丹摩|丹摩智算平台评测与使用体验
对于有高性能计算需求,特别是在深度学习和人工智能领域的用户来说,如果能够合理利用平台的资源和功能,并且在成本方面做好规划,丹摩智算平台是一个可以考虑的选择。2.用户反馈渠道:虽然有一定的技术支持,但用户反馈问题或者提出建议的渠道相对单一,希望能够增加更多的反馈入口,例如用户论坛或者在线问卷调查等方式,以便更好地收集用户的意见和建议。1.资源灵活性:提供多种高性能的GPU资源供用户选择,并且可以根据
一、平台初印象
丹摩智算平台作为一款云端高性能计算解决方案,在进入平台时就给人一种简洁而专业的感觉。其界面布局较为清晰,对于初次使用者来说,各个功能模块的入口比较容易找到。
二、使用流程体验
1. 注册与登录
注册过程相对顺利,只需要提供基本的信息如邮箱、设置密码等常规操作即可完成注册。登录时,账号密码的验证也没有出现卡顿或异常情况。
2. 实例创建
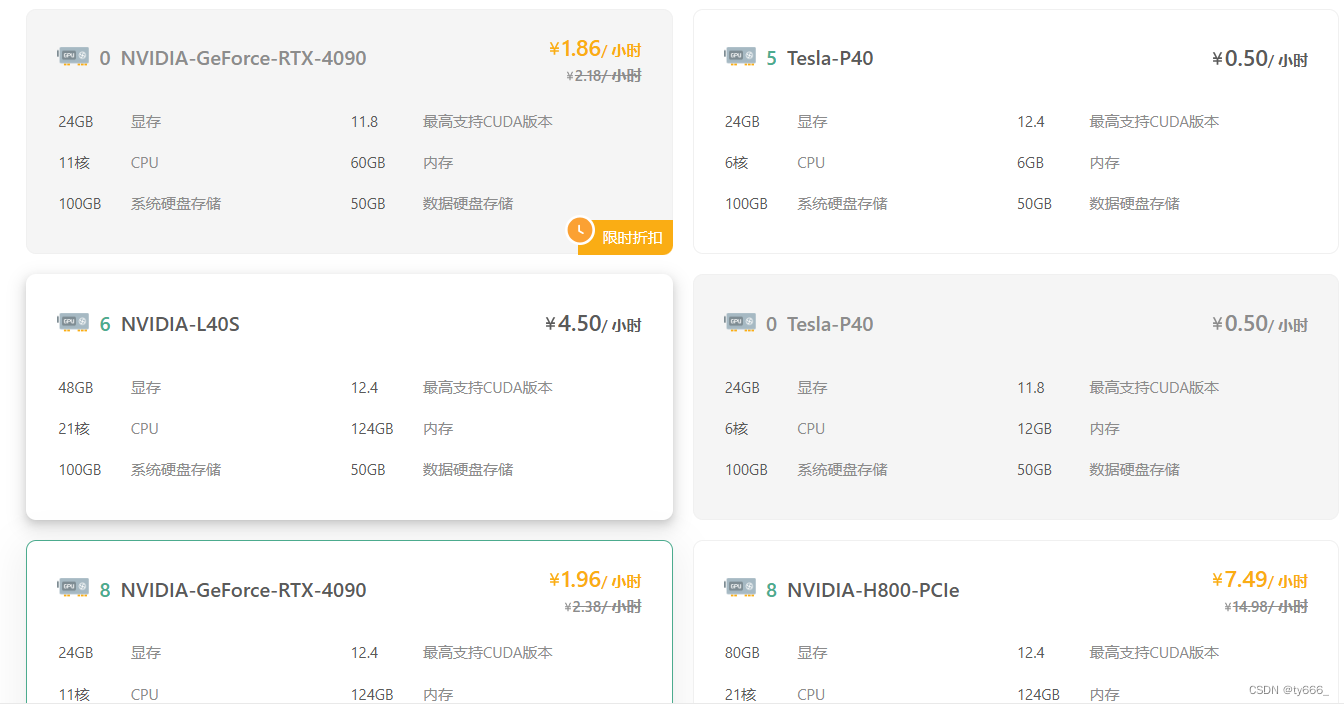
1.在创建实例方面,平台提供了丰富的GPU资源选择。例如,当我尝试创建一个用于深度学习任务的实例时,我可以根据自己的预算和任务需求轻松选择合适的GPU型号和数量。
2.以创建一个基于TensorFlow框架运行图像分类任务的实例为例,以下是一个简单的Python代码片段,用于在丹摩智算平台上初始化一个TensorFlow会话(假设相关的库已经安装在平台环境中):
import tensorflow as tf
# 创建一个TensorFlow会话
sess = tf.Session()
# 这里可以添加更多关于图像分类任务的代码,比如加载模型、数据集等
# 例如加载MNIST数据集
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test) = mnist.load_data()
# 简单展示数据形状
print('x_train shape:', x_train.shape)
print('y_train shape:', y_train.shape)
print('x_test shape:', x_test.shape)
print('y_test shape:', y_test.shape)
1.在创建实例过程中,选择付费类型、数据硬盘大小等操作逻辑清晰。我可以根据任务的规模预估所需的数据存储空间,然后进行相应的配置。
3. 数据上传与管理
1.平台的数据上传功能比较直观。我可以将本地的数据集上传到平台指定的存储空间。不过,在上传较大数据集时,希望能够有更详细的进度提示。
2.假设我们有一个本地的CSV格式的数据集文件,想要上传到丹摩智算平台。以下是一个使用Python的paramiko库通过SSH连接到平台并上传文件的示例代码(这里假设平台支持SSH连接上传,实际情况可能需要根据平台的具体接口进行调整):
import paramiko
def upload_file(local_file_path, remote_file_path):
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
# 这里需要替换为丹摩智算平台的主机地址、用户名和密码
ssh.connect(hostname='your_damo_host', username='your_username', password='your_password')
sftp = ssh.open_sftp()
sftp.put(local_file_path, remote_file_path)
sftp.close()
ssh.close()
local_file = 'your_local_dataset.csv'
remote_file = '/path/on/damo_platform/your_remote_dataset.csv'
upload_file(local_file, remote_file)
4. 内置JupyterLab的使用
1.成功创建实例后,通过控制台提供的链接进入JupyterLab非常方便。在JupyterLab中,我可以像在本地环境一样进行代码的编写和调试。
