,幅值剪枝产生两个权重簇,而运动剪枝产生更平滑的分布。
截至本书撰写时, Transformers 不支持开箱即用的剪枝方法。幸运的是,有一个名为神经网络块运动剪枝的巧妙库实现了许多这些想法,如果内存限制是一个问题,我们建议查看它。

图 8-13。剩余权重的分布,用于幅值剪枝(MaP)和运动剪枝(MvP)
结论
我们已经看到,优化 Transformer 以部署到生产环境中涉及沿两个维度的压缩:延迟和内存占用。从经过精细调整的模型开始,我们应用了蒸馏、量化和 ORT 优化,显著减少了这两者。特别是,我们发现量化和 ORT 中的转换给出了最大的收益,而付出的努力最小。
尽管剪枝是减少 Transformer 模型存储大小的有效策略,但当前的硬件并未针对稀疏矩阵运算进行优化,这限制了这种技术的实用性。然而,这是一个活跃的研究领域,到本书上市时,许多这些限制可能已经得到解决。
那么接下来呢?本章中的所有技术都可以应用到其他任务中,比如问答、命名实体识别或语言建模。如果您发现自己难以满足延迟要求,或者您的模型占用了所有的计算预算,我们建议尝试其中之一。
在下一章中,我们将摆脱性能优化,探讨每个数据科学家的噩梦:处理少量或没有标签的情况。
¹ S. Larson 等人,“意图分类和超出范围预测的评估数据集”,(2019 年)。
² 正如 Emmanuel Ameisen 在构建机器学习驱动的应用(O’Reilly)中所描述的,业务或产品指标是最重要的考虑因素。毕竟,如果您的模型不能解决业务关心的问题,那么它的准确性就无关紧要。在本章中,我们将假设您已经为应用程序定义了重要的指标,并专注于优化模型指标。
³ C. Buciluă等人,“模型压缩”,第 12 届 ACM SIGKDD 国际知识发现和数据挖掘会议论文集(2006 年 8 月):535-541,https://doi.org/10.1145/1150402.1150464。
⁴ G. Hinton, O. Vinyals 和 J. Dean,“蒸馏神经网络中的知识”,(2015 年)。
⁵ W. Fedus, B. Zoph, and N. Shazeer,“Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity”,(2021)。
⁶ Geoff Hinton 在一次演讲中创造了这个术语,用来指代软化概率揭示了教师的隐藏知识的观察。
⁷ 我们在第五章中也遇到了与文本生成相关的温度。
⁸ V. Sanh 等人,“DistilBERT, a Distilled Version of BERT: Smaller, Faster, Cheaper and Lighter”,(2019)。
⁹ Y. Kim and H. Awadalla,“FastFormers: Highly Efficient Transformer Models for Natural Language Understanding”,(2020)。
¹⁰ 默认情况下,Trainer 在进行分类任务微调时会寻找名为 labels 的列。您还可以通过指定 TrainingArguments 的 label_names 参数来覆盖此行为。
¹¹ 对通用的精炼语言模型进行微调的方法有时被称为“任务不可知”精炼。
¹² T. Akiba 等人,“Optuna: A Next-Generation Hyperparameter Optimization Framework”,(2019)。
¹³ 仿射映射只是神经网络线性层中你熟悉的 y = A x + b 映射的一个花哨的名字。
¹⁴ 还有一个名为 ONNX-ML 的标准,专门为传统的机器学习模型(如随机森林)和 Scikit-learn 等框架设计。
¹⁵ 其他流行的加速器包括NVIDIA 的 TensorRT和Apache TVM。
¹⁶ 融合操作涉及将一个运算符(通常是激活函数)合并到另一个运算符中,以便它们可以一起执行。例如,假设我们想将激活函数 f 应用于矩阵乘积 A × B。通常,乘积的结果需要写回到 GPU 存储器,然后再计算激活函数。运算符融合允许我们一步计算 f ( A × B )。常量折叠是指在编译时评估常量表达式,而不是在运行时。
¹⁷ B. Hassibi and D. Stork,“Second Order Derivatives for Network Pruning: Optimal Brain Surgeon,” Proceedings of the 5th International Conference on Neural Information Processing Systems (November 1992): 164–171,https://papers.nips.cc/paper/1992/hash/303ed4c69846ab36c2904d3ba8573050-Abstract.html。
¹⁸ S. Han 等人,“Learning Both Weights and Connections for Efficient Neural Networks”,(2015)。
¹⁹ M. Zhu and S. Gupta,“To Prune, or Not to Prune: Exploring the Efficacy of Pruning for Model Compression”,(2017)。
²⁰ V. Sanh, T. Wolf, and A.M. Rush,“Movement Pruning: Adaptive Sparsity by Fine-Tuning”,(2020)。
²¹ 还有一种“软”版本的移动修剪,其中不是选择权重的前k %,而是使用全局阈值τ来定义二进制掩码:𝐌 = ( 𝐒 > τ )。
第九章:处理少量或没有标签
有一个问题深深地植根在每个数据科学家的脑海中,通常是他们在新项目开始时首先问的事情:是否有任何标记的数据?往往情况是“没有”或“有一点”,然后客户期望你的团队的高级机器学习模型仍然能够表现良好。由于在非常小的数据集上训练模型通常不会产生良好的结果,一个明显的解决方案是标注更多的数据。然而,这需要时间,而且可能非常昂贵,特别是如果每个标注都需要领域专业知识来验证。
幸运的是,有几种方法非常适合处理少量或没有标签的情况!你可能已经熟悉其中一些,比如零样本或少样本学习,正如 GPT-3 仅凭几十个例子就能执行各种任务的能力所示。
一般来说,最佳的方法取决于任务、可用数据量以及该数据中有多少是标记的。图 9-1 中显示的决策树可以帮助我们在选择最合适的方法的过程中进行指导。

图 9-1。在缺乏大量标记数据的情况下,可以用来提高模型性能的几种技术
让我们逐步走过这个决策树:
- 你有标记的数据吗?
即使只有少量标记的样本,也可以对哪种方法最有效产生影响。如果根本没有标记的数据,可以从零样本学习方法开始,这通常可以为后续工作奠定坚实的基础。
- 有多少标签?
如果有标记的数据可用,决定因素是有多少。如果你有大量的训练数据可用,你可以使用第二章中讨论的标准微调方法。
- 你有未标记的数据吗?
如果你只有少量标记的样本,如果你可以访问大量未标记的数据,这将非常有帮助。如果你可以访问未标记的数据,你可以在训练分类器之前使用它来微调语言模型,或者你可以使用更复杂的方法,如无监督数据增强(UDA)或不确定性感知的自我训练(UST)。¹ 如果你没有任何未标记的数据可用,你就没有标注更多数据的选择。在这种情况下,你可以使用少样本学习,或者使用预训练语言模型的嵌入来执行最近邻搜索。
在本章中,我们将通过解决许多支持团队面临的常见问题来逐步走过这个决策树,这些团队使用像Jira或GitHub这样的问题跟踪器来帮助他们的用户:根据问题的描述为问题打标签。这些标签可能定义问题类型、导致问题的产品,或者负责处理报告问题的团队。自动化这个过程可以对生产力产生重大影响,并使支持团队能够专注于帮助他们的用户。作为一个运行的示例,我们将使用与一个流行的开源项目相关的 GitHub 问题: Transformers!现在让我们来看看这些问题中包含了哪些信息,如何构建任务,以及如何获取数据。
Transformers!现在让我们来看看这些问题中包含了哪些信息,如何构建任务,以及如何获取数据。
注
本章介绍的方法对于文本分类非常有效,但对于更复杂的任务,如命名实体识别、问答或摘要,可能需要其他技术,如数据增强。
构建 GitHub 问题标记器
如果您导航到 Transformers 存储库的Issues 标签,您会发现像图 9-2 中所示的问题,其中包含标题、描述和一组标签,这些标签或标签表征了问题。这表明了一个自然的方式来构建监督学习任务:给定一个问题的标题和描述,预测一个或多个标签。由于每个问题可以分配一个可变数量的标签,这意味着我们正在处理一个多标签文本分类问题。这通常比我们在第二章中遇到的多类问题更具挑战性,那里每个推文只分配给一个情感。
Transformers 存储库的Issues 标签,您会发现像图 9-2 中所示的问题,其中包含标题、描述和一组标签,这些标签或标签表征了问题。这表明了一个自然的方式来构建监督学习任务:给定一个问题的标题和描述,预测一个或多个标签。由于每个问题可以分配一个可变数量的标签,这意味着我们正在处理一个多标签文本分类问题。这通常比我们在第二章中遇到的多类问题更具挑战性,那里每个推文只分配给一个情感。

