Ollama与Fastgpt打造本地RAG知识库(附教程)
FastGPT则是一个基于大型语言模型的知识库问答系统,提供数据处理、模型调用等能力。本文将指导你如何结合这两个工具,搭建一个功能强大的本地知识库。
简介
在当今数据驱动的时代,拥有一个能够理解和处理大量信息的个人知识库是极其有价值的。Ollama和FastGPT是两个开源项目,可以帮助我们实现这一目标。Ollama是一个轻量级、可扩展的框架,用于在本地机器上构建和运行大型语言模型。FastGPT则是一个基于大型语言模型的知识库问答系统,提供数据处理、模型调用等能力。本文将指导你如何结合这两个工具,搭建一个功能强大的本地知识库。
Ollama简介
Ollama提供了一个简单的API,用于创建、运行和管理模型,同时提供了一系列预构建的模型,可以轻松地在各种应用程序中使用。Ollama支持多种模型,包括Llama 2、Mistral、Gemma等,并提供了一个模型库,用户可以从中下载所需的模型7。Ollama还支持模型的自定义和提示词的设置,允许用户根据自己的需求调整模型的行为7。
FastGPT简介
FastGPT是一个基于大型语言模型的知识库问答系统,它不仅提供开箱即用的数据处理和模型调用能力,还通过Flow可视化进行工作流编排,实现复杂的问答场景。FastGPT支持多种文件类型的导入,能够将ChatGPT训练成某个领域的专家,并且可以接入第三方GPT套壳应用,提供对外的API4。
Ollama本地安装指南
Windows系统安装Ollama
-
下载安装程序:访问Ollama Windows Preview页面,下载OllamaSetup.exe安装程序。
-
安装Ollama:双击OllamaSetup.exe文件,点击“Install”开始安装过程。
-
启动Ollama:安装完成后,通过“开始”菜单找到并点击Ollama图标运行程序。运行后,Ollama图标会驻留在任务栏托盘中。
-
获取模型:右键点击任务栏图标,选择“View log”打开命令行窗口。在命令行窗口中执行
ollama run [modelname]命令来运行Ollama,并加载指定的模型。例如,要运行Llama 2模型,可以使用命令ollama run llama2。
macOS和Linux系统安装Ollama
-
macOS安装:对于macOS用户,访问Ollama的官方网站或GitHub页面下载最新版本。下载后,解压zip文件,并按照包内的说明完成安装。
-
Linux安装:Linux用户可以通过命令行安装Ollama。打开终端,输入以下命令来自动下载和安装Ollama:```
curl -fsSL https://ollama.com/install.sh | sh -
运行模型:安装完成后,在终端中输入
ollama run [modelname]命令来运行一个模型,例如Llama 2。
Docker安装Ollama
-
拉取Docker镜像:对于熟悉Docker的用户,可以通过以下命令拉取Ollama的官方Docker镜像:```
docker pull ollama/ollama -
运行容器:使用
docker run命令来运行Ollama容器。具体的命令和参数设置可以参考Ollama的官方文档。
FastGPT本地安装指南
环境准备
-
安装Docker:访问Docker官方网站下载并安装适合您操作系统的Docker版本。
-
安装Docker Compose:通过Docker官方网站或相应文档安装Docker Compose工具。
部署FastGPT
-
创建目录:在您的计算机上创建一个新的目录用于存放FastGPT的配置文件。
-
下载配置文件:使用curl命令下载
docker-compose.yml和config.json配置文件到您创建的目录中。```
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/files/deploy/fastgpt/docker-compose.yml curl -O https://raw.githubusercontent.com/labring/FastGPT/main/projects/app/data/config.json -
启动FastGPT容器:在包含
docker-compose.yml的目录下,执行以下命令启动FastGPT容器:```
docker-compose pull docker-compose up -d -
访问FastGPT:通过
http://localhost:3000访问FastGPT的Web界面。默认的登录用户名为root,密码可以在docker-compose.yml文件中设置的环境变量DEFAULT_ROOT_PSW中找到。
配置FastGPT
-
编辑配置文件:根据需要编辑
config.json文件,可以设置数据库连接、API密钥、模型配置等。参照官方示例添加自己的模型 -
修改环境变量:在
docker-compose.yml文件中,可以根据需要修改环境变量,如OPENAI_BASE_URL和CHAT_API_KEY。默认不需要改动。
部署OneAPI
-
部署OneAPI:最新的Fastgpt docker compose文件已经加上了oneapi的部署
-
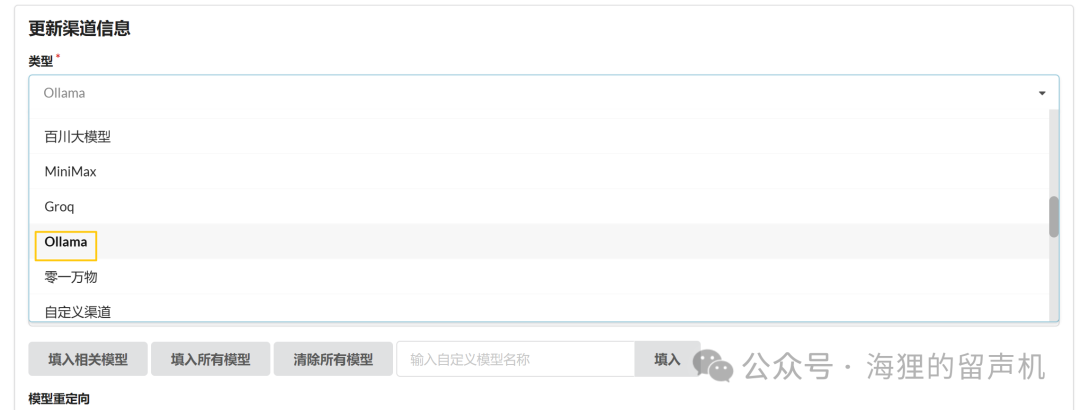
添加模型:在OneAPI中添加合适的AI模型渠道,以便FastGPT可以使用这些模型。oneapi支持ollama模型的添加:
部署m3e embedding模型
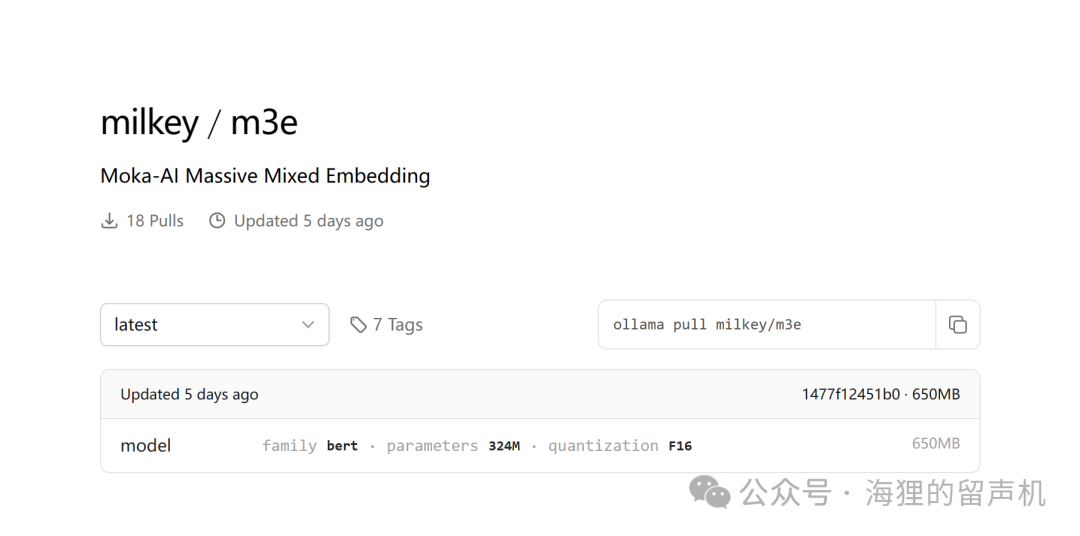
Fastgpt官方提供了m3e的docker部署镜像,但我觉得下载的东西太多了。并且ollama也是支持m3e模型的部署的,不过需要自己量化。ollama官方也有好心人上传了m3e的f16量化版本(milkey/m3e)