2.例如,我在JupyterLab中继续进行之前提到的图像分类任务的开发。以下是一个简单的在JupyterLab中构建一个简单的卷积神经网络(CNN)用于图像分类的代码示例:
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
# 加载MNIST数据集
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()
# 对数据进行归一化
train_images, test_images = train_images / 255.0, test_images / 255.0
# 重塑数据形状以适应CNN输入
train_images = train_images.reshape((-1, 28, 28, 1))
test_images = test_images.reshape((-1, 28, 28, 1))
# 构建模型
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
# 编译模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
history = model.fit(train_images, train_labels, epochs=5,
validation_data=(test_images, test_labels))
1.JupyterLab的界面交互性很好,文件资源管理器方便我管理项目中的文件,并且代码的运行结果能够及时显示在控制台中。
5. 本地连接方法
1.平台提供了多种本地连接方法,如SSH等。在通过SSH连接时,获取实例的SSH访问信息比较便捷。
2.以下是一个简单的通过命令行使用SSH连接到丹摩智算平台实例的示例(这里同样需要替换为实际的主机地址、端口号、用户名和私钥路径等信息):
ssh -i /path/to/your/private/key -p your_port_number your_username@your_damo_host
三、性能表现
1. 计算资源
1.丹摩智算平台的GPU资源确实能够满足不同规模的计算需求。在运行一些深度学习任务时,例如上述的图像分类模型训练,高端的GPU型号能够显著缩短训练时间。
2.以训练一个中等规模的卷积神经网络为例,使用平台提供的较高级别的GPU,与在本地普通硬件环境下相比,训练速度提升了数倍。这对于需要快速迭代模型的研究人员来说非常有价值。
2. 稳定性
1.在长时间的任务运行过程中,平台表现出了较好的稳定性。没有出现无故中断或性能突然下降的情况。不过,在平台负载较高时,可能会有轻微的响应延迟,但整体不影响任务的正常进行。
四、平台优势与不足
1. 平台优势
1.资源灵活性:提供多种高性能的GPU资源供用户选择,并且可以根据自己的需求灵活租赁,无需购买昂贵的硬件设备,这对于小型研究团队或者个人开发者来说是非常大的优势。
2.功能完整性:从实例创建、数据管理到模型开发和运行,整个流程在平台上都能够得到较好的支持。
3.技术支持:平台提供了较为详细的文档和一定程度的技术支持,当遇到问题时,用户可以通过文档或者联系客服来获取帮助。
2. 不足之处
1.成本效益:对于一些预算有限的用户来说,尽管租赁模式比较灵活,但长期使用成本可能仍然较高。希望平台能够推出更多针对不同用户群体的优惠套餐或者计费方式。
2.用户反馈渠道:虽然有一定的技术支持,但用户反馈问题或者提出建议的渠道相对单一,希望能够增加更多的反馈入口,例如用户论坛或者在线问卷调查等方式,以便更好地收集用户的意见和建议。
五、综合评价
丹摩智算平台在高性能计算领域具有一定的竞争力,其在资源提供、功能支持和稳定性方面表现良好。然而,在成本效益和用户反馈方面还有一定的提升空间。对于有高性能计算需求,特别是在深度学习和人工智能领域的用户来说,如果能够合理利用平台的资源和功能,并且在成本方面做好规划,丹摩智算平台是一个可以考虑的选择。

尧米是由西云算力与CSDN联合运营的AI算力和模型开源社区品牌,为基于DaModel智算平台的AI应用企业和泛AI开发者提供技术交流与成果转化平台。
更多推荐



 9
9 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)