图 9-2。 Transformers 存储库上的典型 GitHub 问题
Transformers 存储库上的典型 GitHub 问题
现在我们已经看到了 GitHub 问题的样子,让我们看看如何下载它们以创建我们的数据集。
获取数据
为了获取存储库的所有问题,我们将使用GitHub REST API来轮询Issues端点。这个端点返回一个 JSON 对象列表,每个对象包含有关问题的大量字段,包括其状态(打开或关闭),谁打开了问题,以及我们在图 9-2 中看到的标题、正文和标签。
由于获取所有问题需要一些时间,我们在本书的GitHub 存储库中包含了一个github-issues-transformers.jsonl文件,以及一个fetch_issues()函数,您可以使用它来自行下载问题。
注意
GitHub REST API 将拉取请求视为问题,因此我们的数据集包含两者的混合。为了保持简单,我们将为两种问题类型开发我们的分类器,尽管在实践中,您可能考虑构建两个单独的分类器,以更精细地控制模型的性能。
现在我们知道如何获取数据,让我们来看看如何清理数据。
准备数据
一旦我们下载了所有问题,我们可以使用 Pandas 加载它们:
import pandas as pd
dataset_url = "https://git.io/nlp-with-transformers"
df_issues = pd.read_json(dataset_url, lines=True)
print(f"DataFrame shape: {df_issues.shape}")
DataFrame shape: (9930, 26)
我们的数据集中有近 10000 个问题,通过查看单个行,我们可以看到从 GitHub API 检索到的信息包含许多字段,如 URL、ID、日期、用户、标题、正文以及标签:
cols = ["url", "id", "title", "user", "labels", "state", "created_at", "body"]
df_issues.loc[2, cols].to_frame()
| 2 | |
|---|---|
| url | https://api.github.com/repos/huggingface/trans… |
| id | 849529761 |
| title | [DeepSpeed] ZeRO stage 3 integration: getting … |
| user | {‘login’: ’stas00’, ‘id’: 10676103, ‘node_id’:… |
| labels | [{'id’: 2659267025, ‘node_id’: ‘MDU6TGFiZWwyNj… |
| state | open |
| created_at | 2021-04-02 23:40:42 |
| body | **[This is not yet alive, preparing for the re… |
labels列是我们感兴趣的东西,每一行都包含一个关于每个标签的元数据的 JSON 对象列表:
[
{
"id":2659267025,
"node_id":"MDU6TGFiZWwyNjU5MjY3MDI1",
"url":"https://api.github.com/repos/huggingface...",
"name":"DeepSpeed",
"color":"4D34F7",
"default":false,
"description":""
}
]
对于我们的目的,我们只对每个标签对象的name字段感兴趣,因此让我们用标签名称覆盖labels列:
df_issues["labels"] = (df_issues["labels"]
.apply(lambda x: [meta["name"] for meta in x]))
df_issues[["labels"]].head()
| labels | |
|---|---|
| 0 | [] |
| 1 | [] |
| 2 | [DeepSpeed] |
| 3 | [] |
| 4 | [] |
现在labels列中的每一行都是 GitHub 标签的列表,因此我们可以计算每一行的长度,以找到每个问题的标签数量:
df_issues["labels"].apply(lambda x : len(x)).value_counts().to_frame().T
| 0 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
| labels | 6440 | 3057 | 305 | 100 | 25 | 3 |
这表明大多数问题没有标签或只有一个标签,而更少的问题有多个标签。接下来让我们来看看数据集中前 10 个最频繁的标签。在 Pandas 中,我们可以通过“爆炸”labels列来做到这一点,使列表中的每个标签成为一行,然后简单地计算每个标签的出现次数:
df_counts = df_issues["labels"].explode().value_counts()
print(f"Number of labels: {len(df_counts)}")
# Display the top-8 label categories
df_counts.to_frame().head(8).T
Number of labels: 65
| wontfix | model card | Core: Tokenization | New model | Core: Modeling | Help wanted | Good First Issue | Usage | |
|---|---|---|---|---|---|---|---|---|
| labels | 2284 | 649 | 106 | 98 | 64 | 52 | 50 | 46 |
我们可以看到数据集中有 65 个唯一的标签,并且类别非常不平衡,wontfix和model card是最常见的标签。为了使分类问题更易处理,我们将专注于构建一部分标签的标签器。例如,一些标签,如Good First Issue或Help Wanted,可能非常难以从问题的描述中预测,而其他一些标签,如model card,可以通过简单的规则进行分类,以检测何时在 Hugging Face Hub 上添加了模型卡。
以下代码将过滤数据集,以便我们将使用的标签子集,以及对名称的标准化,使其更易于阅读:
label_map = {"Core: Tokenization": "tokenization",
"New model": "new model",
"Core: Modeling": "model training",
"Usage": "usage",
"Core: Pipeline": "pipeline",
"TensorFlow": "tensorflow or tf",
"PyTorch": "pytorch",
"Examples": "examples",
"Documentation": "documentation"}
def filter_labels(x):
return [label_map[label] for label in x if label in label_map]
df_issues["labels"] = df_issues["labels"].apply(filter_labels)
all_labels = list(label_map.values())
现在让我们来看一下新标签的分布:
df_counts = df_issues["labels"].explode().value_counts()
df_counts.to_frame().T
| tokenization | new model | model training | usage | pipeline | tensorflow or tf | pytorch | documentation | examples | |
|---|---|---|---|---|---|---|---|---|---|
| 标签 | 106 | 98 | 64 | 46 | 42 | 41 | 37 | 28 | 24 |
在本章的后面,我们会发现将未标记的问题视为单独的训练拆分是有用的,因此让我们创建一个新列,指示问题是否被标记:
df_issues["split"] = "unlabeled"
mask = df_issues["labels"].apply(lambda x: len(x)) > 0
df_issues.loc[mask, "split"] = "labeled"
df_issues["split"].value_counts().to_frame()
| 拆分 | |
|---|---|
| 未标记 | 9489 |
| 标记 | 441 |
现在让我们来看一个例子:
for column in ["title", "body", "labels"]:
print(f"{column}: {df_issues[column].iloc[26][:500]}\n")
title: Add new CANINE model
body: # New model addition
## Model description
Google recently proposed a new **C**haracter **A**rchitecture with **N**o
tokenization **I**n **N**eural **E**ncoders architecture (CANINE). Not only
the title is exciting:
Pipelined NLP systems have largely been superseded by end-to-end neural
modeling, yet nearly all commonly-used models still require an explicit
tokenization step. While recent tokenization approaches based on data-derived
subword lexicons are less brittle than manually en
labels: ['new model']
在这个例子中,提出了一个新的模型架构,因此new model标签是有意义的。我们还可以看到title包含了对我们的分类器有用的信息,因此让我们将其与body字段中的问题描述连接起来:
df_issues["text"] = (df_issues
.apply(lambda x: x["title"] + "\n\n" + x["body"], axis=1))
在查看数据的其余部分之前,让我们检查数据中是否有重复项,并使用drop_duplicates()方法删除它们:
len_before = len(df_issues)
df_issues = df_issues.drop_duplicates(subset="text")
print(f"Removed {(len_before-len(df_issues))/len_before:.2%} duplicates.")
Removed 1.88% duplicates.
我们可以看到我们的数据集中有一些重复的问题,但它们只占很小的比例。与其他章节一样,快速查看我们文本中的单词数量也是一个好主意,以查看当我们截断到每个模型的上下文大小时是否会丢失太多信息:
import numpy as np
import matplotlib.pyplot as plt
(df_issues["text"].str.split().apply(len)
.hist(bins=np.linspace(0, 500, 50), grid=False, edgecolor="C0"))
plt.title("Words per issue")
plt.xlabel("Number of words")
plt.ylabel("Number of issues")
plt.show()