 如果是自己来量化的话,需要拉取ollama(或llama.cpp)和m3e_large的源,安装依赖:
如果是自己来量化的话,需要拉取ollama(或llama.cpp)和m3e_large的源,安装依赖:
 选择第一个hf-to-gguf就好了,然后通过以下命令进行转化
选择第一个hf-to-gguf就好了,然后通过以下命令进行转化
python llm/llama.cpp/convert-hf-to-gguf.py ./m3e-large --outtype f32 --outfile m3e_text_embeding.gguf
然后根据ollama官方的Modelfile教程把转化好的文件创建模型就好了,但FastGPT使用的m3e镜像有了一些别的处理,直接用ollama的会有一些功能不支持,比如说那个向量检索的相关度就不在0-1之间。
# 计算嵌入向量和tokens数量 embeddings = [m3e_model(text) for text in request.input] # 如果嵌入向量的维度不为1536,则使用插值法扩展至1536维度 # embeddings = [interpolate_vector(embedding, 1536) if len(embedding) < 1536 else embedding for embedding in embeddings] # 如果嵌入向量的维度不为1536,则使用特征扩展法扩展至1536维度 embeddings = [expand_features(embedding, 1536) if len(embedding) < 1536 else embedding for embedding in embeddings] # Min-Max normalization # embeddings = [(embedding - np.min(embedding)) / (np.max(embedding) - np.min(embedding)) if np.max(embedding) != np.min(embedding) else embedding for embedding in embeddings] embeddings = [embedding / np.linalg.norm(embedding) for embedding in embeddings] # 将numpy数组转换为列表 embeddings = [embedding.tolist() for embedding in embeddings] prompt_tokens = sum(len(text.split()) for text in request.input) total_tokens = sum(num_tokens_from_string(text) for text in request.input) response = { "data": [ { "embedding": embedding, "index": index, "object": "embedding" } for index, embedding in enumerate(embeddings) ], "model": request.model, "object": "list", "usage": { "prompt_tokens": prompt_tokens, "total_tokens": total_tokens, } } return response
可以看出,FastGPT提供的m3e对响应值有一层封装,我们可以稍微改动一下这个文件,m3e_model这个函数是我自己写的,这个函数直接向ollama发出embedding请求,然后在处理后返回给fastgpt。函数是这样的:
ollama_embed_model = os.environ.get("OLLAMA_EMBED_MODEL","nomic-embed-text") ollama_url = os.environ.get("OLLAMA_URL","http://host.docker.internal:11434") def m3e_model(text): resp = requests.post(f"{ollama_url}/api/embeddings",json={ "model":ollama_embed_model, "prompt":text }) if resp.status_code != 200: raise HTTPException( status_code=status.HTTP_500_INTERNAL_SERVER_ERROR, detail="connect m3e error", ) return np.array(resp.json()['embedding'])
这里的ollama_embed_model通过环境变量获取,ollama的url也如此。完整的代码如下:
from fastapi import FastAPI, Depends, HTTPException, status from fastapi.security import HTTPBearer, HTTPAuthorizationCredentials from pydantic import BaseModel from fastapi.middleware.cors import CORSMiddleware import requests import uvicorn import tiktoken import numpy as np from scipy.interpolate import interp1d from typing import List from sklearn.preprocessing import PolynomialFeatures import os #环境变量传入 sk_key = os.environ.get('SK-KEY', 'sk-aaabbbcccdddeeefffggghhhiiijjjkkk') ollama_url = os.environ.get("OLLAMA_URL","http://host.docker.internal:11434") ollama_embed_model = os.environ.get("OLLAMA_EMBED_MODEL","nomic-embed-text") print(f"SK-KEY:\t{sk_key}") print(f"OLLAMA_URL:\t{ollama_url}") print(f"OLLAMA_EMBED_MODEL:\t{ollama_embed_model}") # 创建一个FastAPI实例 app = FastAPI() app.add_middleware( CORSMiddleware, allow_origins=["*"], allow_credentials=True, allow_methods=["*"], allow_headers=["*"], ) # 创建一个HTTPBearer实例 security = HTTPBearer() class EmbeddingRequest(BaseModel): input: List[str] model: str class EmbeddingResponse(BaseModel): data: list model: str object: str usage: dict def num_tokens_from_string(string: str) -> int: """Returns the number of tokens in a text string.""" encoding = tiktoken.get_encoding('cl100k_base') num_tokens = len(encoding.encode(string)) return num_tokens # 插值法 def interpolate_vector(vector, target_length): original_indices = np.arange(len(vector)) target_indices = np.linspace(0, len(vector)-1, target_length) f = interp1d(original_indices, vector, kind='linear') return f(target_indices) def expand_features(embedding, target_length): poly = PolynomialFeatures(degree=2) expanded_embedding = poly.fit_transform(embedding.reshape(1, -1)) expanded_embedding = expanded_embedding.flatten() if len(expanded_embedding) > target_length: # 如果扩展后的特征超过目标长度,可以通过截断或其他方法来减少维度 expanded_embedding = expanded_embedding[:target_length] elif len(expanded_embedding) < target_length: # 如果扩展后的特征少于目标长度,可以通过填充或其他方法来增加维度 expanded_embedding = np.pad(expanded_embedding, (0, target_length - len(expanded_embedding))) return expanded_embedding def m3e_model(text): resp = requests.post(f"{ollama_url}/api/embeddings",json={ "model":ollama_embed_model, "prompt":text }) if resp.status_code != 200: raise HTTPException( status_code=status.HTTP_500_INTERNAL_SERVER_ERROR, detail="connect m3e error", ) return np.array(resp.json()['embedding']) @app.post("/v1/embeddings", response_model=EmbeddingResponse) async def get_embeddings(request: EmbeddingRequest, credentials: HTTPAuthorizationCredentials = Depends(security)): if credentials.credentials != sk_key: raise HTTPException( status_code=status.HTTP_401_UNAUTHORIZED, detail="Invalid authorization code", ) # 计算嵌入向量和tokens数量 embeddings = [m3e_model(text) for text in request.input] # 如果嵌入向量的维度不为1536,则使用插值法扩展至1536维度 # embeddings = [interpolate_vector(embedding, 1536) if len(embedding) < 1536 else embedding for embedding in embeddings] # 如果嵌入向量的维度不为1536,则使用特征扩展法扩展至1536维度 embeddings = [expand_features(embedding, 1536) if len(embedding) < 1536 else embedding for embedding in embeddings] # Min-Max normalization # embeddings = [(embedding - np.min(embedding)) / (np.max(embedding) - np.min(embedding)) if np.max(embedding) != np.min(embedding) else embedding for embedding in embeddings] embeddings = [embedding / np.linalg.norm(embedding) for embedding in embeddings] # 将numpy数组转换为列表 embeddings = [embedding.tolist() for embedding in embeddings] prompt_tokens = sum(len(text.split()) for text in request.input) total_tokens = sum(num_tokens_from_string(text) for text in request.input) response = { "data": [ { "embedding": embedding, "index": index, "object": "embedding" } for index, embedding in enumerate(embeddings) ], "model": request.model, "object": "list", "usage": { "prompt_tokens": prompt_tokens, "total_tokens": total_tokens, } } return response if __name__ == "__main__": uvicorn.run("localembedding:app", host='0.0.0.0', port=6008, workers=1)
需要的依赖库requirements.txt:
fastapi==0.99.1 pydantic==1.10.7 uvicorn==0.23.1 tiktoken==0.4.0 numpy==1.24.4 scipy==1.10.1 scikit-learn==1.3.0
然后通过Dockerfile创建一个容器docker build -t="denislov/fastgpt-ollama-embed:main" . :
# 使用官方Python运行时作为父镜像 FROM python:3.8-slim-buster # 设置工作目录 WORKDIR /app # 将当前目录内容复制到容器的/app中 ADD . /app RUN pip install --upgrade pip -i https://pypi.tuna.tsinghua.edu.cn/simple # 安装程序需要的包 RUN pip install --no-cache-dir -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple # 运行时监听的端口 EXPOSE 6008 # 运行app.py时的命令及其参数 CMD ["uvicorn", "localembedding:app", "--host", "0.0.0.0", "--port", "6008"]
最后,在fastgpt的docker-compose文件中加入我们的fastgpt-ollama-embed
ollama_embed: image: denislov/fastgpt-ollama-embed:main container_name: ollama_embed ports: - 6008:6008 networks: - fastgpt extra_hosts: - "host.docker.internal:host-gateway" environment: - OLLAMA_EMBED_MODEL=m3e
因为ollama是在宿主机端口,所以要加extra_hosts。然后重新启动fastgpt就可以了。m3e在oneapi中的添加参考fastgpt的官方接入 M3E 向量模型
注意事项
-
确保在启动容器时,
docker-compose.yml文件中的版本与您的Docker版本兼容。 -
如果需要使用域名访问FastGPT,需要自行安装并配置Nginx。
-
在首次运行时,FastGPT会自动初始化root用户,密码与
DEFAULT_ROOT_PSW一致。 -
如果遇到MongoServerError,可以忽略,或者按照官方文档手动初始化MongoDB副本集。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

尧米是由西云算力与CSDN联合运营的AI算力和模型开源社区品牌,为基于DaModel智算平台的AI应用企业和泛AI开发者提供技术交流与成果转化平台。
更多推荐



 19
19 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)