分布具有许多文本数据集的长尾特征。大多数文本都相当短,但也有超过 500 个单词的问题。通常会有一些非常长的问题,特别是当错误消息和代码片段与它们一起发布时。鉴于大多数转换器模型的上下文大小为 512 个标记或更大,截断少数长问题不太可能影响整体性能。现在我们已经探索和清理了我们的数据集,最后要做的是定义我们的训练和验证集,以对我们的分类器进行基准测试。让我们看看如何做到这一点。
创建训练集
对于多标签问题,创建训练和验证集会有些棘手,因为并不是所有标签都能保证平衡。然而,可以进行近似处理,我们可以使用专门为此目的设置的Scikit-multilearn 库。我们需要做的第一件事是将我们的标签集(如pytorch和tokenization)转换为模型可以处理的格式。在这里,我们可以使用 Scikit-learn 的MultiLabelBinarizer类,它接受一个标签名称列表,并创建一个向量,其中缺失的标签为零,存在的标签为一。我们可以通过将MultiLabelBinarizer拟合到all_labels上来测试这一点,以学习从标签名称到 ID 的映射,如下所示:
from sklearn.preprocessing import MultiLabelBinarizer
mlb = MultiLabelBinarizer()
mlb.fit([all_labels])
mlb.transform([["tokenization", "new model"], ["pytorch"]])
array([[0, 0, 0, 1, 0, 0, 0, 1, 0],
[0, 0, 0, 0, 0, 1, 0, 0, 0]])
在这个简单的例子中,我们可以看到第一行有两个对应于tokenization和new model标签的 1,而第二行只有一个对应于pytorch的命中。
为了创建拆分,我们可以使用 Scikit-multilearn 的iterative_train_test_split()函数,该函数会迭代创建平衡标签的训练/测试拆分。我们将其包装在一个可以应用于DataFrame的函数中。由于该函数期望一个二维特征矩阵,因此在进行拆分之前,我们需要为可能的索引添加一个维度:
from skmultilearn.model_selection import iterative_train_test_split
def balanced_split(df, test_size=0.5):
ind = np.expand_dims(np.arange(len(df)), axis=1)
labels = mlb.transform(df["labels"])
ind_train, _, ind_test, _ = iterative_train_test_split(ind, labels,
test_size)
return df.iloc[ind_train[:, 0]], df.iloc[ind_test[:,0]]
有了balanced_split()函数,我们可以将数据分成监督和非监督数据集,然后为监督部分创建平衡的训练、验证和测试集:
from sklearn.model_selection import train_test_split
df_clean = df_issues[["text", "labels", "split"]].reset_index(drop=True).copy()
df_unsup = df_clean.loc[df_clean["split"] == "unlabeled", ["text", "labels"]]
df_sup = df_clean.loc[df_clean["split"] == "labeled", ["text", "labels"]]
np.random.seed(0)
df_train, df_tmp = balanced_split(df_sup, test_size=0.5)
df_valid, df_test = balanced_split(df_tmp, test_size=0.5)
最后,让我们创建一个DatasetDict,包含所有的拆分,这样我们就可以轻松地对数据集进行标记,并与Trainer集成。在这里,我们将使用巧妙的from_pandas()方法直接从相应的 PandasDataFrame中加载每个拆分:
from datasets import Dataset, DatasetDict
ds = DatasetDict({
"train": Dataset.from_pandas(df_train.reset_index(drop=True)),
"valid": Dataset.from_pandas(df_valid.reset_index(drop=True)),
"test": Dataset.from_pandas(df_test.reset_index(drop=True)),
"unsup": Dataset.from_pandas(df_unsup.reset_index(drop=True))})
看起来不错,最后要做的事情就是创建一些训练切片,这样我们就可以评估每个分类器的性能,作为训练集大小的函数。
创建训练切片
数据集具有我们想要在本章中调查的两个特征:稀疏标记数据和多标签分类。训练集只包含 220 个示例进行训练,即使使用迁移学习也是一个挑战。为了深入研究本章中每种方法在少量标记数据下的表现,我们还将创建训练数据的切片,其中包含更少的样本。然后,我们可以绘制样本数量与性能,并调查各种情况。我们将从每个标签仅有八个样本开始,并逐渐增加,直到切片覆盖整个训练集,使用iterative_train_test_split()函数:
np.random.seed(0)
all_indices = np.expand_dims(list(range(len(ds["train"]))), axis=1)
indices_pool = all_indices
labels = mlb.transform(ds["train"]["labels"])
train_samples = [8, 16, 32, 64, 128]
train_slices, last_k = [], 0
for i, k in enumerate(train_samples):
# Split off samples necessary to fill the gap to the next split size
indices_pool, labels, new_slice, _ = iterative_train_test_split(
indices_pool, labels, (k-last_k)/len(labels))
last_k = k
if i==0: train_slices.append(new_slice)
else: train_slices.append(np.concatenate((train_slices[-1], new_slice)))
# Add full dataset as last slice
train_slices.append(all_indices), train_samples.append(len(ds["train"]))
train_slices = [np.squeeze(train_slice) for train_slice in train_slices]
请注意,这种迭代方法只是大致将样本分割成所需的大小,因为在给定的拆分大小下,不总是可能找到一个平衡的拆分:
print("Target split sizes:")
print(train_samples)
print("Actual split sizes:")
print([len(x) for x in train_slices])
Target split sizes:
[8, 16, 32, 64, 128, 223]
Actual split sizes:
[10, 19, 36, 68, 134, 223]
我们将使用指定的拆分大小作为以下图表的标签。太好了,我们终于将我们的数据集准备成了训练拆分,接下来让我们看看如何训练一个强大的基线模型!
实施一个朴素贝叶斯基线
每当你开始一个新的 NLP 项目时,实施一组强大的基线总是一个好主意。这样做有两个主要原因:
-
基于正则表达式、手工制作的规则或非常简单的模型的基线可能已经非常有效地解决了问题。在这些情况下,没有理由使用 transformers 等大型工具,这些工具通常在生产环境中更复杂。
-
基线提供了快速检查,当你探索更复杂的模型时。例如,假设你训练 BERT-large 并在验证集上获得 80%的准确率。你可能会认为这是一个难题,然后结束了。但是如果你知道一个简单的分类器如逻辑回归获得了 95%的准确率呢?那就会引起你的怀疑,并促使你调试你的模型。
让我们从训练一个基线模型开始我们的分析。对于文本分类,一个很好的基线是朴素贝叶斯分类器,因为它非常简单、训练速度快,并且对输入的扰动相当稳健。Scikit-learn 的朴素贝叶斯实现不直接支持多标签分类,但幸运的是,我们可以再次使用 Scikit-multilearn 库,将问题转化为一个一对多的分类任务,其中我们为L标签训练L个二元分类器。首先,让我们使用一个多标签二值化器在我们的训练集中创建一个新的label_ids列。我们可以使用map()函数一次性处理所有的处理:
def prepare_labels(batch):
batch["label_ids"] = mlb.transform(batch["labels"])
return batch
ds = ds.map(prepare_labels, batched=True)
为了衡量我们分类器的性能,我们将使用微观和宏观F[1]-scores,前者跟踪频繁标签的性能,后者忽略频率,跟踪所有标签的性能。由于我们将评估每个模型在不同大小的训练拆分上,让我们创建一个defaultdict,其中包含一个列表,用于存储每个拆分的分数:
from collections import defaultdict
macro_scores, micro_scores = defaultdict(list), defaultdict(list)
现在我们终于准备好训练我们的基线了!下面是训练模型和评估我们的分类器在不断增加的训练集大小上的代码:
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import classification_report
from skmultilearn.problem_transform import BinaryRelevance
from sklearn.feature_extraction.text import CountVectorizer
for train_slice in train_slices:
# Get training slice and test data
ds_train_sample = ds["train"].select(train_slice)
y_train = np.array(ds_train_sample["label_ids"])
y_test = np.array(ds["test"]["label_ids"])
# Use a simple count vectorizer to encode our texts as token counts
count_vect = CountVectorizer()
X_train_counts = count_vect.fit_transform(ds_train_sample["text"])
X_test_counts = count_vect.transform(ds["test"]["text"])
# Create and train our model!
classifier = BinaryRelevance(classifier=MultinomialNB())
classifier.fit(X_train_counts, y_train)
# Generate predictions and evaluate
y_pred_test = classifier.predict(X_test_counts)
clf_report = classification_report(
y_test, y_pred_test, target_names=mlb.classes_, zero_division=0,
output_dict=True)
# Store metrics
macro_scores["Naive Bayes"].append(clf_report["macro avg"]["f1-score"])
micro_scores["Naive Bayes"].append(clf_report["micro avg"]["f1-score"])
这段代码块中有很多内容,让我们来解开它。首先,我们获取训练切片并对标签进行编码。然后我们使用计数向量化器对文本进行编码,简单地创建一个与词汇量大小相同的向量,其中每个条目对应于文本中标记出现的频率。这被称为词袋方法,因为所有关于单词顺序的信息都丢失了。然后我们训练分类器,并使用测试集上的预测来通过分类报告得到微观和宏观F[1]-分数。
通过以下辅助函数,我们可以绘制这个实验的结果:
import matplotlib.pyplot as plt
def plot_metrics(micro_scores, macro_scores, sample_sizes, current_model):
fig, (ax0, ax1) = plt.subplots(1, 2, figsize=(10, 4), sharey=True)
for run in micro_scores.keys():
if run == current_model:
ax0.plot(sample_sizes, micro_scores[run], label=run, linewidth=2)
ax1.plot(sample_sizes, macro_scores[run], label=run, linewidth=2)
else:
ax0.plot(sample_sizes, micro_scores[run], label=run,
linestyle="dashed")
ax1.plot(sample_sizes, macro_scores[run], label=run,
linestyle="dashed")
ax0.set_title("Micro F1 scores")
ax1.set_title("Macro F1 scores")
ax0.set_ylabel("Test set F1 score")
ax0.legend(loc="lower right")
for ax in [ax0, ax1]:
ax.set_xlabel("Number of training samples")
ax.set_xscale("log")
ax.set_xticks(sample_sizes)
ax.set_xticklabels(sample_sizes)
ax.minorticks_off()
plt.tight_layout()
plt.show()
plot_metrics(micro_scores, macro_scores, train_samples, "Naive Bayes")

请注意,我们在对数刻度上绘制样本数量。从图中我们可以看到,随着训练样本数量的增加,微观和宏观F[1]-分数都有所提高。由于每个切片可能具有不同的类分布,因此在训练样本很少的情况下,结果也稍微有些嘈杂。然而,这里重要的是趋势,所以现在让我们看看这些结果与基于 Transformer 的方法相比如何!
使用无标记数据
我们将考虑的第一种技术是零样本分类,这在没有任何标记数据的情况下非常适用。这在行业中非常常见,可能是因为没有带标签的历史数据,或者因为获取数据的标签很困难。在本节中,我们会有点作弊,因为我们仍然会使用测试数据来衡量性能,但我们不会使用任何数据来训练模型(否则与后续方法的比较将会很困难)。
零样本分类的目标是利用预训练模型,在任务特定语料库上没有进行额外的微调。为了更好地了解这种工作原理,回想一下像 BERT 这样的语言模型是预训练的,用于在成千上万本书和大量维基百科转储中预测文本中的屏蔽标记。为了成功预测缺失的标记,模型需要了解上下文中的主题。我们可以尝试欺骗模型,通过提供一个句子来为我们对文档进行分类:
“这一部分是关于主题[MASK]的。”
由于这是数据集中自然出现的文本,模型应该能够合理地对文档的主题提出建议。²
让我们通过以下玩具问题进一步说明这一点:假设你有两个孩子,一个喜欢有汽车的电影,而另一个更喜欢有动物的电影。不幸的是,他们已经看过你知道的所有电影,所以你想建立一个函数,告诉你一个新电影的主题是什么。自然地,你会转向 Transformer 来完成这个任务。首先要尝试的是在fill-mask管道中加载 BERT-base,该管道使用屏蔽语言模型来预测屏蔽标记的内容:
from transformers import pipeline
pipe = pipeline("fill-mask", model="bert-base-uncased")
接下来,让我们构建一个小电影描述,并在其中添加一个带有屏蔽词的提示。提示的目标是引导模型帮助我们进行分类。fill-mask管道返回填充屏蔽位置的最有可能的标记:
movie_desc = "The main characters of the movie madacascar \
are a lion, a zebra, a giraffe, and a hippo. "
prompt = "The movie is about [MASK]."
output = pipe(movie_desc + prompt)
for element in output:
print(f"Token {element['token_str']}:\t{element['score']:.3f}%")
Token animals: 0.103%
Token lions: 0.066%
Token birds: 0.025%
Token love: 0.015%
Token hunting: 0.013%
显然,模型只预测与动物相关的标记。我们也可以反过来,而不是获取最有可能的标记,我们可以查询管道获取几个给定标记的概率。对于这个任务,我们可以选择cars和animals,所以我们可以将它们作为目标传递给管道:
output = pipe(movie_desc + prompt, targets=["animals", "cars"])
for element in output:
print(f"Token {element['token_str']}:\t{element['score']:.3f}%")
Token animals: 0.103%
Token cars: 0.001%
毫不奇怪,对于标记为cars的预测概率要远远小于animals。让我们看看这是否也适用于更接近汽车的描述:
movie_desc = "In the movie transformers aliens \
can morph into a wide range of vehicles."
output = pipe(movie_desc + prompt, targets=["animals", "cars"])
for element in output:
print(f"Token {element['token_str']}:\t{element['score']:.3f}%")
Token cars: 0.139%
Token animals: 0.006%
它确实可以!这只是一个简单的例子,如果我们想确保它运行良好,我们应该进行彻底的测试,但它说明了本章讨论的许多方法的关键思想:找到一种方法,使预训练模型适应另一个任务,而无需对其进行训练。在这种情况下,我们设置了一个提示,其中包含一个掩码,以便我们可以直接使用掩码语言模型进行分类。让我们看看是否可以通过调整一个在更接近文本分类的任务上进行了微调的模型来做得更好:自然语言推理(NLI)。
使用掩码语言模型进行分类是一个不错的技巧,但是我们可以通过使用一个在更接近分类的任务上训练过的模型来做得更好。有一个称为文本蕴涵的巧妙代理任务符合要求。在文本蕴涵中,模型需要确定两个文本段落是否可能相互跟随或相互矛盾。模型通常是使用诸如多种体裁 NLI 语料库(MNLI)或跨语言 NLI 语料库(XNLI)等数据集进行蕴涵和矛盾的检测。³
这些数据集中的每个样本由三部分组成:前提、假设和标签,标签可以是蕴涵、中性或矛盾中的一个。当假设文本在前提下必然为真时,分配蕴涵标签。当假设在前提下必然为假或不合适时,使用矛盾标签。如果这两种情况都不适用,则分配中性标签。参见表 9-1 中的示例。
表 9-1。MLNI 数据集中的三个类
| 前提 | 假设 | 标签 |
|---|---|---|
| 他最喜欢的颜色是蓝色。 | 他喜欢重金属音乐。 | 中性 |
| 她觉得这个笑话很搞笑。 | 她认为这个笑话一点都不好笑。 | 矛盾 |
| 这所房子最近建造。 | 这所房子是新的。 | 蕴涵 |
现在,事实证明我们可以劫持一个在 MNLI 数据集上训练的模型,构建一个分类器而无需任何标签!关键思想是将我们希望分类的文本视为前提,然后将假设制定为:
“这个例子是关于{label}的。”
在这里我们插入标签的类名。蕴涵分数告诉我们前提很可能是关于那个主题的,我们可以依次为任意数量的类运行这个。这种方法的缺点是我们需要为每个类执行一次前向传播,这使得它比标准分类器效率低。另一个稍微棘手的方面是标签名称的选择可能对准确性产生很大影响,通常最好选择具有语义含义的标签。例如,如果标签只是Class 1,模型就不知道这可能意味着什么,以及这是否构成了矛盾或蕴涵。
 Transformers 具有内置的零样本分类 MNLI 模型。我们可以通过管道初始化它如下:
Transformers 具有内置的零样本分类 MNLI 模型。我们可以通过管道初始化它如下:
from transformers import pipeline
pipe = pipeline("zero-shot-classification", device=0)
设置device=0确保模型在 GPU 上运行,而不是默认的 CPU,以加快推理速度。要对文本进行分类,我们只需要将其传递给管道,并附上标签名称。此外,我们可以设置multi_label=True以确保返回所有分数,而不仅仅是单标签分类的最大值:
sample = ds["train"][0]
print(f"Labels: {sample['labels']}")
output = pipe(sample["text"], all_labels, multi_label=True)
print(output["sequence"][:400])
print("\nPredictions:")
for label, score in zip(output["labels"], output["scores"]):
print(f"{label}, {score:.2f}")
Labels: ['new model']
Add new CANINE model
# New model addition
## Model description
Google recently proposed a new **C**haracter **A**rchitecture with **N**o
tokenization **I**n **N**eural **E**ncoders architecture (CANINE). Not only the
title is exciting:
> Pipelined NLP systems have largely been superseded by end-to-end neural
modeling, yet nearly all commonly-used models still require an explicit tokeni
Predictions:
new model, 0.98
tensorflow or tf, 0.37
examples, 0.34
usage, 0.30
pytorch, 0.25
documentation, 0.25
model training, 0.24
tokenization, 0.17
pipeline, 0.16
注意
由于我们使用的是子词分词器,我们甚至可以将代码传递给模型!分词可能不太高效,因为零样本管道的预训练数据集只包含了一小部分代码片段,但由于代码也由许多自然词组成,这并不是一个大问题。此外,代码块可能包含重要信息,例如框架(PyTorch 或 TensorFlow)。
我们可以看到模型非常确信这段文本是关于一个新模型的,但它也为其他标签产生了相对较高的分数。零射击分类的一个重要方面是我们所处的领域。我们在这里处理的文本非常技术化,大部分是关于编码的,这使它们与 MNLI 数据集中的原始文本分布相当不同。因此,这对于模型来说是一个具有挑战性的任务并不奇怪;它可能对某些领域的工作效果比其他领域要好得多,这取决于它们与训练数据的接近程度。
让我们编写一个函数,通过零射击管道将单个示例传递,并通过运行map()将其扩展到整个验证集:
def zero_shot_pipeline(example):
output = pipe(example["text"], all_labels, multi_label=True)
example["predicted_labels"] = output["labels"]
example["scores"] = output["scores"]
return example
ds_zero_shot = ds["valid"].map(zero_shot_pipeline)
现在我们有了分数,下一步是确定应该为每个示例分配哪组标签。我们可以尝试一些选项:
-
定义一个阈值,并选择高于阈值的所有标签。
-
选择具有最高分数的前k个标签。
为了帮助我们确定哪种方法最好,让我们编写一个get_preds()函数,应用其中一种方法来获取预测:
def get_preds(example, threshold=None, topk=None):
preds = []
if threshold:
for label, score in zip(example["predicted_labels"], example["scores"]):
if score >= threshold:
preds.append(label)
elif topk:
for i in range(topk):
preds.append(example["predicted_labels"][i])
else:
raise ValueError("Set either `threshold` or `topk`.")
return {"pred_label_ids": list(np.squeeze(mlb.transform([preds])))}
接下来,让我们编写第二个函数get_clf_report(),它从具有预测标签的数据集中返回 Scikit-learn 分类报告:
def get_clf_report(ds):
y_true = np.array(ds["label_ids"])
y_pred = np.array(ds["pred_label_ids"])
return classification_report(
y_true, y_pred, target_names=mlb.classes_, zero_division=0,
output_dict=True)
有了这两个函数,让我们从增加几个值的k开始,然后绘制验证集上的微观和宏观* F * [1]-分数:
macros, micros = [], []
topks = [1, 2, 3, 4]
for topk in topks:
ds_zero_shot = ds_zero_shot.map(get_preds, batched=False,
fn_kwargs={'topk': topk})
clf_report = get_clf_report(ds_zero_shot)
micros.append(clf_report['micro avg']['f1-score'])
macros.append(clf_report['macro avg']['f1-score'])
plt.plot(topks, micros, label='Micro F1')
plt.plot(topks, macros, label='Macro F1')
plt.xlabel("Top-k")
plt.ylabel("F1-score")
plt.legend(loc='best')
plt.show()

从图中我们可以看到,通过选择每个示例的最高分数的标签(top 1)获得了最佳结果。这也许并不奇怪,因为我们数据集中的大多数示例只有一个标签。现在让我们将其与设置阈值进行比较,这样我们可能可以对每个示例进行多个标签的预测:
macros, micros = [], []
thresholds = np.linspace(0.01, 1, 100)
for threshold in thresholds:
ds_zero_shot = ds_zero_shot.map(get_preds,
fn_kwargs={"threshold": threshold})
clf_report = get_clf_report(ds_zero_shot)
micros.append(clf_report["micro avg"]["f1-score"])
macros.append(clf_report["macro avg"]["f1-score"])
plt.plot(thresholds, micros, label="Micro F1")
plt.plot(thresholds, macros, label="Macro F1")
plt.xlabel("Threshold")
plt.ylabel("F1-score")
plt.legend(loc="best")
plt.show()

best_t, best_micro = thresholds[np.argmax(micros)], np.max(micros)
print(f'Best threshold (micro): {best_t} with F1-score {best_micro:.2f}.')
best_t, best_macro = thresholds[np.argmax(macros)], np.max(macros)
print(f'Best threshold (micro): {best_t} with F1-score {best_macro:.2f}.')
Best threshold (micro): 0.75 with F1-score 0.46.
Best threshold (micro): 0.72 with F1-score 0.42.
这种方法的表现略逊于 top-1 的结果,但我们可以在这张图中清楚地看到精确度/召回率的权衡。如果我们将阈值设置得太低,那么会有太多的预测,这会导致精确度低。如果我们将阈值设置得太高,那么我们几乎不会进行任何预测,这会产生低召回率。从图中我们可以看到,阈值约为 0.8 是两者之间的最佳平衡点。
由于 top-1 方法表现最佳,让我们使用它来将零射击分类与朴素贝叶斯在测试集上进行比较:
ds_zero_shot = ds['test'].map(zero_shot_pipeline)
ds_zero_shot = ds_zero_shot.map(get_preds, fn_kwargs={'topk': 1})
clf_report = get_clf_report(ds_zero_shot)
for train_slice in train_slices:
macro_scores['Zero Shot'].append(clf_report['macro avg']['f1-score'])
micro_scores['Zero Shot'].append(clf_report['micro avg']['f1-score'])
plot_metrics(micro_scores, macro_scores, train_samples, "Zero Shot")

将零射击管道与基线进行比较,我们观察到两件事:
-
如果我们少于 50 个有标签的样本,零射击管道将轻松胜过基线。
-
即使超过 50 个样本,零射击管道的性能在考虑微观和宏观* F * [1]-分数时仍然优越。微观* F * [1]-分数的结果告诉我们,基线在频繁类别上表现良好,而零射击管道在这些类别上表现出色,因为它不需要任何示例来学习。
注意
您可能会注意到本节中存在一个小悖论:尽管我们谈论处理没有标签的情况,但我们仍然使用验证集和测试集。我们使用它们来展示不同的技术,并使结果可以相互比较。即使在实际用例中,收集一些有标签的示例进行快速评估也是有意义的。重要的一点是,我们没有根据数据调整模型的参数;相反,我们只是调整了一些超参数。
如果您发现在自己的数据集上难以获得良好的结果,可以尝试以下几种方法来改进零射击管道:
-
管道的工作方式使其对标签的名称非常敏感。如果名称不太合理或与文本不容易联系起来,那么管道可能表现不佳。可以尝试使用不同的名称或并行使用几个名称,并在额外的步骤中对它们进行聚合。
-
另一件你可以改进的事情是假设的形式。默认情况下是
hypothesis="This is example is about {}",但你可以传递任何其他文本到管道中。根据使用情况,这可能会提高性能。
现在让我们转向我们有少数标记示例可以用来训练模型的情况。
使用少数标签
在大多数 NLP 项目中,您至少会有一些标记的示例。标签可能直接来自客户或跨公司团队,或者您可能决定自己注释一些示例。即使对于以前的方法,我们也需要一些标记的示例来评估零-shot 方法的效果。在本节中,我们将看看如何最好地利用我们拥有的少数宝贵的标记示例。让我们首先看看一种称为数据增强的技术,它可以帮助我们扩大我们拥有的少量标记数据。
数据增强
在小数据集上提高文本分类器性能的一种简单但有效的方法是应用数据增强技术,从现有数据中生成新的训练样本。这是计算机视觉中的常见策略,其中图像被随机扰动而不改变数据的含义(例如,稍微旋转的猫仍然是一只猫)。对于文本来说,数据增强有些棘手,因为扰动单词或字符可能会完全改变含义。例如,两个问题“大象比老鼠重吗?”和“老鼠比大象重吗?”只有一个词交换,但答案相反。然而,如果文本包含超过几句话(就像我们的 GitHub 问题一样),那么这些类型的转换引入的噪音通常不会影响标签。实际上,通常使用两种类型的数据增强技术:
回译
取源语言中的文本,使用机器翻译将其翻译成一个或多个目标语言,然后将其翻译回源语言。回译通常适用于高资源语言或不包含太多领域特定词汇的语料库。
标记扰动
给定训练集中的文本,随机选择并执行简单的转换,如随机同义词替换、单词插入、交换或删除。⁴
这些转换的示例显示在表 9-2 中。有关 NLP 的其他数据增强技术的详细列表,我们建议阅读 Amit Chaudhary 的博文“NLP 中数据增强的视觉调查”。
表 9-2。文本的不同类型的数据增强技术
| 增强 | 句子 |
|---|---|
| 无 | 即使你打败我梅杰特龙,其他人也会起来打败你的暴政 |
| 同义词替换 | 即使你杀了我梅杰特龙,其他人将证明打败你的暴政 |
| 随机插入 | 即使你打败我梅杰特龙,其他人类也会起来打败你的暴政 |
| 随机交换 | 即使你打败我梅杰特龙,其他人也会起来打败你的暴政 |
| 随机删除 | 即使你我梅杰特龙,其他人也会起来打败暴政 |
| 回译(德语) | 即使你打败我,其他人也会起来打败你的暴政 |
您可以使用像M2M100这样的机器翻译模型来实现回译,而像NlpAug和TextAttack这样的库提供了各种用于标记扰动的方法。在本节中,我们将专注于使用同义词替换,因为它简单易行,并且能够传达数据增强背后的主要思想。
我们将使用 NlpAug 中的ContextualWordEmbsAug增强器来利用 DistilBERT 的上下文词嵌入进行同义词替换。让我们从一个简单的例子开始:
from transformers import set_seed
import nlpaug.augmenter.word as naw
set_seed(3)
aug = naw.ContextualWordEmbsAug(model_path="distilbert-base-uncased",
device="cpu", action="substitute")
text = "Transformers are the most popular toys"
print(f"Original text: {text}")
print(f"Augmented text: {aug.augment(text)}")
Original text: Transformers are the most popular toys
Augmented text: transformers'the most popular toys
在这里,我们可以看到单词“are”已被替换为撇号,以生成一个新的合成训练示例。我们可以将这种增强包装在一个简单的函数中,如下所示:
def augment_text(batch, transformations_per_example=1):
text_aug, label_ids = [], []
for text, labels in zip(batch["text"], batch["label_ids"]):
text_aug += [text]
label_ids += [labels]
for _ in range(transformations_per_example):
text_aug += [aug.augment(text)]
label_ids += [labels]
return {"text": text_aug, "label_ids": label_ids}
现在当我们将这个函数传递给map()方法时,我们可以使用transformations_per_example参数生成任意数量的新示例。我们可以在我们的代码中使用这个函数来训练朴素贝叶斯分类器,只需在选择切片后添加一行:
ds_train_sample = ds_train_sample.map(augment_text, batched=True,
remove_columns=ds_train_sample.column_names).shuffle(seed=42)
包括这一点并重新运行分析会产生如图所示的图表:
plot_metrics(micro_scores, macro_scores, train_samples, "Naive Bayes + Aug")

从图中可以看出,少量数据增强可以将朴素贝叶斯分类器的F[1]-分数提高约 5 个点,并且一旦我们有大约 170 个训练样本,它就会超过零-shot 管道的宏分数。现在让我们来看一个基于使用大型语言模型嵌入的方法。
将嵌入用作查找表
已经证明,像 GPT-3 这样的大型语言模型在解决数据有限的任务方面表现出色。原因是这些模型学习了有用的文本表示,跨越许多维度编码信息,如情感、主题、文本结构等。因此,大型语言模型的嵌入可以用于开发语义搜索引擎,找到相似的文档或评论,甚至对文本进行分类。
在本节中,我们将创建一个文本分类器,它的模型是基于OpenAI API 分类端点。这个想法遵循一个三步过程:
-
使用语言模型嵌入所有标记文本。
-
在存储的嵌入上执行最近邻搜索。
-
聚合最近邻的标签以获得预测。
这个过程在图 9-3 中有所说明,它展示了标记数据是如何嵌入模型并与标签一起存储的。当需要对新文本进行分类时,它也会被嵌入,并且基于最近邻的标签给出标签。重要的是要校准要搜索的邻居数量,因为太少可能会有噪音,太多可能会混入相邻的群体。

图 9-3. 最近邻嵌入查找的示意图
这种方法的美妙之处在于,不需要对模型进行微调就可以利用少量可用的标记数据点。相反,使这种方法起作用的主要决定是选择一个理想情况下在类似领域上预训练的适当模型。
由于 GPT-3 只能通过 OpenAI API 获得,我们将使用 GPT-2 来测试这种技术。具体来说,我们将使用一个在 Python 代码上训练的 GPT-2 变体,这将有望捕捉到我们 GitHub 问题中包含的一些上下文。
让我们编写一个辅助函数,它接受一个文本列表,并使用模型为每个文本创建单一向量表示。我们需要处理的一个问题是,像 GPT-2 这样的转换器模型实际上会返回每个标记一个嵌入向量。例如,给定句子“I took my dog for a walk”,我们可以期望有几个嵌入向量,每个标记一个。但我们真正想要的是整个句子(或我们应用程序中的 GitHub 问题)的单一嵌入向量。为了处理这个问题,我们可以使用一种称为池化的技术。最简单的池化方法之一是对标记嵌入进行平均,这称为均值池化。使用均值池化,我们唯一需要注意的是不要在平均值中包括填充标记,所以我们可以使用注意力掩码来处理。
为了看看这是如何工作的,让我们加载一个 GPT-2 分词器和模型,定义均值池化操作,并将整个过程包装在一个简单的embed_text()函数中:
import torch
from transformers import AutoTokenizer, AutoModel
model_ckpt = "miguelvictor/python-gpt2-large"
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
model = AutoModel.from_pretrained(model_ckpt)
def mean_pooling(model_output, attention_mask):
# Extract the token embeddings
token_embeddings = model_output[0]
# Compute the attention mask
input_mask_expanded = (attention_mask
.unsqueeze(-1)
.expand(token_embeddings.size())
.float())
# Sum the embeddings, but ignore masked tokens
sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, 1)
sum_mask = torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Return the average as a single vector
return sum_embeddings / sum_mask
def embed_text(examples):
inputs = tokenizer(examples["text"], padding=True, truncation=True,
max_length=128, return_tensors="pt")
with torch.no_grad():
model_output = model(**inputs)
pooled_embeds = mean_pooling(model_output, inputs["attention_mask"])
return {"embedding": pooled_embeds.cpu().numpy()}
现在我们可以为每个拆分获取嵌入。请注意,GPT 风格的模型没有填充标记,因此我们需要在可以批量获取嵌入之前添加一个标记,就像在前面的代码中实现的那样。我们将只是为此目的重复使用字符串结束标记:
tokenizer.pad_token = tokenizer.eos_token
embs_train = ds["train"].map(embed_text, batched=True, batch_size=16)
embs_valid = ds["valid"].map(embed_text, batched=True, batch_size=16)
embs_test = ds["test"].map(embed_text, batched=True, batch_size=16)
现在我们已经有了所有的嵌入,我们需要建立一个系统来搜索它们。我们可以编写一个函数,计算我们将查询的新文本嵌入与训练集中现有嵌入之间的余弦相似度。或者,我们可以使用数据集中的内置结构,称为FAISS 索引。⁵我们在第七章中已经遇到了 FAISS。您可以将其视为嵌入的搜索引擎,我们将在一分钟内更仔细地看看它是如何工作的。我们可以使用数据集的现有字段创建一个 FAISS 索引,使用add_faiss_index(),或者使用add_faiss_index_from_external_arrays()将新的嵌入加载到数据集中。让我们使用前一个函数将我们的训练嵌入添加到数据集中:
embs_train.add_faiss_index("embedding")
这创建了一个名为embedding的新 FAISS 索引。现在我们可以通过调用函数get_nearest_examples()执行最近邻查找。它返回最接近的邻居以及每个邻居的匹配分数。我们需要指定查询嵌入以及要检索的最近邻居的数量。让我们试一试,看看与示例最接近的文档:
i, k = 0, 3 # Select the first query and 3 nearest neighbors
rn, nl = "\r\n\r\n", "\n" # Used to remove newlines in text for compact display
query = np.array(embs_valid[i]["embedding"], dtype=np.float32)
scores, samples = embs_train.get_nearest_examples("embedding", query, k=k)
print(f"QUERY LABELS: {embs_valid[i]['labels']}")
print(f"QUERY TEXT:\n{embs_valid[i]['text'][:200].replace(rn, nl)} [...]\n")
print("="*50)
print(f"Retrieved documents:")
for score, label, text in zip(scores, samples["labels"], samples["text"]):
print("="*50)
print(f"TEXT:\n{text[:200].replace(rn, nl)} [...]")
print(f"SCORE: {score:.2f}")
print(f"LABELS: {label}")
QUERY LABELS: ['new model']
QUERY TEXT:
Implementing efficient self attention in T5
# New model addition
My teammates and I (including @ice-americano) would like to use efficient self
attention methods such as Linformer, Performer and [...]
==================================================
Retrieved documents:
==================================================
TEXT:
Add Linformer model
# New model addition
## Model description
### Linformer: Self-Attention with Linear Complexity
Paper published June 9th on ArXiv: https://arxiv.org/abs/2006.04768
La [...]
SCORE: 54.92
LABELS: ['new model']
==================================================
TEXT:
Add FAVOR+ / Performer attention
# FAVOR+ / Performer attention addition
Are there any plans to add this new attention approximation block to
Transformers library?
## Model description
The n [...]
SCORE: 57.90
LABELS: ['new model']
==================================================
TEXT:
Implement DeLighT: Very Deep and Light-weight Transformers
# New model addition
## Model description
DeLight, that delivers similar or better performance than transformer-based
models with sign [...]
SCORE: 60.12
LABELS: ['new model']
很好!这正是我们所希望的:通过嵌入查找得到的三个文档都具有相同的标签,我们已经可以从标题中看出它们都非常相似。查询以及检索到的文档都围绕着添加新的高效 Transformer 模型。然而,问题仍然存在,k的最佳值是多少?同样,我们应该如何聚合检索到的文档的标签?例如,我们应该检索三个文档,并分配至少出现两次的所有标签吗?还是应该选择 20 个,并使用至少出现 5 次的所有标签?让我们系统地调查一下:我们将尝试几个k的值,然后使用一个辅助函数改变标签分配的阈值m < k。我们将记录每个设置的宏和微性能,以便稍后决定哪个运行效果最好。我们可以使用get_nearest_examples_batch()函数,而不是循环遍历验证集中的每个样本,它接受一个查询的批处理:
def get_sample_preds(sample, m):
return (np.sum(sample["label_ids"], axis=0) >= m).astype(int)
def find_best_k_m(ds_train, valid_queries, valid_labels, max_k=17):
max_k = min(len(ds_train), max_k)
perf_micro = np.zeros((max_k, max_k))
perf_macro = np.zeros((max_k, max_k))
for k in range(1, max_k):
for m in range(1, k + 1):
_, samples = ds_train.get_nearest_examples_batch("embedding",
valid_queries, k=k)
y_pred = np.array([get_sample_preds(s, m) for s in samples])
clf_report = classification_report(valid_labels, y_pred,
target_names=mlb.classes_, zero_division=0, output_dict=True)
perf_micro[k, m] = clf_report["micro avg"]["f1-score"]
perf_macro[k, m] = clf_report["macro avg"]["f1-score"]
return perf_micro, perf_macro
让我们检查在所有训练样本中最佳的值,并可视化所有k和m配置的分数:
valid_labels = np.array(embs_valid["label_ids"])
valid_queries = np.array(embs_valid["embedding"], dtype=np.float32)
perf_micro, perf_macro = find_best_k_m(embs_train, valid_queries, valid_labels)
fig, (ax0, ax1) = plt.subplots(1, 2, figsize=(10, 3.5), sharey=True)
ax0.imshow(perf_micro)
ax1.imshow(perf_macro)
ax0.set_title("micro scores")
ax0.set_ylabel("k")
ax1.set_title("macro scores")
for ax in [ax0, ax1]:
ax.set_xlim([0.5, 17 - 0.5])
ax.set_ylim([17 - 0.5, 0.5])
ax.set_xlabel("m")
plt.show()

从图中我们可以看到有一个模式:对于给定的k选择太大或太小会产生次优结果。当选择大约为m / k = 1 / 3的比率时,可以获得最佳性能。让我们看看哪个k和m能够在整体上获得最佳结果:
k, m = np.unravel_index(perf_micro.argmax(), perf_micro.shape)
print(f"Best k: {k}, best m: {m}")
Best k: 15, best m: 5
当我们选择 k = 15 和 m = 5 时,性能最佳,换句话说,当我们检索 15 个最近的邻居,然后分配至少出现 5 次的标签。现在我们有了一个找到嵌入查找最佳值的好方法,我们可以像使用朴素贝叶斯分类器一样玩同样的游戏,我们遍历训练集的切片并评估性能。在我们可以切片数据集之前,我们需要删除索引,因为我们不能像数据集那样切片 FAISS 索引。其余的循环保持完全相同,另外使用验证集来获取最佳的k和m值:
embs_train.drop_index("embedding")
test_labels = np.array(embs_test["label_ids"])
test_queries = np.array(embs_test["embedding"], dtype=np.float32)
for train_slice in train_slices:
# Create a Faiss index from training slice
embs_train_tmp = embs_train.select(train_slice)
embs_train_tmp.add_faiss_index("embedding")
# Get best k, m values with validation set
perf_micro, _ = find_best_k_m(embs_train_tmp, valid_queries, valid_labels)
k, m = np.unravel_index(perf_micro.argmax(), perf_micro.shape)
# Get predictions on test set
_, samples = embs_train_tmp.get_nearest_examples_batch("embedding",
test_queries,
k=int(k))
y_pred = np.array([get_sample_preds(s, m) for s in samples])
# Evaluate predictions
clf_report = classification_report(test_labels, y_pred,
target_names=mlb.classes_, zero_division=0, output_dict=True,)
macro_scores["Embedding"].append(clf_report["macro avg"]["f1-score"])
micro_scores["Embedding"].append(clf_report["micro avg"]["f1-score"])
plot_metrics(micro_scores, macro_scores, train_samples, "Embedding")

嵌入查找在微分数上与先前的方法竞争,只有两个“可学习”参数k和m,但在宏分数上表现稍差。
请以一颗谷物的方式接受这些结果;哪种方法最有效强烈取决于领域。零-shot 管道的训练数据与我们正在使用的 GitHub 问题数据集有很大不同,其中包含模型可能之前很少遇到的大量代码。对于更常见的任务,例如对评论的情感分析,该管道可能效果更好。同样,嵌入的质量取决于模型和它训练的数据。我们尝试了半打模型,例如sentence-transformers/stsb-roberta-large,它经过训练以提供句子的高质量嵌入,以及microsoft/codebert-base和dbernsohn/roberta-python,它们是在代码和文档上进行训练的。对于这个特定的用例,GPT-2 在 Python 代码上的训练效果最好。
由于您实际上不需要在代码中更改任何内容,只需将模型检查点名称替换为测试另一个模型,一旦设置了评估管道,您可以快速尝试几个模型。
现在让我们将这个简单的嵌入技巧与简单地微调我们拥有的有限数据的 Transformer 进行比较。
微调一个普通的 Transformer
如果我们可以访问标记数据,我们也可以尝试做一件显而易见的事情:简单地微调预训练的 Transformer 模型。在本节中,我们将使用标准的 BERT 检查点作为起点。稍后,我们将看到微调语言模型对性能的影响。
提示
对于许多应用程序来说,从预训练的类似 BERT 的模型开始是一个好主意。但是,如果您的语料库领域与预训练语料库(通常是维基百科)有显著差异,您应该探索 Hugging Face Hub 上提供的许多模型。很可能已经有人在您的领域上预训练了一个模型!
让我们从加载预训练的标记器开始,对我们的数据集进行标记化,并摆脱我们在训练和评估中不需要的列:
import torch
from transformers import (AutoTokenizer, AutoConfig,
AutoModelForSequenceClassification)
model_ckpt = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
def tokenize(batch):
return tokenizer(batch["text"], truncation=True, max_length=128)
ds_enc = ds.map(tokenize, batched=True)
ds_enc = ds_enc.remove_columns(['labels', 'text'])
多标签损失函数期望标签的类型为浮点数,因为它还允许类概率而不是离散标签。因此,我们需要更改label_ids列的类型。由于逐元素更改列格式与 Arrow 的类型格式不兼容,我们将做一些变通。首先,我们创建一个带有标签的新列。该列的格式是从第一个元素推断出来的。然后,我们删除原始列,并将新列重命名为原始列的位置:
ds_enc.set_format("torch")
ds_enc = ds_enc.map(lambda x: {"label_ids_f": x["label_ids"].to(torch.float)},
remove_columns=["label_ids"])
ds_enc = ds_enc.rename_column("label_ids_f", "label_ids")
由于由于训练数据的有限大小,我们很可能会很快过度拟合训练数据,因此我们设置load_best_model_at_end=True并根据微观F[1]-score 选择最佳模型:
from transformers import Trainer, TrainingArguments
training_args_fine_tune = TrainingArguments(
output_dir="./results", num_train_epochs=20, learning_rate=3e-5,
lr_scheduler_type='constant', per_device_train_batch_size=4,
per_device_eval_batch_size=32, weight_decay=0.0,
evaluation_strategy="epoch", save_strategy="epoch",logging_strategy="epoch",
load_best_model_at_end=True, metric_for_best_model='micro f1',
save_total_limit=1, log_level='error')
我们需要F[1]-score 来选择最佳模型,因此我们需要确保在评估过程中计算它。因为模型返回 logits,所以我们首先需要使用 sigmoid 函数对预测进行归一化,然后可以使用简单的阈值对其进行二值化。然后我们从分类报告中返回我们感兴趣的分数:
from scipy.special import expit as sigmoid
def compute_metrics(pred):
y_true = pred.label_ids
y_pred = sigmoid(pred.predictions)
y_pred = (y_pred>0.5).astype(float)
clf_dict = classification_report(y_true, y_pred, target_names=all_labels,
zero_division=0, output_dict=True)
return {"micro f1": clf_dict["micro avg"]["f1-score"],
"macro f1": clf_dict["macro avg"]["f1-score"]}
现在我们准备好了!对于每个训练集切片,我们从头开始训练一个分类器,在训练循环结束时加载最佳模型,并将结果存储在测试集上:
config = AutoConfig.from_pretrained(model_ckpt)
config.num_labels = len(all_labels)
config.problem_type = "multi_label_classification"
for train_slice in train_slices:
model = AutoModelForSequenceClassification.from_pretrained(model_ckpt,
config=config)
trainer = Trainer(
model=model, tokenizer=tokenizer,
args=training_args_fine_tune,
compute_metrics=compute_metrics,
train_dataset=ds_enc["train"].select(train_slice),
eval_dataset=ds_enc["valid"],)
trainer.train()
pred = trainer.predict(ds_enc["test"])
metrics = compute_metrics(pred)
macro_scores["Fine-tune (vanilla)"].append(metrics["macro f1"])
micro_scores["Fine-tune (vanilla)"].append(metrics["micro f1"])
plot_metrics(micro_scores, macro_scores, train_samples, "Fine-tune (vanilla)")

首先,我们看到简单地在数据集上微调一个普通的 BERT 模型会在我们拥有大约 64 个示例时导致竞争力的结果。我们还看到在此之前,行为有点不稳定,这又是由于在小样本上训练模型时,一些标签可能不平衡。在利用数据集的未标记部分之前,让我们快速看一下在少样本领域使用语言模型的另一种有前途的方法。
使用提示进行上下文和少样本学习
我们在本章前面看到,我们可以使用 BERT 或 GPT-2 等语言模型,并使用提示和解析模型的标记预测来使其适应监督任务。这与添加特定任务头部并调整模型参数的经典方法不同。优点是,这种方法不需要任何训练数据,但缺点是,如果我们可以访问标记数据,似乎我们无法利用它。有一个中间地带,我们有时可以利用,称为in-context或少样本学习。
为了说明这个概念,考虑一个英语到法语的翻译任务。在零-shot 范式中,我们会构建一个提示,可能如下所示:
prompt = """\
Translate English to French:
thanks =>
"""
这有望促使模型预测单词“merci”的标记。我们已经在第六章中使用 GPT-2 进行摘要时看到,向文本中添加“TL;DR”提示模型生成摘要,而无需明确训练。GPT-3 论文的一个有趣发现是大型语言模型有效地从提示中学习示例的能力,因此,前面的翻译示例可以增加几个英语到德语的示例,这将使模型在这个任务上表现得更好。⁶
此外,作者发现,模型规模越大,它们越擅长使用上下文示例,从而显著提高性能。尽管 GPT-3 大小的模型在生产中具有挑战性,但这是一个令人兴奋的新兴研究领域,人们已经构建了一些很酷的应用,比如自然语言 shell,其中命令以自然语言输入,并由 GPT-3 解析为 shell 命令。
使用标记数据的另一种方法是创建提示和期望预测的示例,并继续在这些示例上训练语言模型。一种名为 ADAPET 的新方法使用了这种方法,并在各种任务上击败了 GPT-3,通过生成提示来调整模型。最近 Hugging Face 研究人员的工作表明,这种方法比微调自定义头部更节约数据。⁷
在本节中,我们简要地讨论了利用我们拥有的少量标记示例的各种方法。通常情况下,除了标记的示例,我们还可以访问大量未标记的数据;在下一节中,我们将讨论如何充分利用这些数据。
利用未标记的数据
尽管拥有大量高质量标记数据是训练分类器的最佳情况,但这并不意味着未标记数据毫无价值。想想我们使用的大多数模型的预训练:即使它们是在互联网上大多数不相关的数据上训练的,我们也可以利用预训练的权重来处理各种各样的文本上的其他任务。这是自然语言处理中迁移学习的核心思想。当下游任务的文本结构与预训练文本相似时,迁移效果更好,因此如果我们可以使预训练任务更接近下游目标,我们可能会改善迁移效果。
让我们从我们具体的用例来考虑这个问题:BERT 在 BookCorpus 和英文维基百科上进行了预训练,而包含代码和 GitHub 问题的文本在这些数据集中显然是一个小众。如果我们从头开始对 BERT 进行预训练,我们可以在 GitHub 上对所有问题进行爬取,例如。然而,这将是昂贵的,并且 BERT 学到的许多关于语言的方面仍然适用于 GitHub 问题。那么在从头开始重新训练和仅仅使用模型进行分类之间是否有一个中间地带?有,它被称为域自适应(我们在第七章中也看到了用于问答的域自适应)。我们可以在不从头开始重新训练语言模型的情况下,继续在我们领域的数据上训练它。在这一步中,我们使用预测掩码词的经典语言模型目标,这意味着我们不需要任何标记数据。之后,我们可以将适应后的模型加载为分类器并进行微调,从而利用未标记的数据。
域自适应的美妙之处在于,与标记数据相比,未标记数据通常是丰富可得的。此外,适应后的模型可以重复用于许多用例。想象一下,您想构建一个电子邮件分类器,并在所有历史电子邮件上应用域自适应。稍后您可以使用相同的模型进行命名实体识别或其他分类任务,比如情感分析,因为该方法对下游任务是不可知的。
现在让我们看看我们需要采取哪些步骤来微调预训练语言模型。
微调语言模型
在本节中,我们将对我们数据集的未标记部分进行预训练 BERT 模型的掩码语言建模进行微调。为此,我们只需要两个新概念:在对数据进行分词时需要额外的步骤和一个特殊的数据整理器。让我们从分词开始。
除了文本中的普通标记外,分词器还向序列添加特殊标记,例如 [CLS] 和 [SEP] 标记,用于分类和下一个句子预测。当我们进行掩码语言建模时,我们希望确保不训练模型来预测这些标记。出于这个原因,我们从损失中屏蔽它们,并且我们可以通过设置 return_special_tokens_mask=True 来在分词时获得掩码。让我们使用该设置重新对文本进行分词:
def tokenize(batch):
return tokenizer(batch["text"], truncation=True,
max_length=128, return_special_tokens_mask=True)
ds_mlm = ds.map(tokenize, batched=True)
ds_mlm = ds_mlm.remove_columns(["labels", "text", "label_ids"])
开始进行掩码语言建模所缺少的是在输入序列中屏蔽标记并在输出中有目标标记的机制。我们可以采用的一种方法是设置一个函数,对随机标记进行屏蔽并为这些序列创建标签。但这将使数据集的大小翻倍,因为我们还将在数据集中存储目标序列,并且这意味着我们将在每个时期使用相同的序列屏蔽。
一个更加优雅的解决方案是使用数据整理器。记住,数据整理器是构建数据集和模型调用之间的桥梁的函数。从数据集中抽取一个批次,并且数据整理器准备好批次中的元素以将它们馈送到模型中。在我们遇到的最简单的情况下,它只是将每个元素的张量连接成一个单一的张量。在我们的情况下,我们可以使用它来动态进行掩码和标签生成。这样我们就不需要存储标签,每次抽样时都会得到新的掩码。这个任务的数据整理器称为DataCollatorForLanguageModeling。我们使用模型的标记器和我们想要掩码的标记的分数来初始化它。我们将使用这个整理器来掩码 15%的标记,这遵循了 BERT 论文中的程序:
from transformers import DataCollatorForLanguageModeling, set_seed
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer,
mlm_probability=0.15)
让我们快速看一下数据整理器的操作,看看它实际上做了什么。为了快速在DataFrame中显示结果,我们将标记器和数据整理器的返回格式切换为 NumPy:
set_seed(3)
data_collator.return_tensors = "np"
inputs = tokenizer("Transformers are awesome!", return_tensors="np")
outputs = data_collator([{"input_ids": inputs["input_ids"][0]}])
pd.DataFrame({
"Original tokens": tokenizer.convert_ids_to_tokens(inputs["input_ids"][0]),
"Masked tokens": tokenizer.convert_ids_to_tokens(outputs["input_ids"][0]),
"Original input_ids": original_input_ids,
"Masked input_ids": masked_input_ids,
"Labels": outputs["labels"][0]}).T
| 0 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
| 原始标记 | [CLS] | transformers | are | awesome | ! | [SEP] |
| 掩码标记 | [CLS] | transformers | are | awesome | [MASK] | [SEP] |
| 原始 input_ids | 101 | 19081 | 2024 | 12476 | 999 | 102 |
| 掩码 input_ids | 101 | 19081 | 2024 | 12476 | 103 | 102 |
| 标签 | -100 | -100 | -100 | -100 | 999 | -100 |
我们看到与感叹号对应的标记已被替换为掩码标记。此外,数据整理器返回了一个标签数组,原始标记为-100,掩码标记的标记 ID。正如我们之前看到的,包含-100 的条目在计算损失时被忽略。让我们将数据整理器的格式切换回 PyTorch:
data_collator.return_tensors = "pt"
有了标记器和数据整理器,我们就可以开始微调掩码语言模型了。我们像往常一样设置TrainingArguments和Trainer:
from transformers import AutoModelForMaskedLM
training_args = TrainingArguments(
output_dir = f"{model_ckpt}-issues-128", per_device_train_batch_size=32,
logging_strategy="epoch", evaluation_strategy="epoch", save_strategy="no",
num_train_epochs=16, push_to_hub=True, log_level="error", report_to="none")
trainer = Trainer(
model=AutoModelForMaskedLM.from_pretrained("bert-base-uncased"),
tokenizer=tokenizer, args=training_args, data_collator=data_collator,
train_dataset=ds_mlm["unsup"], eval_dataset=ds_mlm["train"])
trainer.train()
trainer.push_to_hub("Training complete!")
我们可以访问训练器的日志历史记录,查看模型的训练和验证损失。所有日志都存储在trainer.state.log_history中,作为一个字典列表,我们可以轻松地加载到 Pandas 的DataFrame中。由于训练和验证损失记录在不同的步骤,数据框中存在缺失值。因此我们在绘制指标之前删除缺失值:
df_log = pd.DataFrame(trainer.state.log_history)
(df_log.dropna(subset=["eval_loss"]).reset_index()["eval_loss"]
.plot(label="Validation"))
df_log.dropna(subset=["loss"]).reset_index()["loss"].plot(label="Train")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend(loc="upper right")
plt.show()

似乎训练和验证损失都显著下降了。所以让我们看看当我们基于这个模型微调分类器时是否也能看到改进。
微调分类器
现在我们将重复微调过程,但有一个细微的不同,即加载我们自己的自定义检查点:
model_ckpt = f'{model_ckpt}-issues-128'
config = AutoConfig.from_pretrained(model_ckpt)
config.num_labels = len(all_labels)
config.problem_type = "multi_label_classification"
for train_slice in train_slices:
model = AutoModelForSequenceClassification.from_pretrained(model_ckpt,
config=config)
trainer = Trainer(
model=model,
tokenizer=tokenizer,
args=training_args_fine_tune,
compute_metrics=compute_metrics,
train_dataset=ds_enc["train"].select(train_slice),
eval_dataset=ds_enc["valid"],
)
trainer.train()
pred = trainer.predict(ds_enc['test'])
metrics = compute_metrics(pred)
# DA refers to domain adaptation
macro_scores['Fine-tune (DA)'].append(metrics['macro f1'])
micro_scores['Fine-tune (DA)'].append(metrics['micro f1'])
将结果与基于 vanilla BERT 的微调进行比较,我们发现在低数据领域特别是有优势。在更多标记数据可用的情况下,我们也获得了几个百分点的优势:
plot_metrics(micro_scores, macro_scores, train_samples, "Fine-tune (DA)")

这突显了领域适应可以在没有标记数据和很少努力的情况下提供模型性能的轻微提升。自然地,未标记数据越多,标记数据越少,使用这种方法会产生更大的影响。在结束本章之前,我们将向您展示一些利用未标记数据的更多技巧。
高级方法
在微调分类头之前微调语言模型是一种简单而可靠的提升性能的方法。然而,还有更复杂的方法可以进一步利用未标记数据。我们在这里总结了一些这些方法,如果您需要更高性能,这些方法应该提供一个很好的起点。
无监督数据增强
无监督数据增强(UDA)背后的关键思想是,模型对未标记的示例和略微扭曲的示例应该保持一致。这些扭曲是通过标准的数据增强策略引入的,例如标记替换和回译。然后通过最小化原始和扭曲示例的预测之间的 KL 散度来强制执行一致性。这个过程在图 9-5 中有所说明,其中一致性要求通过从未标记的示例中增加交叉熵损失的额外项来实现。这意味着使用标准监督方法在标记数据上训练模型,但约束模型对未标记数据进行一致的预测。

图 9-5. 使用 UDA 训练模型 M(由 Qizhe Xie 提供)
这种方法的性能相当令人印象深刻:使用 UDA 训练的 BERT 模型在有限数量的示例上获得了与数千个示例训练的模型相似的性能。缺点是您需要一个数据增强管道,并且训练时间更长,因为您需要多次前向传递来生成未标记和增强示例的预测分布。
不确定性感知的自我训练
利用未标记数据的另一种有前途的方法是不确定性感知的自我训练(UST)。这里的想法是在标记数据上训练一个教师模型,然后使用该模型在未标记数据上创建伪标签。然后在伪标记数据上训练一个学生,训练后它成为下一次迭代的教师。
这种方法的一个有趣之处在于伪标签的生成方式:为了获得模型预测的不确定性度量,相同的输入通过模型多次,同时打开辍学。然后预测的方差给出了模型对特定样本的确定性的代理。有了这种不确定性度量,然后使用一种称为贝叶斯主动学习的方法来采样伪标签。完整的训练管道在图 9-6 中有所说明。

图 9-6. UST 方法包括一个生成伪标签的教师和随后在这些标签上进行训练的学生;学生训练后成为教师,然后重复这个步骤(由 Subhabrata Mukherjee 提供)⁹
通过这种迭代方案,教师不断改进创建伪标签的能力,因此模型的性能得到了提高。最终,这种方法在几个百分点内接近使用数千个样本进行全面训练的模型,并且在几个数据集上甚至超过了 UDA。
现在我们已经看到了一些先进的方法,让我们退一步,总结一下我们在本章学到的内容。
结论
在本章中,我们看到即使只有少量甚至没有标签,也不是所有的希望都已经失去。我们可以利用已经在其他任务上预训练的模型,比如 BERT 语言模型或在 Python 代码上训练的 GPT-2,来对 GitHub 问题分类的新任务进行预测。此外,我们可以使用领域自适应在使用普通分类头训练模型时获得额外的提升。
在特定用例上,所提出的方法中哪种方法最有效取决于各种方面:您拥有多少标记数据,它有多嘈杂,数据与预训练语料库有多接近等等。要找出最有效的方法,建立评估管道然后快速迭代是一个好主意。 Transformers 的灵活 API 允许您快速加载一些模型并进行比较,而无需进行任何代码更改。Hugging Face Hub 上有超过 10,000 个模型,很可能有人过去曾经处理过类似的问题,您可以在此基础上构建。
Transformers 的灵活 API 允许您快速加载一些模型并进行比较,而无需进行任何代码更改。Hugging Face Hub 上有超过 10,000 个模型,很可能有人过去曾经处理过类似的问题,您可以在此基础上构建。
这本书超出了 UDA 或 UST 等更复杂方法与获取更多数据之间的权衡范围。为了评估你的方法,至少在早期建立验证和测试集是有意义的。在每一步,你也可以收集更多的标记数据。通常标注几百个例子只需要几个小时或几天的工作,而且有许多工具可以帮助你做到这一点。根据你想要实现的目标,投入一些时间创建一个小而高质量的数据集可能比设计一个非常复杂的方法来弥补其不足更有意义。通过本章中我们提出的方法,你可以确保充分利用你宝贵的标记数据。
在这里,我们已经涉足了低数据范畴,并且看到 Transformer 模型即使只有一百个例子,仍然非常强大。在下一章中,我们将看到完全相反的情况:当我们有数百吉字节的数据和大量计算资源时,我们将会做些什么。我们将从头开始训练一个大型的 Transformer 模型,让它为我们自动完成代码。
¹ Q. Xie et al., “Unsupervised Data Augmentation for Consistency Training”, (2019); S. Mukherjee and A.H. Awadallah, “Uncertainty-Aware Self-Training for Few-Shot Text Classification”, (2020).
² 我们感谢Joe Davison向我们提出了这种方法。
³ A. Williams, N. Nangia, and S.R. Bowman, “A Broad-Coverage Challenge Corpus for Sentence Understanding Through Inference”, (2018); A. Conneau et al., “XNLI: Evaluating Cross-Lingual Sentence Representations”, (2018).
⁴ J. Wei and K. Zou, “EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks”, (2019).
⁵ J. Johnson, M. Douze, and H. Jégou, “Billion-Scale Similarity Search with GPUs”, (2017).
⁶ T. Brown et al., “Language Models Are Few-Shot Learners”, (2020).
⁷ D. Tam et al., “Improving and Simplifying Pattern Exploiting Training”, (2021).
⁸ T. Le Scao and A.M. Rush, “How Many Data Points Is a Prompt Worth?”, (2021).
⁹ S. Mukherjee and A.H. Awadallah, “Uncertainty-Aware Self-Training for Few-Shot Text Classification”, (2020).

尧米是由西云算力与CSDN联合运营的AI算力和模型开源社区品牌,为基于DaModel智算平台的AI应用企业和泛AI开发者提供技术交流与成果转化平台。
更多推荐

 20
20 0
0- 0



 已为社区贡献51条内容
已为社区贡献51条内容

所有评论(0)